







 这篇博客详细介绍了MPI的基础编程,从mpi_hello.c开始,讲解了MPI环境的初始化和终止,以及MPI_Comm_size和MPI_Comm_rank等关键函数。通过乒乓通信mpi_pingpong.c示例,展示了MPI的通信过程。接着讨论了并行计算π的两种策略,分析了不同进程数计算结果的差异及加速比非线性问题。最后,提到了MPI广播、规约和全规约操作,并探讨了MPI程序中的并行性问题。
这篇博客详细介绍了MPI的基础编程,从mpi_hello.c开始,讲解了MPI环境的初始化和终止,以及MPI_Comm_size和MPI_Comm_rank等关键函数。通过乒乓通信mpi_pingpong.c示例,展示了MPI的通信过程。接着讨论了并行计算π的两种策略,分析了不同进程数计算结果的差异及加速比非线性问题。最后,提到了MPI广播、规约和全规约操作,并探讨了MPI程序中的并行性问题。
这篇博客将以最基础的MPI代码开始逐步介绍通信,并行策略实现,注意需要提前安装MPI,以下默认系统安装了MPI
mpi_hello.c
首先还是以hello world开头介绍
#include <mpi.h>
#include <stdio.h>
int main(int argc,char** argv){
int size;
int rank;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
printf("the process of %d of %d:hello world\n",rank,size);
if (rank == 0){
printf("that is all\n");
}
MPI_Finalize();
return 0;
}
运行代码的命令是下面三行,运行这3个代码表示这个代码在登录节点运行,但是一般代码需要提交到计算节点运行。
module add mpich
mpicc mpi_hello.c -o hello
mpiexec -n 4 ./hello
在实际操作的时候,如果希望把代码放到计算节点运行,可以使用slurm文件提交脚本,这里教学一般提供一个Makefile文件和一个run.slurm文件
Makefile
CC = mpicc
FLAGS = -O3 -Wall
OBJ = *.o
EXE = hello pingpong
all: ${EXE}
hello: mpi_hello.c
$(CC) -o $@ $^ $(FLAGS)
pingpong: mpi_pingpong.c
$(CC) -o $@ $^ $(FLAGS)
clean:
rm -f $(OBJ) $(EXE)
run.slurm
#!/bin/bash
#SBATCH -o job_%j.out
#SBATCH --partition=cpu
#SBATCH -J mpi-ex1
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=4
#SBATCH --cpus-per-task=1
#SBATCH -t 10:00
# you'll need mpich to run this job
#mpiexec -n 4 ./hello
mpiexec -n 2 ./pingpong
这里解释一下选项的意思
-o表示结果将以什么形式保存
–partition表示选择分区是CPU还是GPU
-J表示这个操作的名字,这个可以不管
–nodes单节点的任务数
–cpus-per-task单任务需要的核心数
-t时间上限,这个代码最多允许花多少时间来运行,运行代码注意需要把Makefile,run.slurm,mpi_hello.c放到同一个文件夹下面。
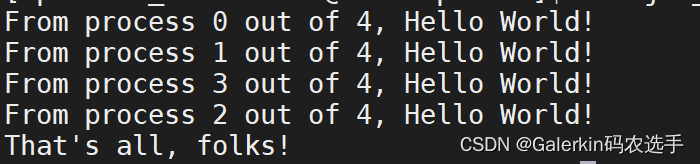
结果表明进程并不是按顺序执行的。
1:MPI include file,头文件包含MPI库提供的函数接口定义,一般是
#include<mpi.h>
2:Initialize MPI environment
3:do work,MPI库里面的函数一般开头都是MPI_
4:terminate MPI environment
上面这个代码就用到了MPI常用的6个函数,理论上说任意功能都可以通过这6个函数来实现
1:MPI_Init
初始化MPI环境,一般在主程序开头
int MPI_Init(int *argc,char **argv)
2:MPI_Finalize
