




 本文深入解析Spark中的核心概念——弹性分布式数据集(RDD),探讨其创建、缓存、容错策略及分布式特性。介绍如何从本地集合或外围系统创建RDD,阐述RDD的容错机制,包括重复计算、缓存和Checkpoint,以及宽依赖和窄依赖的区别。
本文深入解析Spark中的核心概念——弹性分布式数据集(RDD),探讨其创建、缓存、容错策略及分布式特性。介绍如何从本地集合或外围系统创建RDD,阐述RDD的容错机制,包括重复计算、缓存和Checkpoint,以及宽依赖和窄依赖的区别。
RDD的概述
俯视整个Spark程序,所有Spark的Application都包含一个Driver程序,该程序是用户的主函数以及在集群中执行各种各样的并行操作。Spark中提出了一个核心的概念 resilient distributed dataset 简称 RDD,RDD是一个并行的分布式集合 ,该集合数据可以跨节点存储,所有的RDD操作都是在集群的计算节点中并行的执行。RDD可以直接通过Hadoop的文件系统创建(或者所有Hadoop支持的文件系统创建),也可以通过定义在main函数中定义的Scala集合创建。Spark可以将RDD中的数据缓存在内存中,这样在后续的分布式计算可以重复使用,提升程序运行效率,其次RDD可在计算节点故障的时候进行故障恢复。(RRD创建/RDD缓存/RDD故障恢复)
RDD的创建
RDD是一个并行的带有容错的分布式数据集,创建一个RDD的方式有两种方式
- 从Driver中将Scala的本地集合 并行化为一个RDD;
- 可以同外围系统的数据集创建,一般需要使用Hadoop的InputFormat
集合创建RDD
val lines=List("this is a demo","hello world","good good")
val linesRDD:RDD[String]=sc.parallelize(lines,3)
注:这里的3表示将集合分为3个区域,将数据均匀分散,用户还可以使用那可RDD创建。
val lines=List("this is a demo","hello world","good good")
val linesRDD:RDD[String]=sc.makeRDD(lines,3)
外围系统数据
textFile
val linesRDD:RDD[String] = sc.textFile("file:///D:/demo/words",10)
这里的file://表示读取本地文件,如果需要读取HDFS,请指定为hdfs://,如果读取的是来自HDFS上的文本数据,一般不需要指定分区数,如果用户不指定分区数,文件并行加载的并行度默认等于文件的块的数目,用户如果指定了分区数,该分区必须大于目标文件的block数目。
newAPIHadoopRDD(HBase)
- 引入相关依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.9.2</version> </dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.4</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.4</version>
</dependency>
- 创建应用程序
package com.hw.demo04
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HConstants
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @aurhor:fql
* @date 2019/9/25 19:28
* @type:
*/
object RDD_hnase {
def main(args: Array[String]): Unit = {
//1.创建SparkContext
val sparkConf = new SparkConf()
sparkConf.setAppName("wordCount")
sparkConf.setMaster("local[6]")
val sc = new SparkContext(sparkConf)
//2,创建分布式集合RDD细化
val hconf = new Configuration()
