







(一)数据的基本查询
1)查询过程与基本原理
-
查询与响应过程
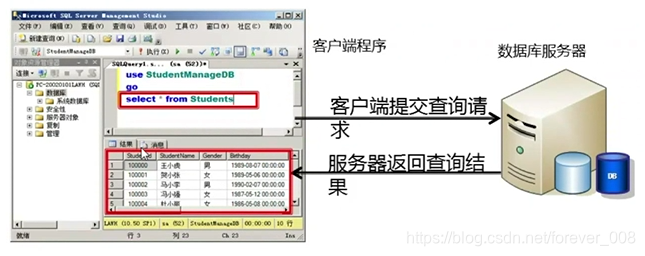
-
理解查询
- 服务器执行命令,在原始数据表中查找符合条件的数据,产生一个虚拟表;
- 虚拟表是数据组合后的重新展示,而不是原始的物理数据;
-
简单查询过程:
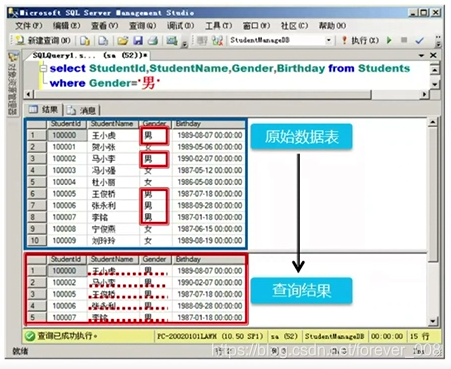
2)查询基本语法结构
查询一般有四个基本组成部分:

基本查询语法框架:
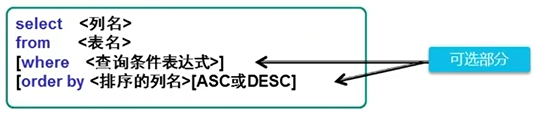
基本查询
(1)查询全部行和列
select * from Students
(2)查询部分行