结束MPI环境,一般在主程序结尾
int MPI_Finalize()
如果运行正常,所有MPI函数返回值都是MPI_SUCCESS常量
3:MPI_Comm_size
决定一共使用多少个进程
4:MPI_Comm_rank 告诉程序当前在第几个进程
5:MPI_Send 发送消息,传递消息
6:MPI_Recv 接受消息
通信器
∙\bullet∙ 定义了所有参与通信进程的集合
∙\bullet∙几乎所有MPI函数都需要指定该函数作用的通信器
∙\bullet∙ 通信器变量的数据类型是MPI_Comm
∙\bullet∙默认通信器是MPI_COMM_WORLD(所有进程)
#---------------------------------------------------
∙\bullet∙ MPI_Comm_size 获取目标通信器的总进程数
∙\bullet∙MPI_Comm_rank 获取当前进程在目标通信器的进程号
int MPI_Comm_size(MPI_Comm com, int *size)#不同进程调用该函数返回值都一样
int MPI_Comm_rank(MPI_Comm com, int *rank)#不同进程返回不一样的rank
∙\bullet∙ rank的范围是0,1,…,size - 1
∙\bullet∙同一个进程可以属于不同通信器,因此rank会不一样,比如说在10个进程中,通信器如果是所有10个进程,那么rank=5表示第6个进程,通信器如果是所有偶数进程,那么rank=5就是第3个进程
乒乓通信mpi_pingpong.c
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
int token, size, rank;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) {
token = -1;
MPI_Send(&token, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD);
printf("Process %d pinged token %d to process %d\n", rank, token, 1-rank);
MPI_Recv(&token, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("Process %d ponged token %d from process %d\n", rank, token, 1-rank);
} else if (rank == 1) {
MPI_Recv(&token, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Send(&token, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}
这个代码开始体现了MPI的通信
int MPI_Send(void *buf,int count,MPI_Datatype datatype, int dest,int tag,MPI_Comm comm)
int MPI_Recv(void *buf,int count,MPI_Datatype datatype, int source,int tag,MPI_Comm comm, MPI_Status *status)
tag表示消息标签(非负整数),最大不可以超过常量MPI_TAG_UB
buf表示发送和接收的消息所对应的本地内存位置,每个进程内部存储私有,因此在不同进程中内存位置不一样。
count表示发送和接收的消息长度
datatype表示发送接收的消息的数据类型
dest和source分别表示接收端和发送端的进程号
接收端和发送端设定的消息长度可以不一样,但是最好不要。
接收函数比发送函数多一个参数:status用于保存函数返回的通信状态,可以设置为MPI_STATUS_IGNORE,它的类型MPI_Status是一个MPI预定义的结构体
这个代码我们来观察,如果rank=0,那么这个0号进程就会把token发送给1号进程,如果rank=1,那么1号进程就会接收来自0号进程的token,同时把token发送回去给0号进程,只有当rank=0的时候才会打印结果。
这个代码很简单,但是如果0号进程把token发送出去,1号进程没有接收到token,此时1号进程是否会启动自己的发送命令呢?
