






原文地址: https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/try-flink/table_api.html
代码示例:Flink-playgrounds 的 table-walkthrough
本地代码:/Users/xxxx/local_dir/yyyy/flink-playgrounds/operations-playground/table-walkthroughtable-walkthrough工程带来的意义:
1.SpendReport 类可作为简易实时报表功能开发的代码模板
2. SpendReport 类可作为查看 Table API 源码的示范程序
3. SpendReportTest 测试类可作为编写测试用例的模板
Apache Flink 提供 Table API 作为统一的关系 API,用于批处理和流处理,即查询在无边界的实时流或有约束的批处理数据集上以相同的语义执行,并产生相同的结果。Flink 中的 Table API 通常用于简化数据分析,数据管道和 ETL 应用程序的定义。
您将要建造什么?
在本教程中,您将学习如何构建实时仪表板以按帐户跟踪财务交易。 该管道将从 Kafka 读取数据,并将结果写入通过 Grafana 可视化的 MySQL。
先决条件
本演练假定您对Java或Scala有所了解,但是即使您来自其他编程语言,也应该能够继续学习。 它还假定您熟悉基本的关系概念,例如SELECT和GROUP BY子句。
救命,我被卡住了!
如果遇到困难,请查看社区支持资源。 特别是,Apache Flink的用户邮件列表始终被视为所有Apache项目中最活跃的邮件列表之一,并且是快速获得帮助的好方法。
如何遵循
如果要继续学习,则需要一台具有以下功能的计算机:
- Java 8 or 11
- Maven
- Docker
所需的配置文件在flink-playgrounds存储库中可用。 下载后,在您的IDE中打开项目flink-playground / table-walkthrough并导航到SpendReport文件。
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")");
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")");
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
分解代码
执行环境
前两行设置了TableEnvironment。 表环境是您可以为Job设置属性,指定是编写批处理应用程序还是流应用程序以及创建源的方法。 本演练将创建一个使用流运行时的标准表环境。
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);登记表
接下来,在可用于连接到外部系统的环境中注册表,以读取和写入批处理和流数据。 表源提供对存储在外部系统(例如数据库,键值存储,消息队列或文件系统)中的数据的访问。 表接收器将表发送到外部存储系统。 根据源和接收器的类型,它们支持不同的格式,例如CSV,JSON,Avro或Parquet。
tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")");两个表被注册; 交易输入表和支出报告输出表。 通过交易(交易)表,我们可以读取信用卡交易,其中包含帐户ID(account_id),时间戳记(transaction_time)和美元金额(金额)。 该表是有关Kafka主题(包含CSV数据的交易)的逻辑视图。
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")");第二个表,spend_report存储了聚合的最终结果。 它的基础存储是MySql数据库中的表。
查询
配置好环境并注册表后,就可以构建第一个应用程序了。 在TableEnvironment中,您可以读取输入表以读取其行,然后使用executeInsert将这些结果写入输出表中。 报告功能是实现业务逻辑的地方。 目前尚未实现。
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");测试
该项目包含一个辅助测试类SpendReportTest,用于验证报告的逻辑。 它以批处理方式创建表环境。
EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build();
TableEnvironment tEnv = TableEnvironment.create(settings); Flink的独特属性之一是,它在批处理和流传输之间提供一致的语义。 这意味着您可以在静态数据集上以批处理模式开发和测试应用程序,并以流应用程序的形式部署到生产环境!
尝试一次
现在,有了Job设置的框架,您就可以添加一些业务逻辑。 目的是建立一个报告,显示每个帐户在一天中每个小时的总支出。 这意味着时间戳列需要从毫秒舍入到小时粒度。
就像SQL查询一样,Flink可以选择必填字段并按键进行分组。 这些功能结合floor和sum内置函数可以编写此报告。
public static Table report(Table rows) {
return rows.select(
$("account_id"),
$("transaction_time").floor(TimeIntervalUnit.HOUR).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}用户定义功能
Flink包含有限数量的内置函数,有时您需要使用用户定义的函数对其进行扩展。 如果未预先定义楼层,则可以自己实施。
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.functions.ScalarFunction;
public class MyFloor extends ScalarFunction {
public @DataTypeHint("TIMESTAMP(3)") LocalDateTime eval(
@DataTypeHint("TIMESTAMP(3)") LocalDateTime timestamp) {
return timestamp.truncatedTo(ChronoUnit.HOURS);
}
}然后将其快速集成到您的应用程序中。
public static Table report(Table rows) {
return rows.select(
$("account_id"),
call(MyFloor.class, $("transaction_time")).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}该查询使用交易表中的所有记录,计算报告,并以有效,可扩展的方式输出结果。 使用此实现运行测试将通过。
新增视窗
基于时间对数据进行分组是数据处理中的典型操作,尤其是在处理无限流时。 基于时间的分组称为窗口,而Flink提供了灵活的窗口语义。 最基本的窗口类型称为滚动窗口,该窗口具有固定大小,并且其存储桶不重叠。
public static Table report(Table rows) {
return rows.window(Tumble.over(lit(1).hour()).on($("transaction_time")).as("log_ts"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts").start().as("log_ts"),
$("amount").sum().as("amount"));
}这将您的应用程序定义为使用基于timestamp列的一小时滚动窗口。 因此,将带有时间戳2019-06-01 01:23:47的行放在2019-06-01 01:00:00窗口中。
基于时间的聚合是唯一的,因为与其他属性相反,时间通常在连续流应用程序中向前移动。 与floor和UDF不同,window函数是内部函数,它允许运行时应用其他优化。 在批处理环境中,Windows提供了一种方便的API,用于按timestamp属性对记录进行分组。
使用此实现运行测试也将通过。
再一次,与流!