hconf.set(HConstants.ZOOKEEPER_QUORUM,"CentOS") //指定与Zookeeper的连接
hconf.set(TableInputFormat.INPUT_TABLE,"baizhi:t_user")
val userRDD:RDD[(ImmutableBytesWritable,Result)] = sc.newAPIHadoopRDD(hconf,classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])
userRDD.map(t=>{
val key = Bytes.toString(t._1.get())
val name=Bytes.toString(t._2.getValue("cf1".getBytes(),"name".getBytes()))
(key,name)
}).collect().foreach(println)
sc.stop();
}
}
RDD剖析
RDD是一个弹性的、分布式、数据集,弹性强调的RDD的容错。默认情况下有三种容错策略
- RDD重复计算-默认策略,一旦计算过程中系统出错了,系统可以根据RDD的转换关系去追溯上游RDD,逆推出RDD计算过程。之所以RDD能够逆推出上游RDD(父RDD),主要是因为Spark会记录RDD之间依赖关系(RDD血统)。
- 由于重复计算成本较高,因此Spark提供了缓存机制,用于存储RDD计算的中间结果,有利于在故障时期能够快速状态恢复,提升计算效率,如果某些计算需要重复使用也可以使用RDD缓存机制去优化。
- 由于缓存存在时效问题,如果当RDD缓存失效了,一旦故障,系统依然需要重复计算。因此针对一些比较耗时且计算成本比较高的计算,Spark提供了一种更安全可靠机制称为Checkpoint,缓存一般具有时间限制,长时间不使用会失效,但是checkpoint不同,checpoint机制会将RDD的计算结果直接持久化到磁盘中,被checpoint的数据,会一直持久化到磁盘中,除非手动删除。
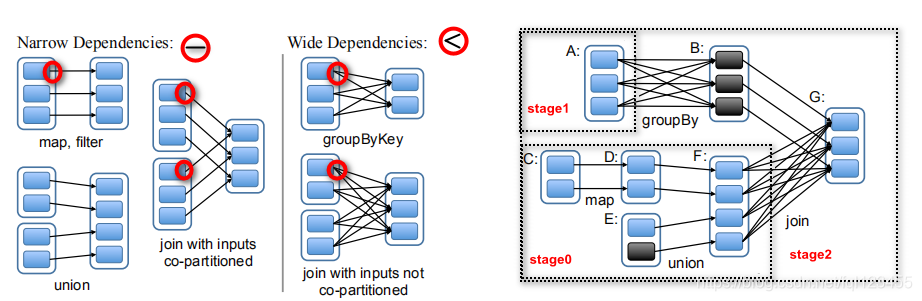
分布式:强调的是Stage划分名,Spark会尝试将一个任务拆分成若干个阶段,所有的计算都会按照State划分,有条不紊的执行。Spark在对任务划分时根据RDD间相互依赖关系划分任务的阶段。Spark中RDD的依赖关系称为RDD的血统-lineage,RDD血统依赖又分两种依赖形式宽依赖/窄依赖如果遇到窄依赖系统会尝试将RDD转换归并为一个Stage、如果是宽依赖Spark会产生新的Satge。
数据集:强调的是RDD操作简单和易用性,操作并行集合就等价于操作Scala的本地集合这么简单

上诉代码通过textFile创建RDD并且指定分区数,如果不指定系统默认会按照HDFS上的Block的数目计算分区,该参数不能小于Block的数目。然后使用可flatMap,map算子对分区数据做转换,不难看出Spark将textFile->flatMap->map规划为了一个State0,在执行到reduceByKey转换的时候将开始又划分出State1在执行到collect动作算子的时候,Spark任务提交,并且内部通过DAGScheduler计算出了state0和state1两个状态。
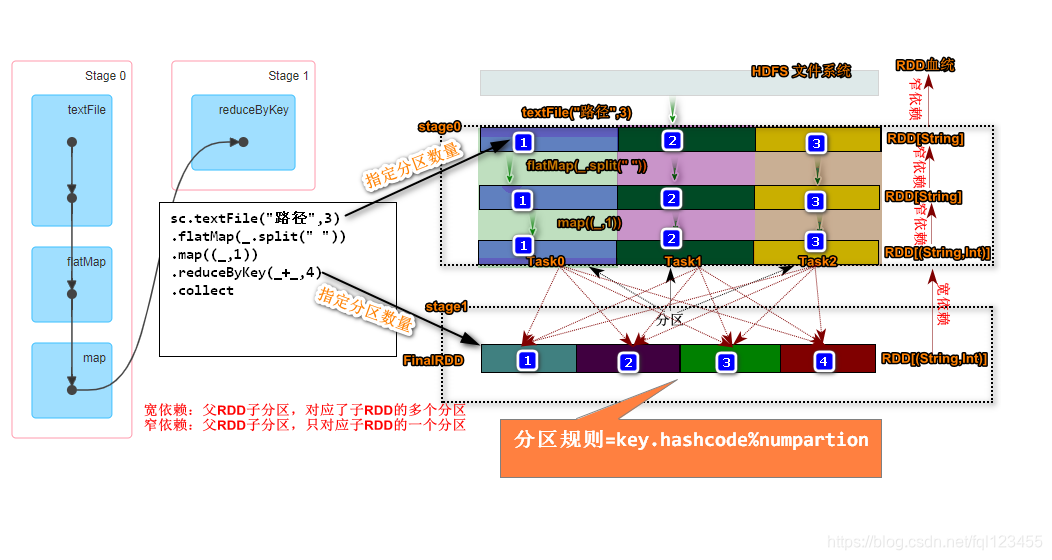
RDD容错

上图中描述了一个程序猿起源变化的过程,我们可以近似的理解类似于RDD的转换过程,Spark的计算本质就是对RDD做各种转换,由于RDD是一个不可变带有分区只读的集合,因此每次的转换都需要上一次的RDD数据作为本次转换的输入,因此RDD的lineage描述的是RDD间的相互依赖关系。为了保证RDD中数据的健壮性,RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中转换过来的。Spark将RDD之间的关系归类为宽依赖和窄依赖。Spark会根据Lineage存储的RDD的依赖关系对RDD计算做故障容错,目前Saprk的容错策略根据RDD依赖关系重新计算、RDD做Cache、RDD做Checkpoint手段完成RDD计算的故障容错。
宽依赖|窄依赖
