









读入excel数据结构:

import pandas as pd
import jieba
df = pd.read_excel('xuqiufenxi.xls')
print(df)
#新建一列存放分词结果
df['fenci'] = ''
#遍历每一行的文本,并将分词结果存入新建的列中
for i in range(len(df)):
print(i)
df['fenci'][i] = ' '.join(jieba.cut(df['需求内容'][i]))
print(df['fenci'][i])
#统计每个词出现的次数
word_count = {}
for word in df['fenci'][i].split():
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
# 将word_count字典转换成dataframe
word_count_df = pd.DataFrame(word_count.items(), columns=['word', 'count'])
# 按照count值降序排序
word_count_df = word_count_df.sort_values(by='count', ascending=False)
#输出excel
word_count_df.to_excel(f"{df['功能'][i]}.xlsx", index=False)
输出: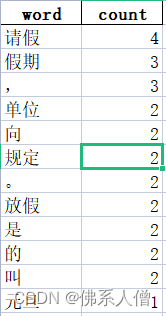
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









