







现在有一个filter统计的服务端业务逻辑的耗时统计日志,格式如下
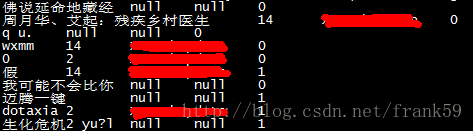
第一列是关键字,第二列和第三列是其它参数,第四列是耗时,我只关心第四列。
目的是统计出服务端的耗时情况(耗时长短,以及所占比例),以便发现服务端是否有可以再逻辑上进行优化的空间。
首先是取出关心的数据:
由于这个日志并不完全是上图显示的格式,其中有不少的记录格式较为混乱,所以最先做的就是排除不规则的格式,选了个简单的方法:
awk '{if($2!="" && $3!="" && $4!=""){print $NF}}' request_cost.log | grep -E "^[0-9]+$" |这样出来的结果就是
0
0
0
0
1
0
0
1
1接下来是统计以及算百分比:
awk '{a[$1]++;s+=1}END{for (j in a) printf "%s %.2f%\n",j,a[j]*100/s}'所以最终的指令是:
awk '{if($2!="" && $3!="" && $4!=""){print $NF}}' request_cost.log | grep -E "^[0-9]+$" | awk '{a[$1]++;s+=1}END{for (j in a) printf "%s %.2f%\n",j,a[j]*100/s}' > request_result.log输出结果:
sort -k 2 -gr request_result.log > sort_request_result.log结果:
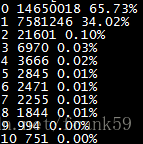
耗时0ms和1ms的就占了绝大部分,没啥优化空间了。















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