RDD在Lineage依赖方面分为两种Narrow Dependencies与Wide Dependencies用来解决数据容错的高效性。Narrow Dependencies是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于子RDD的一个分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。Wide Dependencies父RDD的一个分区对应一个子RDD的多个分区。Spark在任务的提交的时候会调用DAGScheduler方法更具最后一个RDD逆向推导出任务的阶段(根据宽、窄依赖)。
RDD缓存
缓存是一种RDD计算容错的一种手段,程序在RDD数据丢失的时候,可以通过缓存快速计算当前RDD的值,而不需要反推出所有的RDD重新计算,因此Spark在需要对某个RDD多次使用的时候,为了提高程序的执行效率用户可以考虑使用RDD的cache。
//1.创建SparkContext
val sparkConf = new SparkConf()
.setAppName("wordcount")
.setMaster("local[6]")
val sc = new SparkContext(sparkConf)
//2.创建分布式集合RDD -细化
val lines:RDD[String] = sc.textFile("file:///D:/demo/words")
val cacheRDD = lines.flatMap(_.split(" "))//缓存数据
.map((_, 1))
.persist(StorageLevel.MEMORY_ONLY)
//执行聚合
cacheRDD.reduceByKey(_ + _, 4).collect()
var start=System.currentTimeMillis()
for(i <- 0 to 100){//测试时间
cacheRDD.reduceByKey(_ + _, 4).collect()
}
var end=System.currentTimeMillis()
//5.释放资源
sc.stop()
println("总耗时:"+(end-start))
清除缓存
cacheRDD.unpersist()
思考,面对大规模数据集,直接将RDD数据缓存在内存中是否会导致内存溢出?
默认Spark的cache方法是用内存缓存的RDD中数据,这样可以极大提升程序运行效率,但是面对大规模数据集合可能导致计算的节点产生OOM(Out of Memory),如果数据经过转换后数据量级依然很大,这个时候不建议是用cache方法,Spark提供下一的存储机制。
rdd#cache <==> rdd.persist(StorageLevel.MEMORY_ONLY)
默认情况下,用户是用cache就等价于使用 rdd.persist(StorageLevel.MEMORY_ONLY),事实上Spark还提供其它的存储策略,用于节省内存空间以及缓存数据的备份。
StorageLevel.MEMORY_ONLY # 直接将RDD只存储到内存,效率高,占用空间大
StorageLevel.MEMORY_ONLY_2 # 直接将RDD只存储到内存,效率高,占用空间大,并且存储两份
StorageLevel.MEMORY_ONLY_SER # 将RDD先进行序列化,效率相对较低,占用空间稍微小
StorageLevel.MEMORY_ONLY_SER_2 # 将RDD先进行序列化,效率相对较低,占用空间稍微小,并且存储两份
StorageLevel.MEMORY_AND_DISK
StorageLevel.MEMORY_AND_DISK_2
StorageLevel.MEMORY_AND_DISK_SER
StorageLevel.MEMORY_AND_DISK_SER_2 # 不确定情况下,一般使用该种缓存策略
StorageLevel.DISK_ONLY # 基于磁盘存储
StorageLevel.DISK_ONLY_2
StorageLevel.DISK_ONLY_SER
StorageLevel.DISK_ONLY_SER_2


















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