交换通信设定两个进程,0号进程和1号进程分别存储一个数据,利用MPI将两个进程的数据进行交换。
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
int a, b, size, rank;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) {
a = -1;
MPI_Send(&a, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD);
printf("Process %d sent token %d to process %d\n", rank, a, 1-rank);
MPI_Recv(&b, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("Process %d received token %d from process %d\n", rank, b, 1-rank);
} else if (rank == 1) {
a = 1;
MPI_Recv(&b, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Send(&a, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}
注意在不同进程里面,变量的地址私有,因此如果把
else if (rank == 1) {
a = 1;
MPI_Recv(&b, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Send(&a, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD);
}
修改为下面这种形式,结果仍然是对的
else if (rank == 1) {
b = 1;
MPI_Recv(&a, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Send(&b, 1, MPI_INT, 1-rank, 0, MPI_COMM_WORLD);
}
如果两个进程需要进行数据交换,可以使用发送组合操作
int MPI_Sendrecv(void *sendbuf,int sendcount,MPI_Datatype senddatatype,int dest,int sendtag,void *recvbuf, int recvcount, MPI_Datatype recvdatatype,int source, int recvtag,MPI_Comm comm,MPI_Status *status)
如果交换的数据共用一个buffer,可以借助于下面操作,这种做法可以减少人为开辟缓冲区
