







1. 搜狗那个微信的搜索不行,用这个方法了,先要有一个公众号,然后新建图文信息,链接这边可以搜索一个公众号的所有文章。Ajax的格式的。
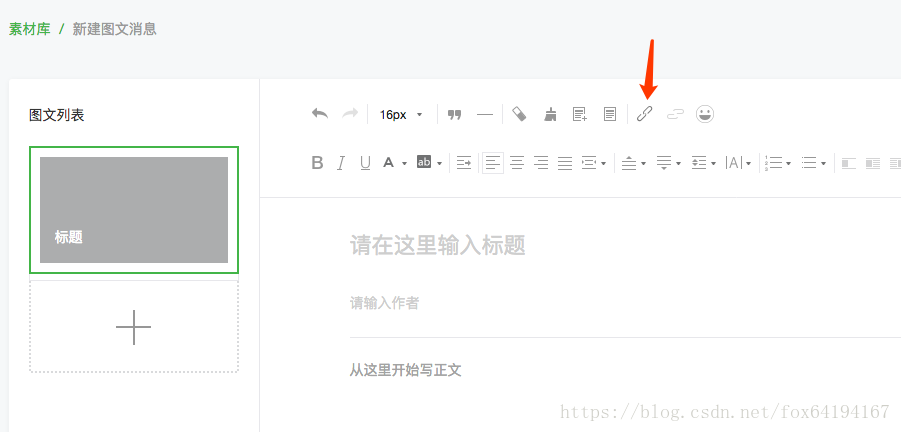
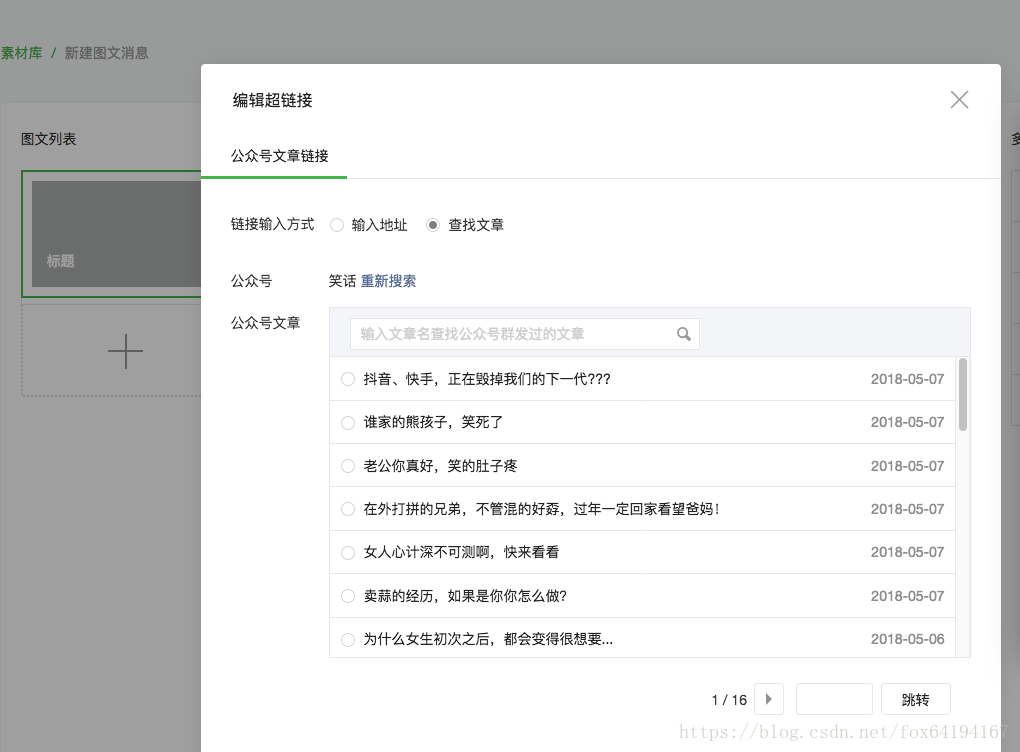
https://mp.weixin.qq.com/cgi-bin/appmsg?token=1219651365&lang=zh_CN&f=json&ajax=1&random=0.578791056424645&action=list_ex&begin=0&count=5&query=&fakeid=MjM5MDQ4MzU5NQ%3D%3D&type=9
主要类似这样的URL来请求一页的列表,有个token要替换掉自己的,然后是begin,0是第一页,5,10这样递增,random貌似没用,然后是fakeid貌似是一个公众号的id。然后要加上cookie
cookie看这篇文章《scrapy cookie》
# -*- coding: utf-8 -*-
import scrapy
import logging
import json
from WeiXinSpider.items import WeixinImgItem,WeixinspiderItem
class WeixinSpider(scrapy.Spider):
name = 'weixin'
# start_urls = ['https://mp.weixin.qq.com/cgi-bin/appmsg?token=1287313796&lang=zh_CN&f=json&ajax=1&random=0.43629248267984433&action=list_ex&begin=0&count=5&query=&fakeid=MjM5MDQ4MzU5NQ==&type=9']
url_temple = 'https://mp.weixin.qq.com/cgi-bin/appmsg?token=1219651365&lang=zh_CN&f=json&ajax=1&random=0.578791056424645&action=list_ex&begin={0}&count=5&query=&fakeid=MjM5MDQ4MzU5NQ%3D%3D&type=9'
def start_requests(self):
start_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?token=1219651365&lang=zh_CN&f=json&ajax=1&random=0.578791056424645&action=list_ex&begin=0&count=5&query=&fakeid=MjM5MDQ4MzU5NQ%3D%3D&type=9'
cookie = {}
headers = {
'Connection' : 'keep - alive',
'User-Agent' : 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36'
}
yield scrapy.Request(url=start_url,headers=headers,cookies=cookie)
def parseDetail(self, response):
item = WeixinspiderItem()
title = response.xpath('//h2[@id="activity-name"]/text()').extract_first()
body = response.xpath('//div[@id="js_content"]').extract_first()
# image_urls = response.xpath('//div[@id="meta_content"]/img/@scr')
image_urls = response.css('#js_content img::attr("data-src")').extract()
item['title'] = title
item['body'] = body
item['link'] = response.url
yield item
imageItem = WeixinImgItem()
imageItem['image_urls'] = image_urls
yield imageItem
pass
