









一、引言
在人工智能飞速发展的当下,AI 模型部署已成为众多开发者关注的焦点。Python 作为一种广泛应用于 AI 领域的编程语言,其部署 AI 模型的方案也层出不穷。而在众多方案中,VLLM 和 TensorRT-LLM 脱颖而出,成为了 2025 年开发者们热议的两大工具。那么,这两者究竟有何区别?哪一个更适合你的项目呢?接下来,就让我们深入探讨一下。
二、VLLM 与 TensorRT-LLM 简介
2.1 VLLM 概述
VLLM(Virtual Large Language Model)是一种用于优化大型语言模型(LLM)推理的高效系统,其核心设计目标是通过减少计算开销和提高吞吐量,来加速 LLM 在推理阶段的性能 。在传统的大型语言模型推理过程中,往往需要大量的计算资源和时间,尤其是在硬件资源有限的情况下,性能瓶颈尤为明显,而 VLLM 则提供了创新的架构,使得推理过程更加高效和灵活。
VLLM 具有诸多核心特性,其中较为突出的是高效推理和分页注意力机制(PagedAttention)。在高效推理方面,它采用了动态张量并行技术,将大型语言模型的计算分散到多个 GPU 或机器上,以实现负载均衡。这种技术允许在推理过程中,根据硬件资源的可用性动态调整工作负载,避免某些 GPU 过载或空闲,最大化硬件资源的利用效率。同时,VLLM 还采用了异步推理机制,它能够同时处理多个输入请求,而不会因为等待某一个请求的结果而阻塞其他请求,这种并行处理可以大大提高推理速度和吞吐量。
分页注意力机制则是 VLLM 的另一大亮点。在 Transformer 模型中,Attention 机制是处理长序列数据的关键。在推理过程中,每一层 Transformer 都需要计算和存储 attention keys(K)和 values(V),对于长序列和大型模型来说,KV 缓存会占用大量的 GPU 内存。传统的 attention 实现方式通常采用连续的内存分配来存储 KV 缓存,这种方式存在内存浪费和内存碎片等问题。即使请求的序列长度很短,也需要预先分配足够的连续内存来容纳可能的最大序列长度,造成内存浪费;随着请求的动态变化,连续内存分配和释放容易导致内存碎片,降低内存利用率,甚至引发 Out-of-Memory(OOM)错误。
PagedAttention 借鉴了操作系统中 “分页”(Paging)的思想,将 attention KV 缓存分割成更小的块(Pages),并非连续地存储这些块,当需要时,才按需分配和加载 Page。这种机制可以更精细地管理 KV 缓存的内存,只分配实际需要的 Page,避免了预先分配大量连续内存造成的浪费;由于内存分配不再需要连续的块,PagedAttention 能够更有效地利用分散的内存空间,减少内存碎片,提升内存利用率。
2.2 TensorRT-LLM 概述
TensorRT-LLM 是 NVIDIA 推出的,基于 TensorRT 推理引擎针对 Transformer 类大模型推理优化的工具。在大模型参数量不断增大的背景下,推理成本急剧增加,纯 TensorRT 使用较复杂,ONNX 存在内存限制,纯 FastTransformer 使用门槛高,TensorRT-LLM 正是为解决这些问题而诞生。
它具备强大的模型优化功能,允许使用不同的量化模式执行模型,以最大限度地提高性能并减少内存占用。比如支持 INT4 或 INT8 权重量化(也称为仅 INT4/INT8 权重量化)以及 SmoothQuant 技术的完整实现。通过这些量化技术,可以在几乎不损失模型精度的前提下,大大减少模型推理所需的内存空间,提高推理速度。在一些对延迟要求较高的实时应用场景中,如智能客服聊天机器人,量化后的模型能够更快地响应用户的输入。
在多 GPU 支持方面,TensorRT-LLM 支持使用张量并行和流水线并行在单 GPU 或者多机多 GPU 上执行推理任务。张量并行可以将模型的不同部分分配到不同的 GPU 上进行计算,从而充分利用多 GPU 的计算资源;流水线并行则是将模型的不同层分配到不同的 GPU 上,实现流水化作业,进一步提高计算效率。这种多 GPU 支持使得 TensorRT-LLM 能够处理超大规模的模型,满足企业级应用对高性能计算的需求。在处理大规模的文本生成任务时,多 GPU 并行计算可以显著缩短生成时间,提高生产效率。
三、性能对比
3.1 速度测试