int MPI_Sendrecv_replace(void *buf,int count,MPI_Datatype datatype,int dest,int sendtag,int source, int recvtag,MPI_Comm comm,MPI_Status *status)
下面本人洗一个更新以后的代码replace.c
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
int a, size, rank;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) {
a = -1;
printf("Process %d sent token %d to process %d\n", rank, a, 1-rank);
MPI_Sendrecv_replace(&a,1,MPI_INT,1 - rank,0,1 - rank,1,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
printf("Process %d received token %d from process %d\n", rank, a, 1-rank);
} else if (rank == 1) {
a = 10;
MPI_Sendrecv_replace(&a,1,MPI_INT,1 - rank,1,1 - rank,0,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
}
MPI_Finalize();
return 0;
}
运行代码:
module add mpich
mpicc replace.c -o re
mpiexec -n 2 ./re
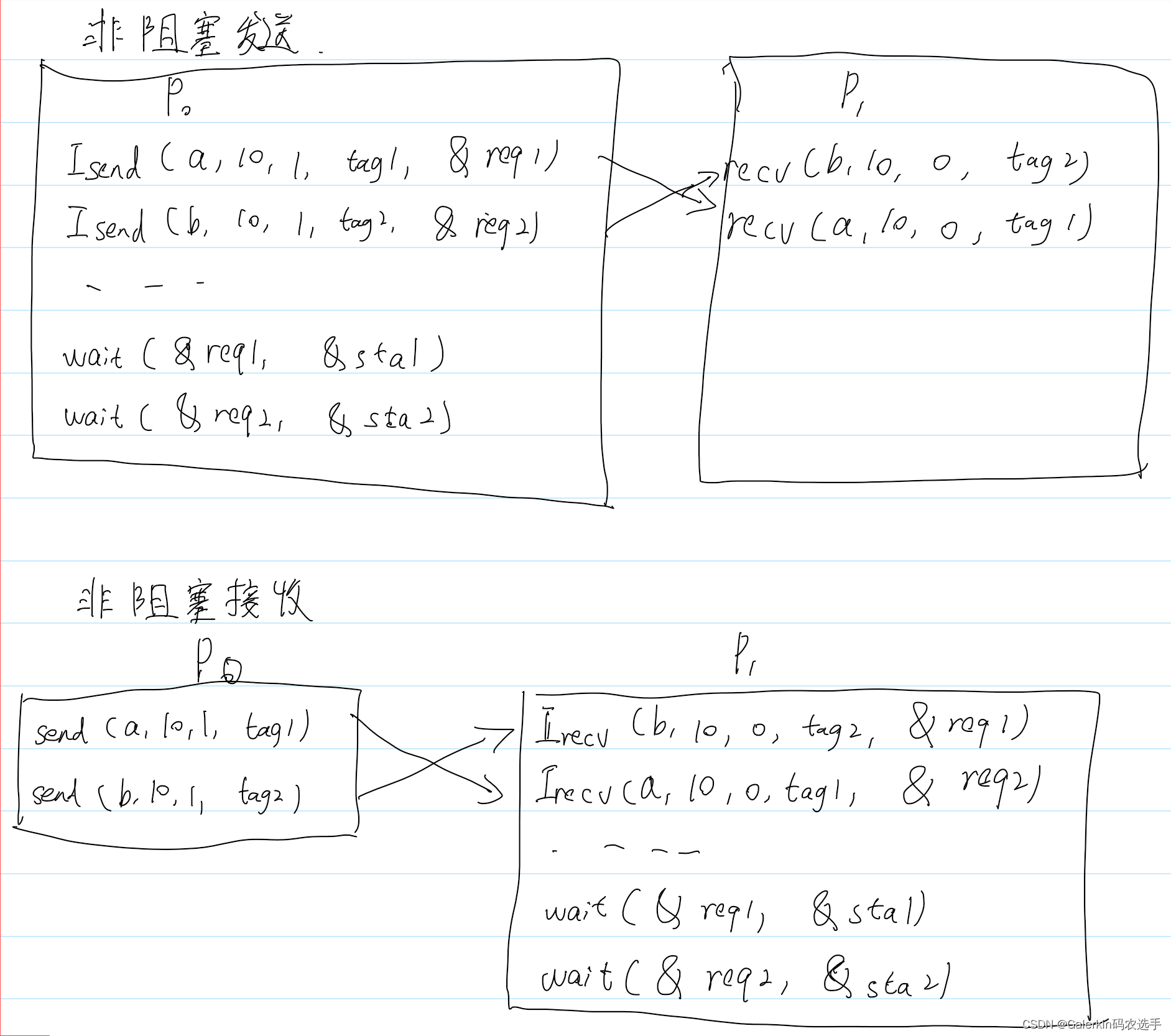
上面提到的一般是阻塞通信,非阻塞通信:运行该代码以后(不管是否运行成功,都会运行下一行代码),后台会执行通信。
int MPI_Isend(void *buf,int count,MPI_Datatype datatype, int dest,int tag,MPI_Comm comm,MPI_Request *request)
int MPI_Irecv(void *buf,int count,MPI_Datatype datatype, int source,int tag,MPI_Comm comm,MPI_Request *request)
request变量用来标记通信任务,方便后面测试通信是否成功。
利用计算π\piπ,代码
单位圆的面积就是π\piπ,这里我们计算1/4⚪的面积然后×4作为π\piπ的预估值,使用的公式是
π=4∫[0,1]1−x2dx\pi = 4 \int_{[0,1]}\sqrt{1 - x^2}dxπ=4∫[0,1]1−x2dx,利用中心积分公式,最终的离散形式为
π=4∑i=0N−11−xi2h,xi=(i+0.5)h,h=1N−1\pi = 4 \sum_{i = 0}^{N - 1}\sqrt{1 - x_i^2}h,x_i = (i + 0.5)h,h = \frac{1}{N - 1}π=4∑i=0N−11−xi2h,xi=(i+0.5)h,h=N−11