(3)使用“AS”或使用“=”重新命名字段

(4)使用‘+’进行列的合并

(5)查询空列
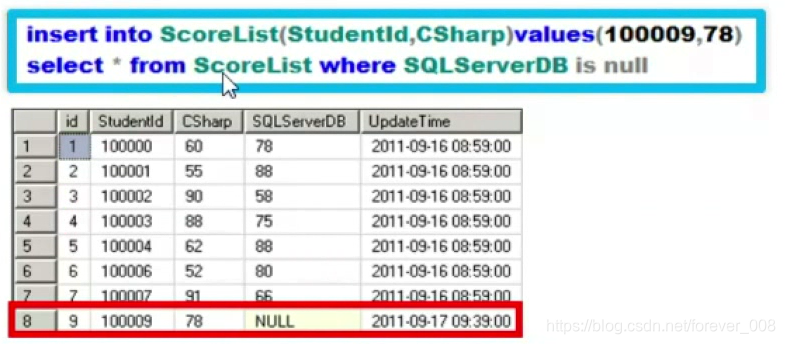
(6)使用常量列

(7)限制固定行数
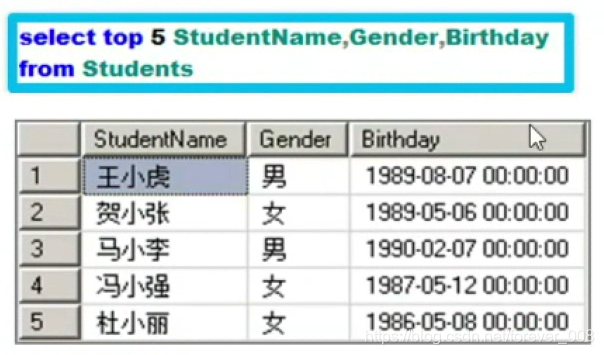
(8)返回百分之多少行
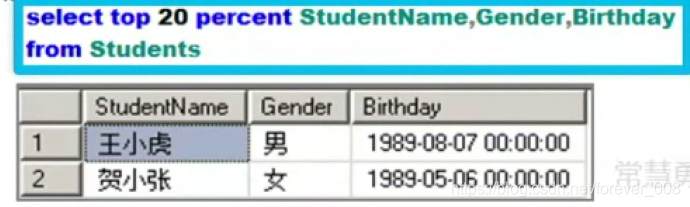
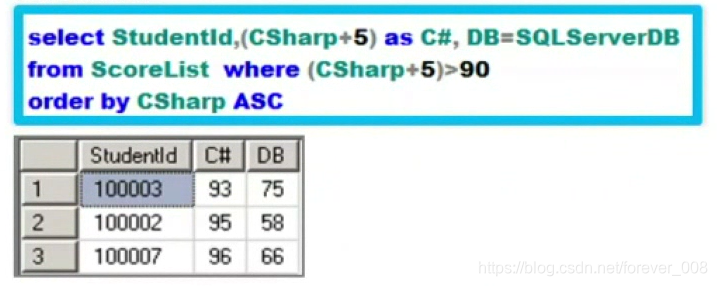
(9)升序排列
这里用到了(CSharp+5)这是直接在原来分数上都加上5分;
(10)降序排序
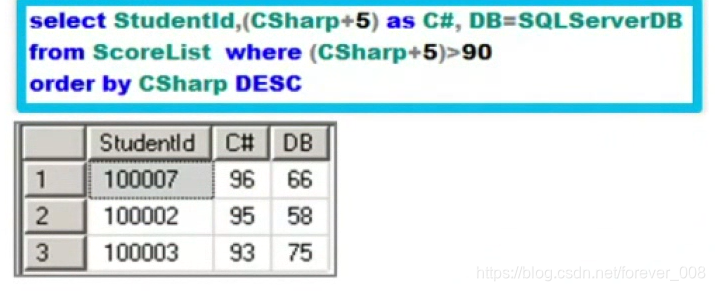
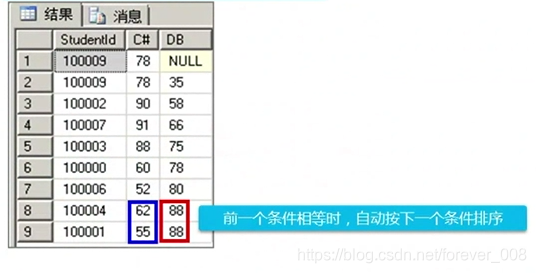
多个排序规则用“,”分隔;
select StudentId, CSharp as C#, DB = SQLServer
from ScoreList