就是这样,一个功能齐全,有状态的分布式流应用程序! 查询持续消耗来自Kafka的交易流,计算每小时支出,并在准备好后立即发出结果。 由于输入是无界的,因此查询将一直运行,直到手动将其停止为止。 并且由于作业使用基于时间窗口的聚合,因此Flink可以执行特定的优化,例如当框架知道不再有特定窗口的记录到达时,进行状态清除。
这个table playground 已完全docker化,可作为流应用程序在本地运行。 该环境包含一个Kafka主题,一个连续数据生成器,MySql和Grafana。
从table-walkthrough文件夹中启动docker-compose脚本。
$ docker-compose build
$ docker-compose up -d您可以通过Flink控制台查看有关正在运行的作业的信息。
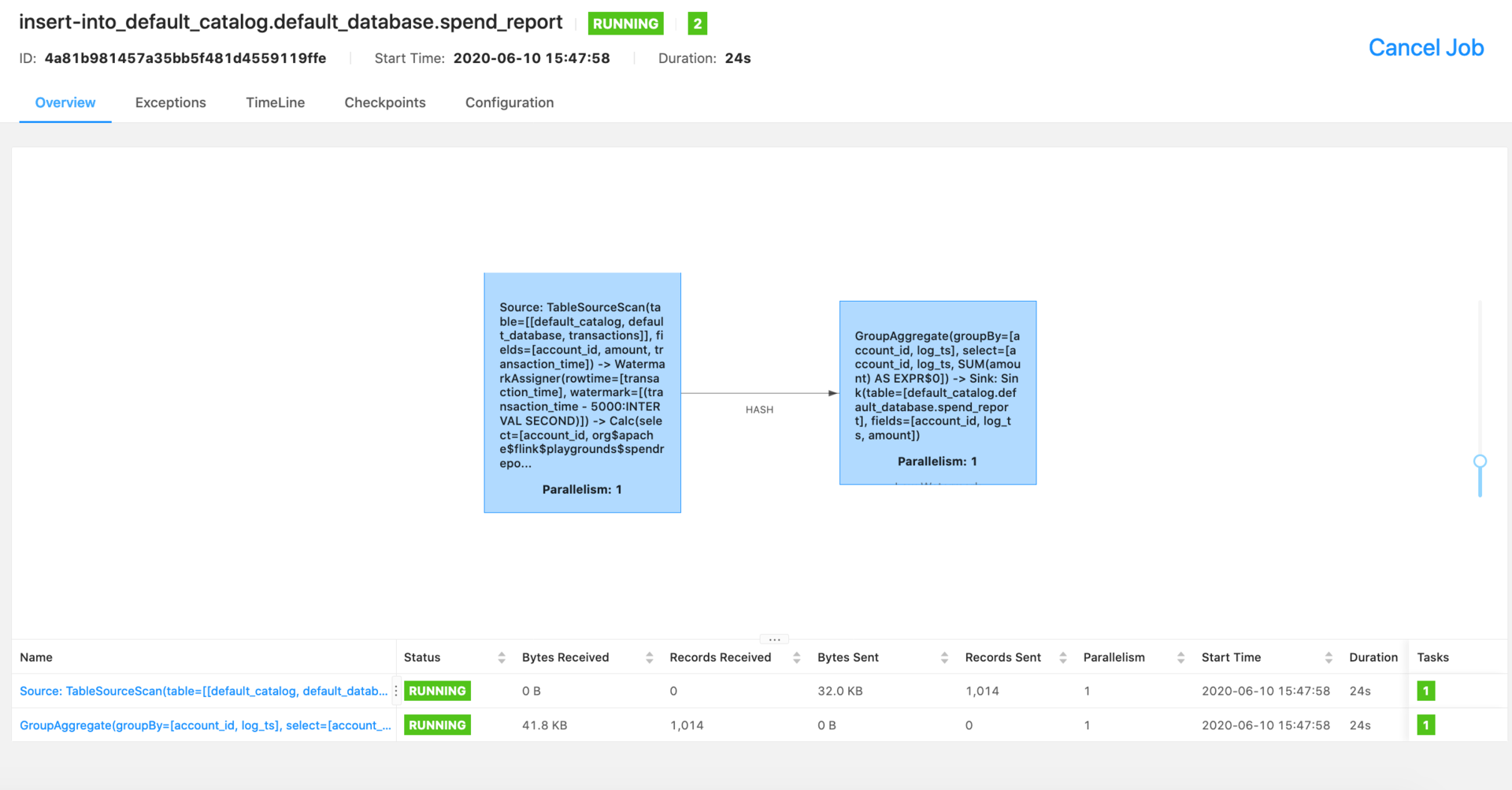