这里提供两种并行策略,假设一共给n个进程来计算,那么每个进程平均应该计算N/nN/nN/n个矩形,但是N/nN/nN/n不见得是整数,为此考虑其中n−1n-1n−1个进程处理[N/n][N/n][N/n]个矩形,剩下N−(n−1)[N/n]N - (n-1)[N/n]N−(n−1)[N/n]矩形给最后一个进程,但是这种做法会导致一个问题,里面有n-1个进程处理[N/n][N/n][N/n]个矩形,一个进程处理N−(n−1)[N/n]N - (n-1)[N/n]N−(n−1)[N/n]个矩形,并且N−(n−1)[N/n]≥[N/n]N - (n-1)[N/n]\geq[N/n]N−(n−1)[N/n]≥[N/n],,也就是说n−1n-1n−1个进程都处理完了却等待最后一个进程才能结束
这里假设N%n=kN\%n=kN%n=k,那么对于前kkk个进程来说,每个进程处理(N−k)/n+1(N-k)/n + 1(N−k)/n+1个矩形,后面n−kn-kn−k个进程,每个进程处理(N−k)/n(N-k)/n(N−k)/n个矩形,这种做法比较合理。
下面考虑对于每个进程来说,该进程到底处理哪些矩形呢,下面也提供两种思路。

很明显,下面这种并行策略更简单,但是上面这种并行策略更具有数据一致性,因为在内存中相邻数据都是存在相邻地址的,上面这种并行策略局部性更好。
下面本人分别针对两种并行策略写一个代码来看结果
Makeflie
default: all
CC = mpicc
FLAGS = -O3 -Wall
OBJ = *.o
EXE = cpi cpi2
all: ${EXE}
cpi: mpi_cpi.c
$(CC) -o $@ $^ $(FLAGS) -lm
cpi2: mpi_cpi2.c
$(CC) -o $@ $^ $(FLAGS) -lm
clean:
rm -f $(OBJ) $(EXE)
run.slurm
#!/bin/bash
#SBATCH -o job_%j.out
#SBATCH --partition=cpu
#SBATCH -J mpi-ex3
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=8
#SBATCH --cpus-per-task=1
#SBATCH -t 10:00
# you'll need mpich to run this job
#mpiexec -n 1 ./cpi
#mpiexec -n 2 ./cpi
#mpiexec -n 4 ./cpi
#mpiexec -n 8 ./cpi
mpiexec -n 1 ./cpi2
mpiexec -n 2 ./cpi2
mpiexec -n 4 ./cpi2
mpiexec -n 8 ./cpi2
运行代码使用
make
sbatch run.slurm
mpi_cpi1.c
#include "mpi.h"