def parse(self, response):
result = response.body
jsresult = json.loads(result)
appMsgList = jsresult['app_msg_list']
for i in range(len(appMsgList)):
# title = appMsgList[i]['title']
link = appMsgList[i]['link']
yield response.follow(link, self.parseDetail)
next = 5
each_add = 5
for j in range(10):
next_url = self.url_temple.format(int(next + each_add * j))
yield response.follow(next_url, self.parse)
pass
middleware:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
import pymongo
import datetime
import logging
from scrapy.http import Request
class WeixinPipelineImage(ImagesPipeline):
def get_media_requests(self, item, info):
if 'image_urls' in item.keys():
for image_url in item['image_urls']:
head_url = image_url[0: image_url.rfind('/')]
last_name = head_url[head_url.rfind('/') + 1:len(image_url)]
yield Request(image_url, meta={'name': last_name})
def file_path(self, request, response=None, info=None):
today = datetime.datetime.now().strftime('big/%Y/%m/%d')
name = ''
if '.' in request.meta['name']:
name = request.meta['name'][0:request.meta['name'].rindex('.')]
else:
name = request.meta['name']
result = "%s/%s.jpg" % (today, name)
return result
pass
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
# if not image_paths:
# raise DropItem("Item contains no images")
return item
class WeixinDetailPipeline(object):
collection_name = 'weixin'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'test')
)
pass
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
if spider.name == 'weixin':
if 'title' in item.keys():
itemAlreadyHave = self.db[self.collection_name].find_one({'link': item['link']})
if itemAlreadyHave is None:
self.db[self.collection_name].insert_one(dict(item))
return item
pass
def close_spider(self, spider):
self.client.close()
passhttp://www.waitingfy.com/archives/3449
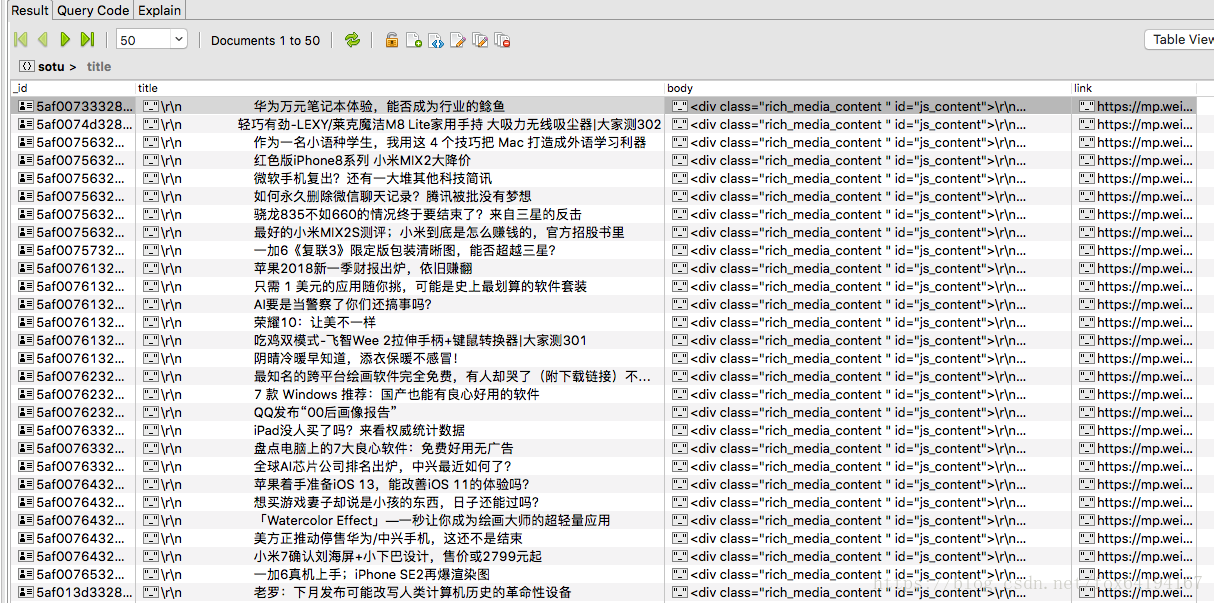
主要一个公众号的fakeid没法获取,要先搜索下。。。,然后是总页数的问题也还没解决。图片到也可以下载,还差个替换文章内容里的图片。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