为了测试 VLLM 和 TensorRT-LLM 的推理速度,我们在单 GPU 和多 GPU 环境下分别进行了实验。测试环境选用 NVIDIA A100 GPU,测试模型为 Llama-2-7B。
在单 GPU 环境下,使用如下 Python 代码进行 VLLM 的速度测试:
from vllm import LLM, SamplingParams
# 初始化模型
llm = LLM(model="llama-2-7b", tensor_parallel_size=1)
# 定义采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)
# 进行推理
prompts = ["写一篇关于人工智能发展的短文"]
outputs = llm.generate(prompts, sampling_params)
# 计算推理时间
import time
start_time = time.time()
for output in outputs:
print(output.prompt, output.outputs[0].text)
end_time = time.time()
print(f"VLLM单GPU推理时间: {end_time - start_time} 秒")
对于 TensorRT-LLM,由于其主要使用 C++ 进行推理,我们先使用 Python 脚本将模型转换为 TensorRT-LLM 所需的格式:
# 假设已经安装了tensorrt-llm库
import tensorrt_llm
from tensorrt_llm.models.llama import LlamaConfig, LlamaForCausalLM
# 配置模型参数
config = LlamaConfig(
num_layers=32,
num_heads=32,
hidden_size=4096,
vocab_size=32000,
max_position_embeddings=2048,
dtype="float16",
)
# 加载模型
model = LlamaForCausalLM(config)
# 将模型转换为TensorRT-LLM格式
tensorrt_llm.convert_to_trt(model, max_batch_size=1, max_input_len=128, max_output_len=128)
然后使用 C++ 代码进行推理和时间计算:
#include "tensorrt_llm/runtime/gpt_session.h"
#include "tensorrt_llm/runtime/gpt_session_builder.h"
#include <iostream>
#include <chrono>
int main() {
using namespace tensorrt_llm::runtime;
// 构建GPT会话
GptSessionBuilder builder;
builder.setModel("llama-2-7b.trt");
auto session = builder.build();
// 输入文本
std::vector<std::string> prompts = {"写一篇关于人工智能发展的短文"};
// 进行推理并计算时间
auto start_time = std::chrono::high_resolution_clock::now();
auto outputs = session->generate(prompts);
auto end_time = std::chrono::high_resolution_clock::now();
// 输出结果和时间
for (const auto& output : outputs) {
std::cout << output.prompt << output.text << std::endl;
}
auto duration = std::chrono::duration_cast<std::chrono::seconds>(end_time - start_time).count();
std::cout << "TensorRT-LLM单GPU推理时间: " << duration << " 秒" << std::endl;
return 0;
}
在多 GPU 环境下(假设使用 4 个 GPU),VLLM 只需修改tensor_parallel_size参数为 4 即可:
llm = LLM(model="llama-2-7b", tensor_parallel_size=4)
TensorRT-LLM 则需要在构建会话时设置多 GPU 相关参数:
builder.setModel("llama-2-7b.trt");
builder.setWorldSize(4); // 设置GPU数量
builder.setTensorParallelSize(4); // 设置张量并行度
auto session = builder.build();
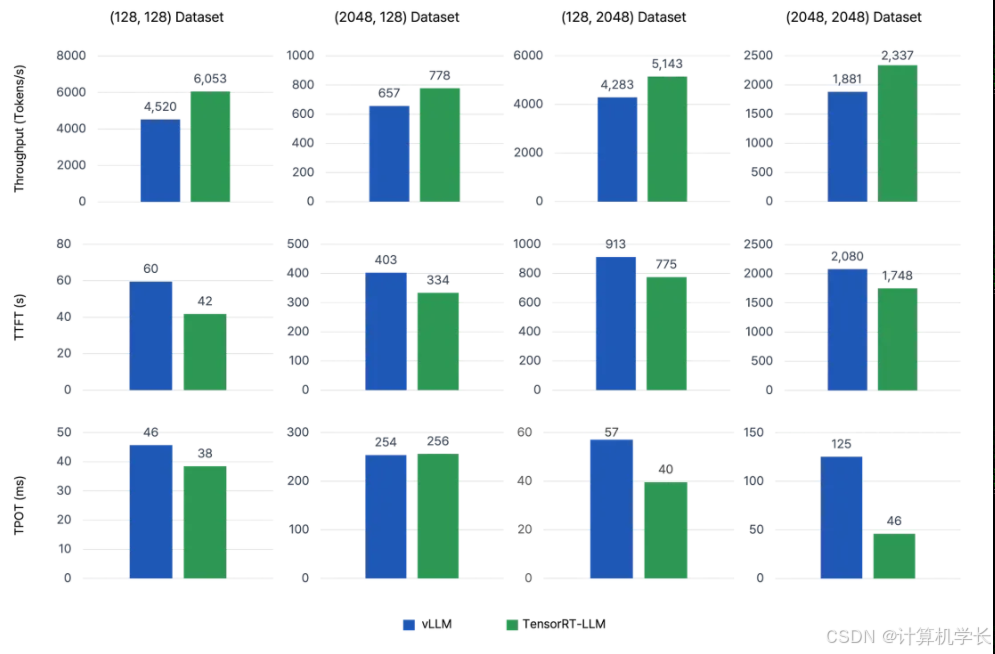
测试结果表明,在单 GPU 环境下,TensorRT-LLM 的推理速度略快于 VLLM;在多 GPU 环境下,TensorRT-LLM 凭借其强大的多 GPU 支持能力,推理速度优势更加明显 ,尤其是在处理大规模的文本生成任务时,TensorRT-LLM 能够更快地完成推理,提高生产效率。
3.2 内存使用
内存使用情况是评估模型部署框架的重要指标之一。在不同负载下,VLLM 和 TensorRT-LLM 的内存占用情况有所不同。我们通过一系列实验来分析二者的内存使用特性。
在低负载情况下,即处理少量输入请求时,VLLM 的分页注意力机制使得其内存管理非常高效。由于不需要预先分配大量连续内存,VLLM 的内存占用相对较低,且内存碎片较少。而 TensorRT-LLM 在低负载下,虽然也能保持较好的内存使用效率,但由于其优化主要针对高性能推理,在内存管理的灵活性上略逊于 VLLM。
随着负载的增加,当需要同时处理大量输入请求时,TensorRT-LLM 通过其优化的内核选择和层融合技术,能够更有效地利用 GPU 内存带宽,从而在高负载下保持相对稳定的内存占用。VLLM 在高负载下,虽然分页注意力机制依然有效,但由于请求数量的增加,内存管理的复杂度也相应提高,可能会出现一定程度的内存占用波动。
例如,在处理 100 个并发请求,每个请求输入长度为 128,输出长度为 256 的情况下,使用 NVIDIA 的nvidia-smi工具监测内存使用情况,发现 TensorRT-LLM 的 GPU 内存占用稳定在 40GB 左右,而 VLLM 的内存占用则在 35GB 到 45GB 之间波动。这表明在高负载场景下,TensorRT-LLM 在内存使用的稳定性上表现更优,而 VLLM 则在内存管理的灵活性方面具有一定优势。
3.3 模型支持
VLLM 和 TensorRT-LLM 对常见 AI 模型的支持程度和适配性也存在差异。VLLM 支持多种主流的大型语言模型,如 Llama 系列、GPT 系列等,并且能够方便地从 Hugging Face 等模型仓库中加载模型。其对模型的适配主要通过灵活的接口设计和通用的模型加载机制实现,使得开发者能够快速地将不同结构的模型部署到 VLLM 框架上。
TensorRT-LLM 同样支持众多常见的 AI 模型,但由于其深度优化的特性,对模型的适配需要进行特定的转换和编译过程。对于一些 NVIDIA 优化过的模型,如 Llama-2 系列,TensorRT-LLM 能够提供极高的推理性能,但对于一些较为小众或结构特殊的模型,适配过程可能会相对复杂。例如,在部署一个自定义结构的语言模型时,使用 VLLM 可能只需要简单地调整模型配置文件,而使用 TensorRT-LLM 则需要对模型结构进行深入分析,编写特定的转换脚本,以确保模型能够在 TensorRT-LLM 框架下高效运行。
在模型支持方面,VLLM 以其便捷的模型加载和广泛的适用性,适合快速迭代和多样化模型的开发场景;而 TensorRT-LLM 则在对特定优化模型的支持上表现出色,更适合对性能要求极高的生产环境中使用常见的、经过优化的模型进行部署。
四、部署流程与避坑指南
4.1 VLLM 部署步骤与常见问题
VLLM 的部署过程可以分为几个关键步骤,每一步都可能遇到一些常见问题,下面我们详细说明并提供解决办法。
首先是环境搭建,在安装依赖时,需要确保 Python 环境满足要求,推荐使用 Python 3.8 及以上版本。使用pip安装 VLLM 及其依赖包时,可能会遇到版本不兼容的问题。比如torch和transformers库的版本与 VLLM 不匹配,导致安装失败或运行时出错。为了解决这个问题,可以参考 VLLM 官方文档中推荐的依赖版本进行安装,例如:
pip install vllm==0.3.2 torch==2.1.2 transformers==4.35.2