#include <stdio.h>
#include <math.h>
#define PI25DT 3.141592653589793238462643
#define REPEAT 20
int main(int argc, char *argv[]){
int size, rank, n, i, k;
double mypi, pi, h, sum, x, t0, t1;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) n = 10000000;
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
t0 = MPI_Wtime();
for (k = 0; k < REPEAT; k++) {
h = 1.0 / (double) n;
sum = 0.0;
for (i = rank + 1; i <= n; i += size) {
x = h * ((double)i - 0.5);
sum += sqrt(1.-x*x);
}
mypi = 4.0 * h * sum;
MPI_Allreduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, MPI_COMM_WORLD);
}
t1 = MPI_Wtime();
if (rank == 0) {
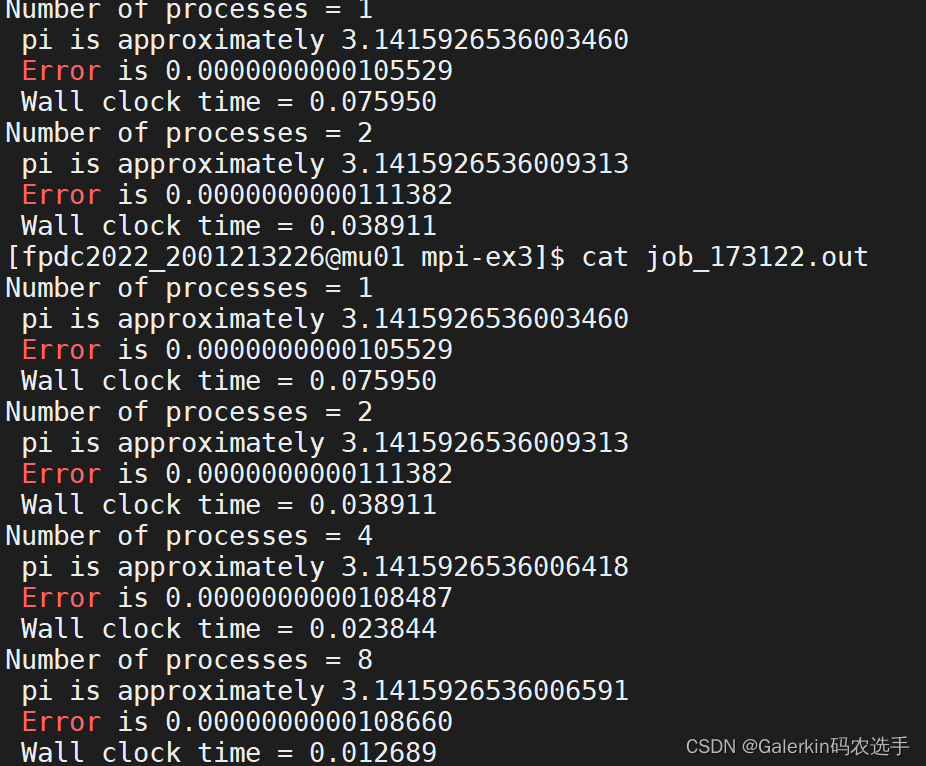
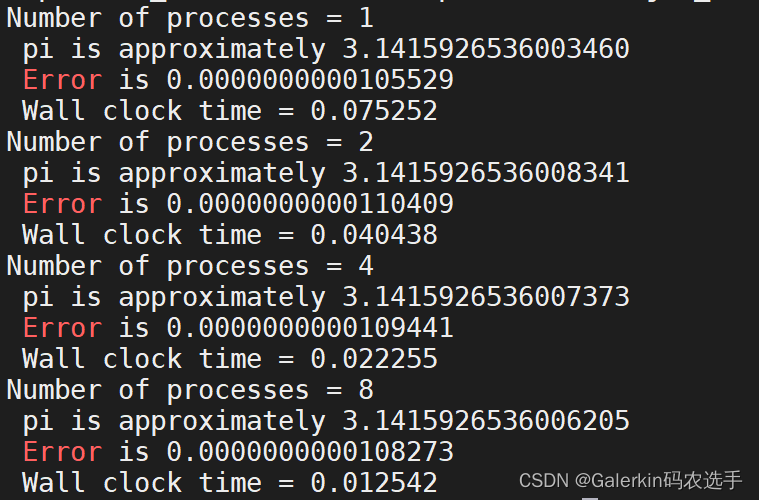
printf("Number of processes = %d\n", size);
printf(" pi is approximately %.16f\n", pi);
printf(" Error is %.16f\n", fabs(pi-PI25DT));
printf(" Wall clock time = %f\n", (t1-t0)/REPEAT);
}
MPI_Finalize();
return 0;
}
mpi_cpi2.c
#include "mpi.h"
#include <stdio.h>
#include <math.h>
#define PI25DT 3.141592653589793238462643
#define REPEAT 20
int main(int argc, char *argv[]){
int size, rank, n, i, k;
int step,du;
double mypi, pi, h, sum, x, t0, t1;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) n = 10000000;
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
step = n/size;
du = n%size;