order by SQLServerDB DESC, CSharp DESC
(二)模糊查询
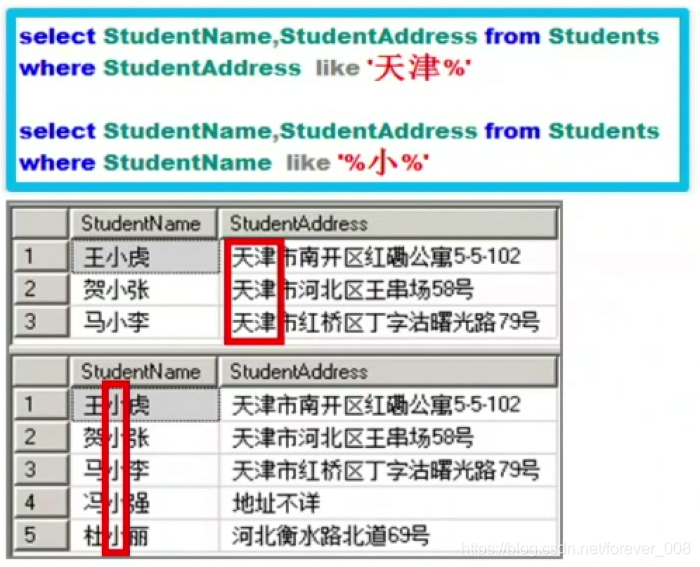
1)模糊查询-like
- 特点:使用like进行查询时,字段中的不同内容并不一定与查询内容完全匹配,只要字段中含有这些内容即可;
- 注意%的使用,还有单引号的使用;
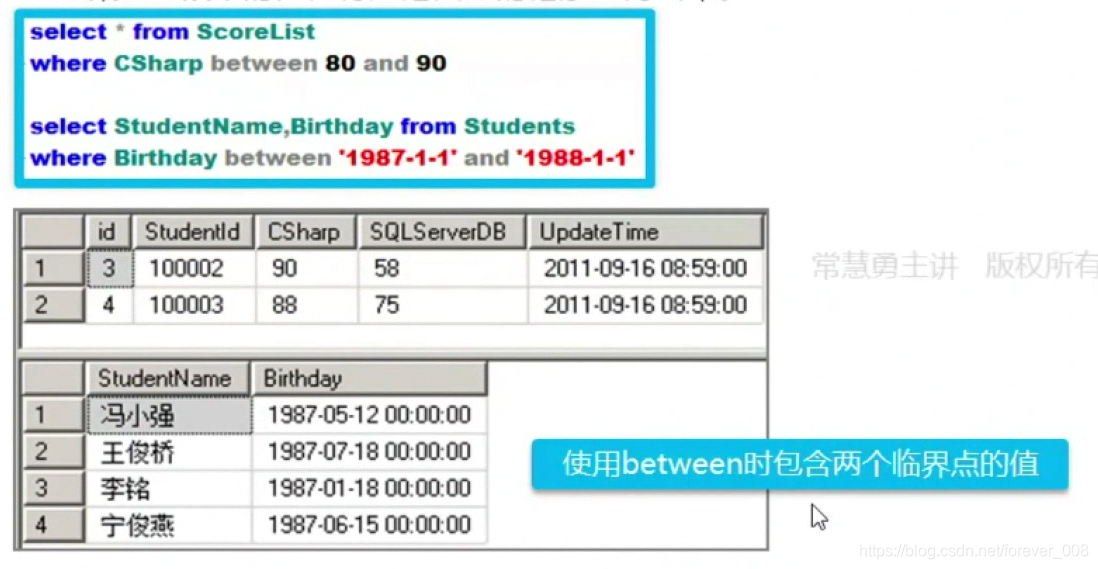
模糊查询-between
- 把某一字段中的值在特定范围内的记录查询出来;
- 包含端点值;
- 日期要加上单引号;
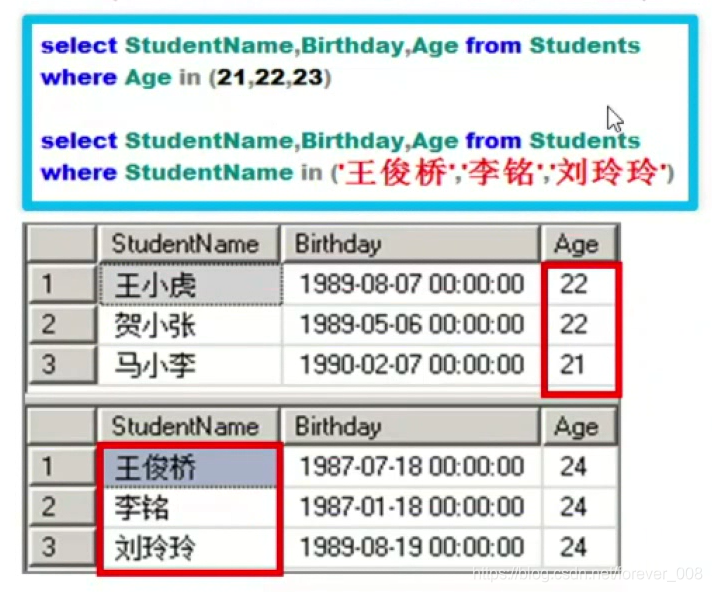
模糊查询- in
- 把某一字段中内容与所列出的查询内容列表匹配的记录查询出来;
(三)查询函数的使用
1)聚合函数
对某一列求和、对满足条件的记录总数求和;
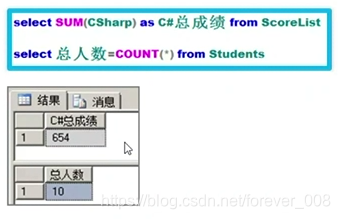
求最值、平均值:

(四)多表之间的数据查询
1)内连接查询
- 内连接查询:查询的结果是两个源表中严格满足连接条件的记录相连;【两个表之间有主外键关系】
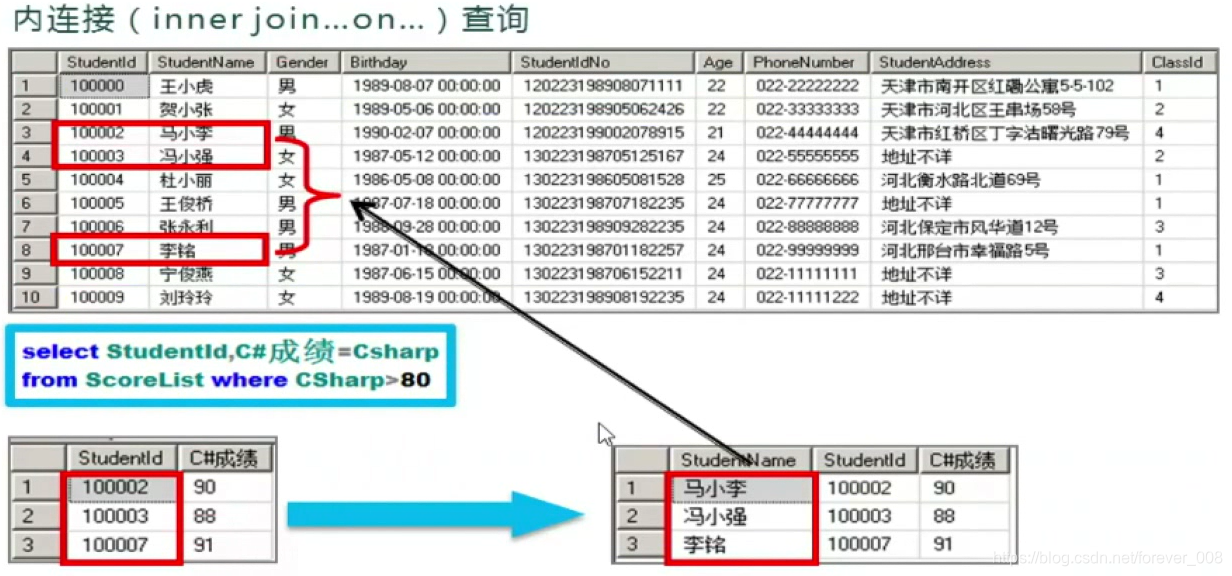
代码实现:
- inner…join…后面的实际上就是两个表之间的主外键关系,先写哪一个无所谓;
- 下面的例子中Students 与ScoreList 是主外键关系;
- 由于StudentId是两个表所共有的,所以查询的时候要明确来自于哪一个表格;
select ScoreList.StudentId, StudentName,CSharp成绩 = CSharp
from ScoreList
inner join Students on Students.StudentId = ScoreList.StudentId
where CSharp>80
注意:
- 清楚需要连接的表;
- 两个表连接的条件(主外键);
- 表中相同的字段,必须说明来自哪一个表;
多表连接:
多表查询:只需要使用inner join 将多个表按照条件连接即可;
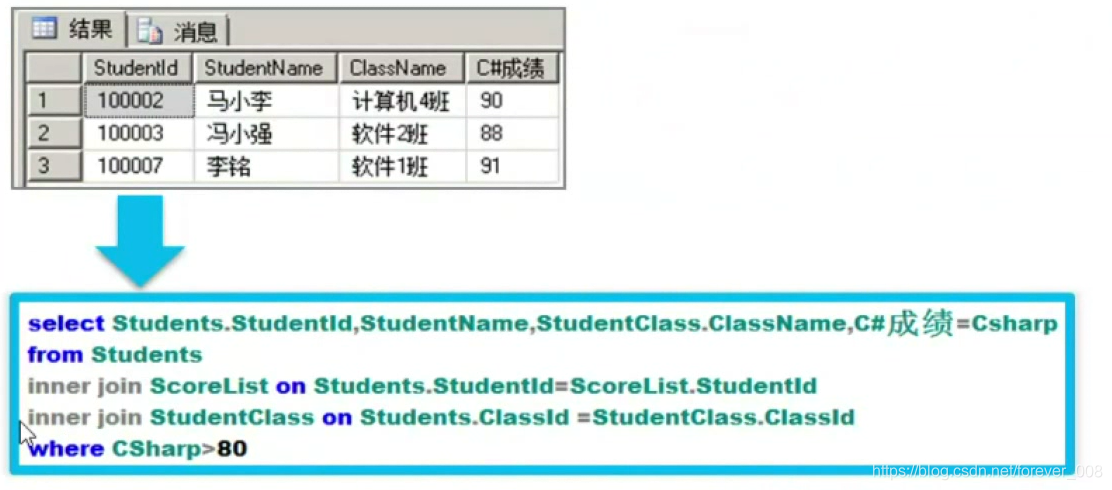
2)左外连接查询
举例:
-
两个原始的表格,分别查询的结果:

-
使用左外连接查询:

内涵:
- 查询的结果包含:连个表 所有满足连接条件的记录 + 左表中所有不满足连接条件的记录【这些不满足连接条件的左表记录,在查询结果的右表中,全部填上NULL值】
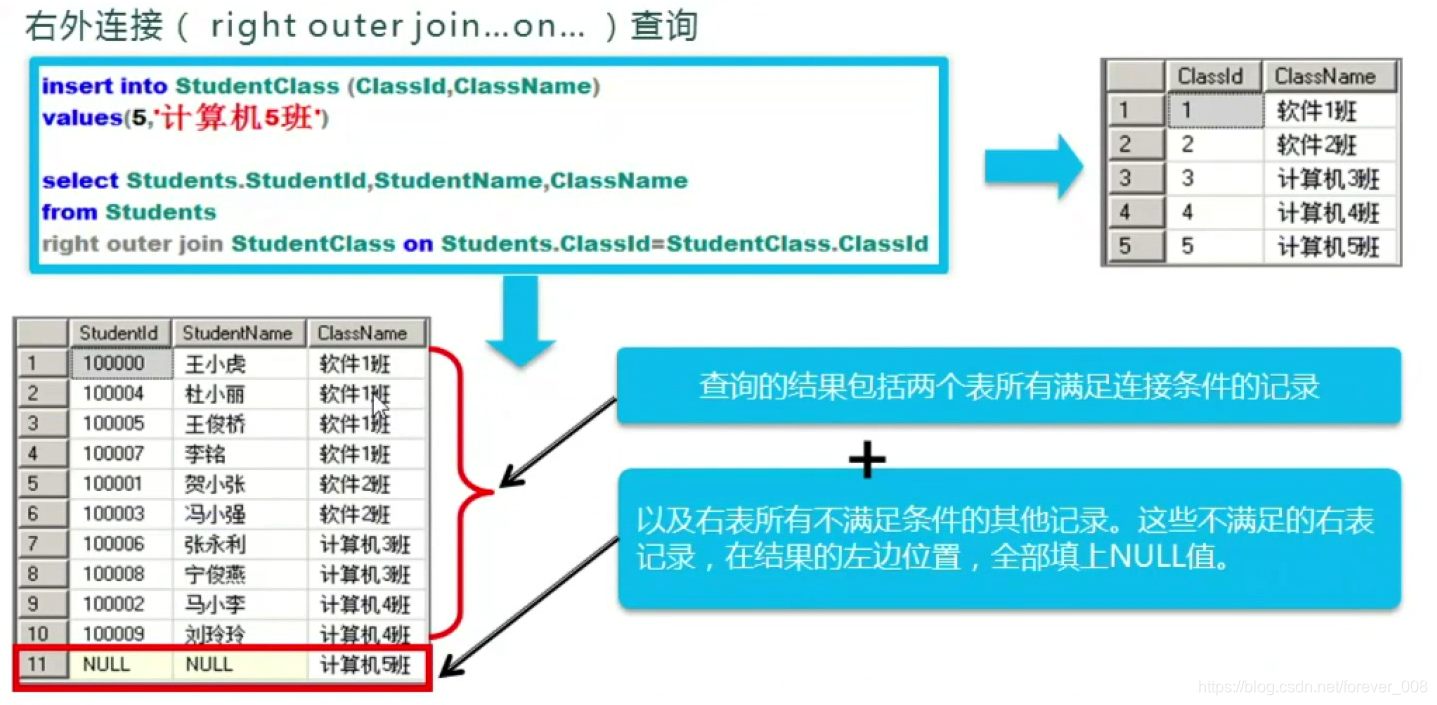
3)右外连接查询
- 查询的结果包含:连个表 所有满足连接条件的记录 + 右表中所有不满足连接条件的记录【这些不满足连接条件的左表记录,在查询结果的右表中,全部填上NULL值】
(五)分组查询与统计
1)使用Group By 分组:

注意:所查询的字段必须出现在Group By 中,或者必须是可以汇总的(比如按照班级分组,所查询的内容可以是班级最高分、平均分、总人数等,但是不能是每个人的姓名)
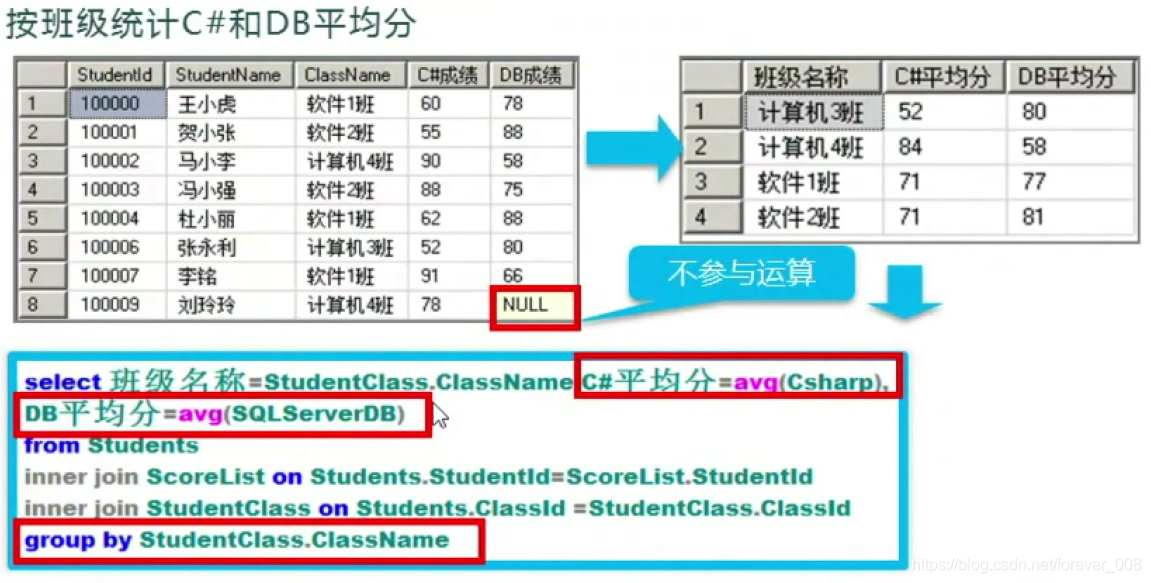
注意:NULL值是不参与运算的;但是这种情况有时候并不是我们想要的,我们可能需要将这个NULL补为0,通常情况下在临时表上进行操作;
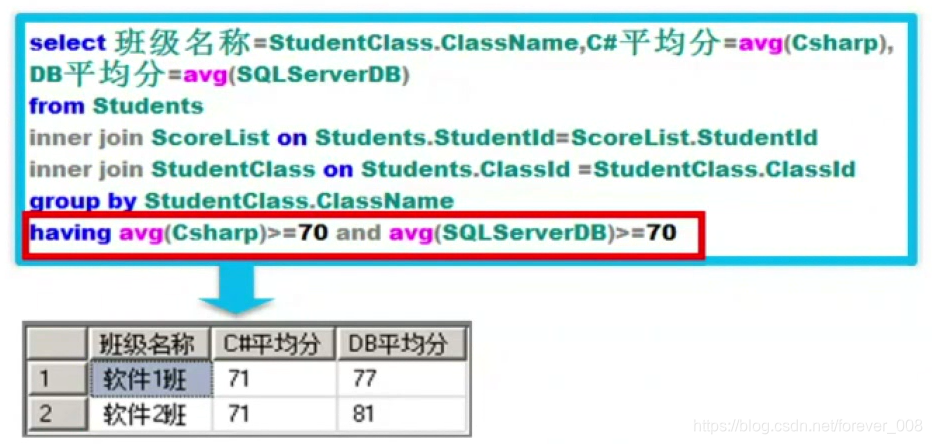
2)分组统计筛选–having
- 使用having筛选分组统计后的结果;不能使用where;
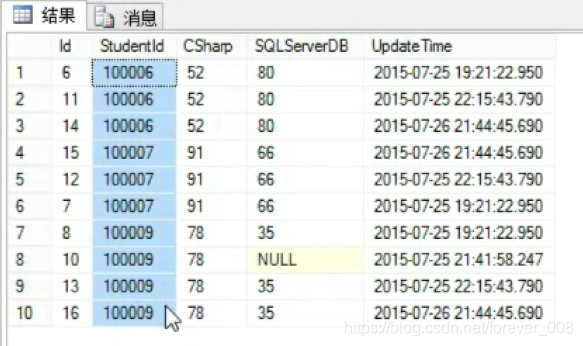
3)重复数据的查询
<1>知道重复字段的情况下
找出数量大于1的分组;
select StudentId from ScoreList Group by StudentId
having COUNT(*)>1
<2>查看具体重复的内容:
在前一步的基础上;
select * from ScoreList
where StudentId in(select StudentId from ScoreList Group by StudentId having COUNT(*)>1)
order by StudentId
3)分组查询对比
-
where子句:
- 从数据源中去掉不符合其搜索条件的数据;
-
group by 子句:
- 搜集数据行到各个组中;
- 统计函数为各个组计算统计值;
-
having子句:
- 在分组结果中,去掉不符合其搜索条件的各组数据行;
















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