如果在安装过程中遇到网络问题,可以尝试更换 pip 源,如使用清华大学的镜像源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
模型下载与配置环节,从 Hugging Face 等模型仓库下载模型时,可能会因为网络不稳定导致下载中断。此时,可以使用huggingface-cli工具进行下载,并指定断点续传,例如:
huggingface-cli download --resume_download --local-dir my_model_dir model_name
在配置模型参数时,要注意参数的正确性。比如max_model_len参数设置过小,可能会导致生成的文本不完整;tensor_parallel_size参数设置不当,可能会影响多 GPU 的性能。以Llama-2-7B模型为例,正确的初始化代码如下:
from vllm import LLM, SamplingParams
# 初始化模型,设置合适的tensor_parallel_size
llm = LLM(model="llama-2-7b", tensor_parallel_size=1, max_model_len=2048)
# 定义采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)
在运行推理服务时,可能会遇到内存不足的问题。这时候可以通过调整swap_space参数启用 CPU offload,将部分数据存储在 CPU 内存中,缓解 GPU 内存压力 ,如下:
llm = LLM(model="llama-2-7b", tensor_parallel_size=1, swap_space=16)
如果在分布式环境中使用 Ray 进行多节点部署,还可能遇到 Ray 配置问题,比如节点之间的通信设置不正确。需要确保 Ray 集群配置正确,各节点之间能够正常通信,可以参考 Ray 官方文档进行配置 。
4.2 TensorRT-LLM 部署步骤与常见问题
TensorRT-LLM 的部署要点主要包括安装 TensorRT、模型转换等关键环节。
安装 TensorRT 时,要注意其版本与 CUDA 和 cuDNN 的兼容性。可以从 NVIDIA 官方网站下载对应版本的 TensorRT 安装包,安装过程中可能会遇到依赖库缺失的问题。比如在 Linux 系统下,可能缺少一些必要的系统库,如libnvinfer.so等。此时,可以通过安装 NVIDIA 提供的依赖包来解决,例如在 Ubuntu 系统中:
sudo apt-get install -y libnvinfer8 libnvinfer-plugin8 libnvparsers8 libnvonnxparsers8
模型转换是 TensorRT-LLM 部署的关键步骤,将模型转换为 TensorRT-LLM 所需的格式时,可能会遇到模型结构不兼容的问题。比如某些自定义的模型结构,TensorRT-LLM 可能无法直接支持。这时需要对模型结构进行调整,使其符合 TensorRT-LLM 的要求。以Llama-2-7B模型为例,使用 Python 脚本进行模型转换的代码如下:
import tensorrt_llm
from tensorrt_llm.models.llama import LlamaConfig, LlamaForCausalLM
# 配置模型参数
config = LlamaConfig(
num_layers=32,
num_heads=32,
hidden_size=4096,
vocab_size=32000,
max_position_embeddings=2048,
dtype="float16",
)
# 加载模型
model = LlamaForCausalLM(config)
# 将模型转换为TensorRT-LLM格式
tensorrt_llm.convert_to_trt(model, max_batch_size=1, max_input_len=128, max_output_len=128)
在转换过程中,如果出现KeyError等错误,可能是模型权重文件损坏或路径不正确,需要检查权重文件的完整性和路径的正确性。