t0 = MPI_Wtime();
for (k = 0; k < REPEAT; k++) {
h = 1.0 / (double) n;
sum = 0.0;
if (rank < du){
for (i = rank*(step + 1); i < (rank + 1)*(step + 1); i++) {
x = h * ((double)i + 0.5);
sum += sqrt(1.-x*x);
}
}
else{
for (i = du*(step + 1) + (rank - du)*step; i < du*(step + 1) + (rank - du + 1)*step; i++) {
x = h * ((double)i + 0.5);
sum += sqrt(1.-x*x);
}
}
mypi = 4.0 * h * sum;
MPI_Allreduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, MPI_COMM_WORLD);
}
t1 = MPI_Wtime();
if (rank == 0) {
printf("Number of processes = %d\n", size);
printf(" pi is approximately %.16f\n", pi);
printf(" Error is %.16f\n", fabs(pi-PI25DT));
printf(" Wall clock time = %f\n", (t1-t0)/REPEAT);
}
MPI_Finalize();
return 0;
}
上面两个代码引入了几个新的函数
∙\bullet∙墙钟函数double MPI_Wtime()
t0 = MPI_Wtime();
t1 = MPI_Wtime();
ela = t1 - t0;
MPI广播和规约
∙\bullet∙广播(boardcast)
int MPI_Bcast(void *buf,int count,MPI_Datatype datatype,int source,MPI_Comm,comm)
∙\bullet∙规约(reduce)
int MPI_Bcast(void *sendbuf,void *recvbuf,int count,MPI_Datatype datatype,MPI_Op op,int target,MPI_Comm,comm)
∙\bullet∙全规约(allreduce)
int MPI_Allreduce(void *sendbuf,void *recvbuf,int count,MPI_Datatype datatype,MPI_Op op,MPI_Comm,comm)
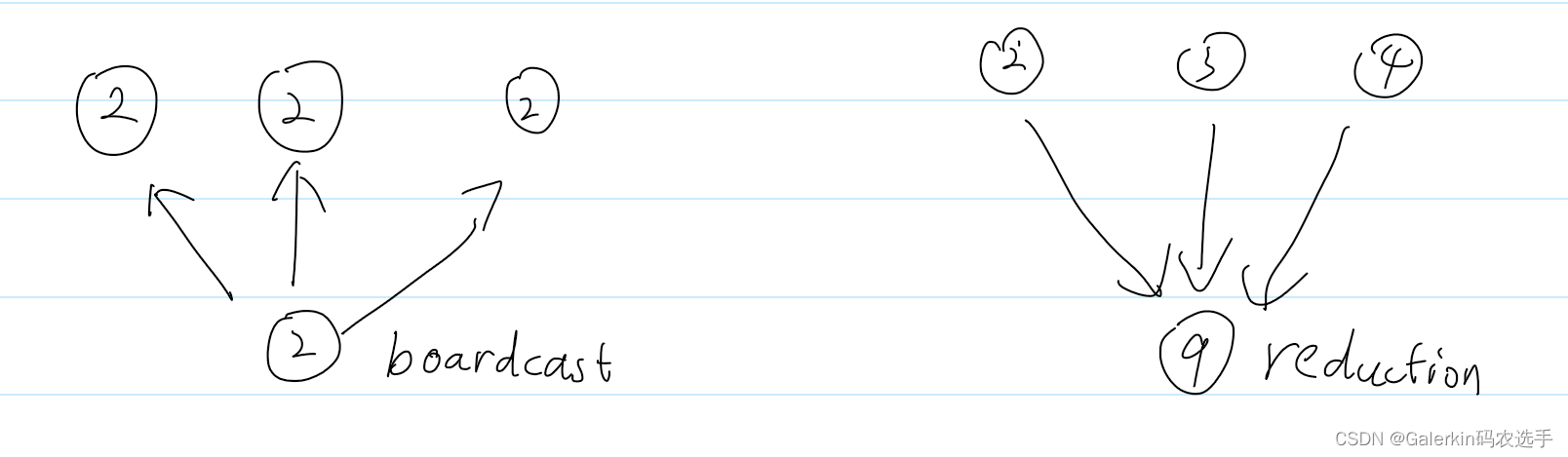
这里的MPI_Op指的是规约的方法,常见的有MPI_SUM,MPI_MAX,MPI_MIN
问题1:为什么不同进程数计算的结果不同?问题2:为什么加速比不是线性的?