从MySQL内部探索结果。
$ docker-compose exec mysql mysql -Dsql-demo -usql-demo -pdemo-sql
mysql> use sql-demo;
Database changed
mysql> select count(*) from spend_report;
+----------+
| count(*) |
+----------+
| 110 |
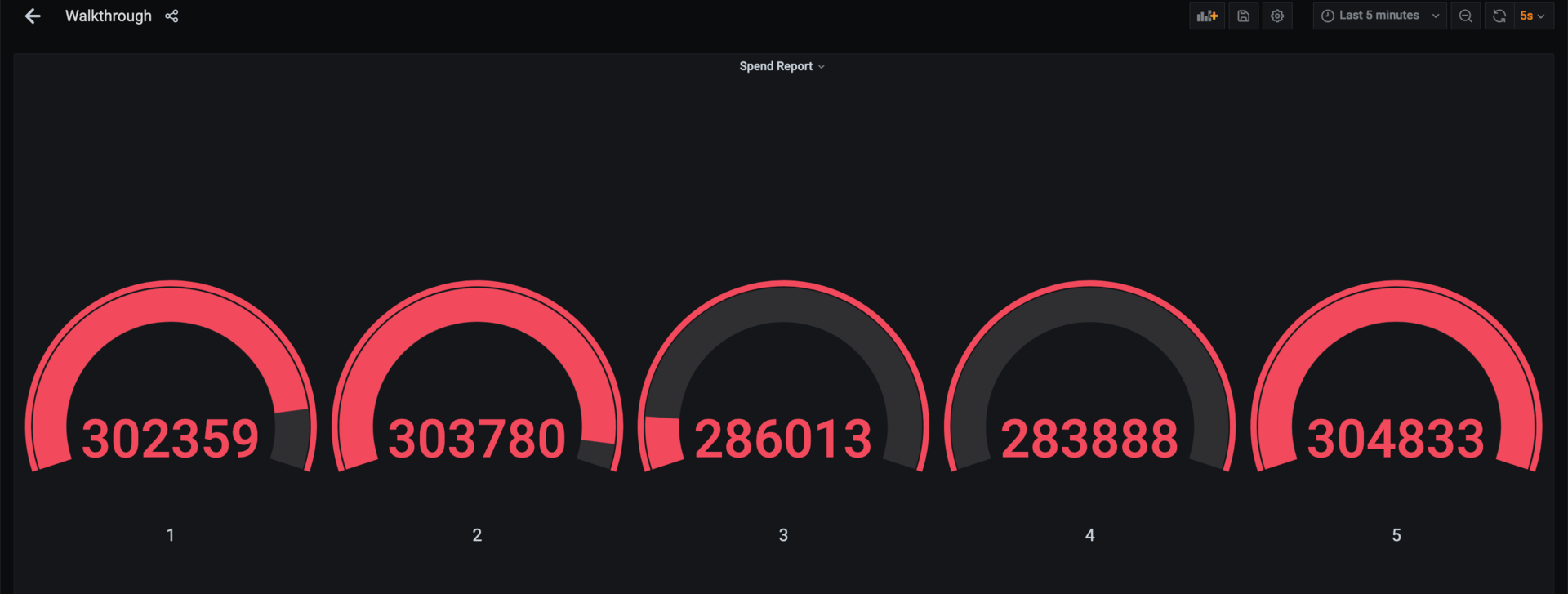
+----------+最后,转到Grafana以查看完全可视化的结果!















 1265
1265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









