







一.基础环境:
本文默认了你已经有了hadoop+Spark环境,且有一台linux客户机,配置好了各种环境变量,可执行Spark命令的。
以上环境有没完成的,自行去百度完成。
二.Spark Shell 交互
1.准备一个分析文件
word_test.txt(内容随意,我放的是英文诗),上传到hdfs,/tmp/hubg/目录下
hadoop fs -put word_test.txt /tmp/hubg/word_test.txt看一下文件内容:
hadoop fs -cat /tmp/hubg/word_test.txt
2.启动spark-shell,会看到scala交互窗口
spark-shell
3.指向一个文件来创建一个新的 Dataset:
val textFile = spark.read.textFile("/tmp/hubg/word_test.txt")
4.统计一下有多少行数据(换行符分割)。
textFile.count() // Number of items in this Dataset 
5.返回第一行数据。
textFile.first() // First item in this Dataset 
6.我们调用 filter 以返回一个新的 Dataset,它是文件中的 items 的一个子集。
val linesWithSpark = textFile.filter(line => line.contains("zoo"))
linesWithSpark.count()
7.Dataset actions(操作)和 transformations(转换)可以用于更复杂的计算。例如,统计单词数最多的行 :
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b) 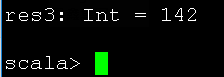
第一个 map 操作创建一个新的 Dataset,将一行数据 map 为一个整型值。在 Dataset 上调用 reduce 来找到最大的行计数。参数 map 与 reduce 是 Scala 函数(closures),并且可以使用 Scala/Java 库的任何语言特性。
8.调用java.lang.Mat函数声明,我们将定义一个 max 函数:
import java.lang.Math
textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))
9.word counts来一个
val wordCounts = textFile.flatMap(line => line.split(" ")).groupByKey(identity).count()
wordCounts.collect()
10.Spark 还支持 Pulling(拉取)数据集到一个群集范围的内存缓存中。linesWithSpark 数据集到缓存中
linesWithSpark.cache()
linesWithSpark.count()
就写这些了,更多用法大家看官网吧,如pyspark命令行,还有Spark API 来创建独立的应用程序Scala(SBT),Java(Maven)和 Python 等例子:















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