问题1:不同进程之间加法顺序不同,浮点运算有差别,所以不同进程数目的结果不同(考虑∑i=1n1n\sum_{i=1}^{n}\frac{1}{n}∑i=1nn1的计算,会发现从前面开始计算和从后面开始计算结果也会不同,就是这个原因)
还有一个现象,如果反复提交作业会发现两次提交的作业对于同样进程数目的计算结果也不同,这是因为每次提交作业过程中,不同进程之间加法顺序,reduce顺序不同,会造成误差,以及不同MPI版本也会影响结果。
问题2:代码里面有串行部分,h的计算,sum=0.0,mypi=h*sum都是串行部分,这部分可以提出来,但是最重要的是里面的reduce函数,进程数目越多,这个函数执行时间越长,所以不可能达到线性加速比。
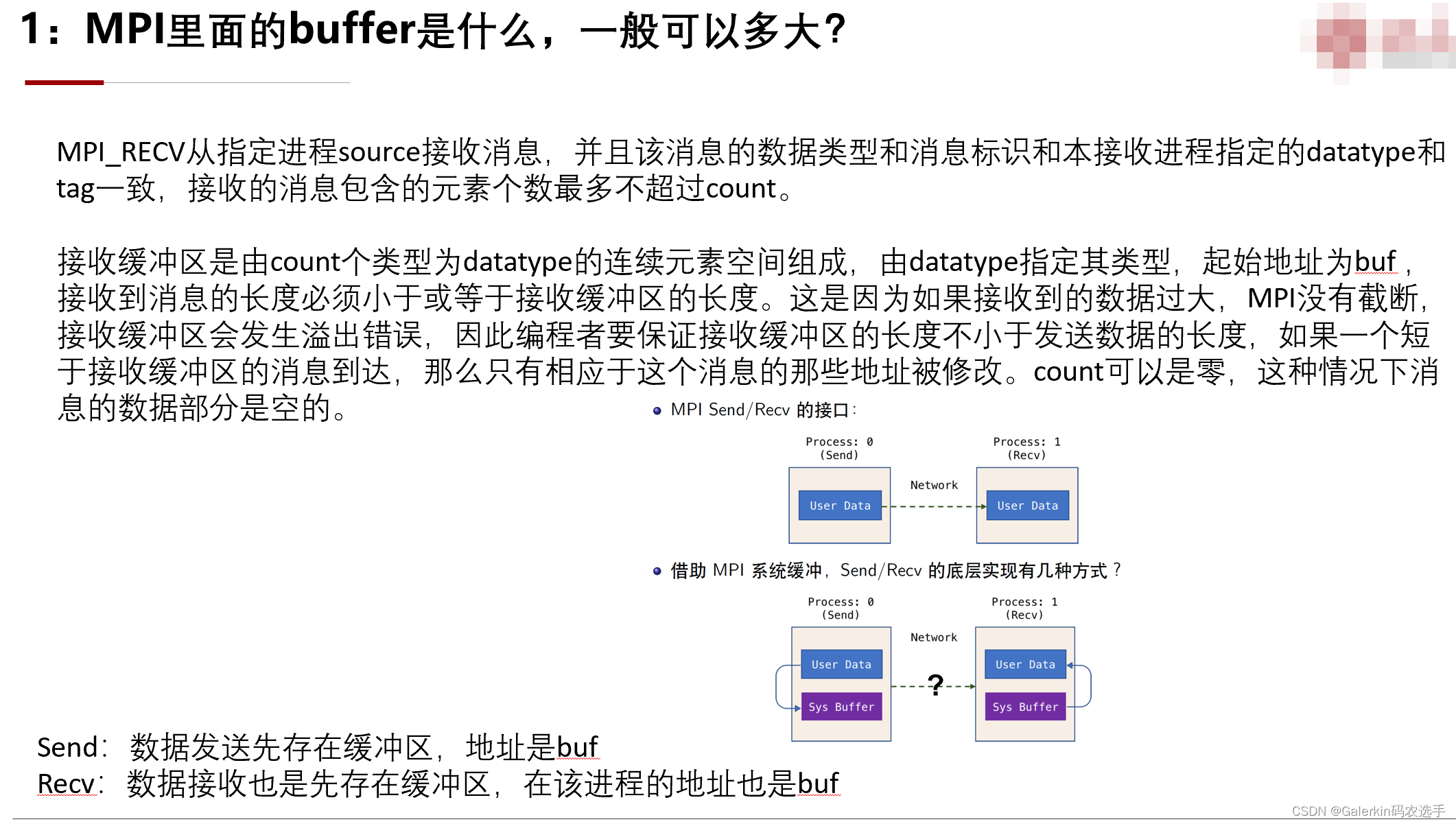
重点解读MPI的基础问题






















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