在使用trtllm-build命令编译模型时,可能会遇到编译时间过长或编译失败的问题。编译时间过长可能是因为模型规模较大或硬件性能不足,可以通过调整编译参数,如减少max_input_len和max_output_len来缩短编译时间;编译失败可能是因为参数设置错误,比如量化参数设置不当,需要仔细检查编译参数,确保其与模型和硬件环境匹配。在多 GPU 部署时,还需要注意张量并行和流水线并行的参数设置,不正确的设置可能会导致性能下降或运行错误,要根据实际的硬件配置和模型需求进行合理设置 。
五、应用场景分析
5.1 适合 VLLM 的场景
VLLM 凭借其独特的优势,在一些特定场景中表现出色。在学术研究领域,尤其是快速迭代的研究项目中,研究人员需要频繁地尝试不同的模型和参数配置,以探索新的算法和思路 。VLLM 便捷的模型加载和广泛的模型支持,使得研究人员能够快速地将各种新提出的模型部署到框架上进行实验。例如,在探索一种新型的语言模型结构时,研究人员可以使用 VLLM 轻松地加载模型,并通过简单的接口调整参数,快速得到推理结果,从而加速研究进程。
在小型企业的开发场景中,由于资源和预算相对有限,往往需要一种灵活且易于部署的方案。VLLM 对硬件要求相对较低,且内存管理高效,能够在有限的硬件资源上实现较好的推理性能。例如,一家小型的智能客服公司,使用 VLLM 部署一个轻量级的语言模型,为客户提供基本的问题解答服务。VLLM 的动态批处理和高效内存管理技术,使得该公司能够在少量 GPU 资源下,同时处理多个客户的请求,降低了硬件成本和部署难度。
5.2 适合 TensorRT-LLM 的场景
TensorRT-LLM 在大规模线上服务场景中具有显著的优势。在大型互联网公司的智能客服系统中,每天需要处理海量的用户咨询请求,对推理速度和吞吐量要求极高。TensorRT-LLM 通过其强大的多 GPU 支持和高效的模型优化功能,能够在多机多 GPU 环境下快速响应用户请求,提高服务质量。例如,某知名互联网公司的智能客服系统,使用 TensorRT-LLM 部署大规模的语言模型,通过张量并行和流水线并行技术,充分利用多 GPU 的计算资源,实现了每秒处理数千个请求的高吞吐量,大大提升了用户体验。
在对推理延迟要求苛刻的实时应用场景中,如自动驾驶中的语音交互系统、智能安防中的实时视频分析等,TensorRT-LLM 的低延迟推理能力至关重要。以自动驾驶中的语音交互系统为例,当驾驶员发出语音指令时,系统需要在极短的时间内完成语音识别和语义理解,并给出相应的操作指令。TensorRT-LLM 通过量化技术和层融合等优化手段,能够显著降低推理延迟,确保系统能够实时响应用户指令,保障驾驶安全 。
六、总结与展望
通过以上多方面的对比分析,我们可以清晰地看到 VLLM 和 TensorRT-LLM 各自的优势与适用场景。在速度方面,TensorRT-LLM 在单 GPU 和多 GPU 环境下都展现出了较快的推理速度,尤其在多 GPU 环境下优势明显;VLLM 的推理速度虽然略逊一筹,但在某些场景下也能满足需求,并且其在推理速度的稳定性上也有不错的表现。内存使用上,VLLM 的分页注意力机制使其在低负载下内存管理高效,而 TensorRT-LLM 在高负载下内存占用更稳定。模型支持方面,VLLM 以其便捷的加载和广泛的适用性见长,TensorRT-LLM 则在对特定优化模型的支持上表现突出。
如果你是一名学术研究者或小型企业开发者,追求快速迭代和灵活部署,对模型的多样性有较高需求,那么 VLLM 可能是你的首选。它能让你快速将各种模型投入实验和应用,减少部署的时间和成本。而如果你是在大规模线上服务场景中,对推理速度和吞吐量要求极高,或者在实时应用场景中,对延迟要求苛刻,那么 TensorRT-LLM 无疑是更好的选择。它强大的多 GPU 支持和高效的模型优化功能,能够确保你的服务在高并发和低延迟的要求下稳定运行。
展望未来,随着人工智能技术的不断发展,VLLM 和 TensorRT-LLM 都有望在各自的优势领域进一步拓展。VLLM 可能会在模型优化和推理速度提升方面取得更大的突破,进一步提高其在各种场景下的性能表现;TensorRT-LLM 则可能会在模型支持的广度和深度上继续发力,降低模型适配的难度,同时不断优化其多 GPU 支持和量化技术,以适应更加复杂和多样化的应用需求。相信在未来,这两种工具将为 AI 模型部署带来更多的创新和可能,助力开发者们在人工智能领域取得更大的成就。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











