







google公司的三篇论文
资源链接:http://blog.csdn.net/zhangt85/article/details/43152843
GFS: Google file system(谷歌公司的文件系统),谷歌分布式文件系统,HDFS(Hadoop Distributed File System)是基于GFS的开源实现,举例,百度云盘
大数据存储面临两个问题,第一,数据量太大,硬盘不够大,第二,数据不够安全,在HDFS中解决第一个问题的方法,多块硬盘存储数据,多个数据节点来存储数据,解决第二个问题的方法,数据冗余
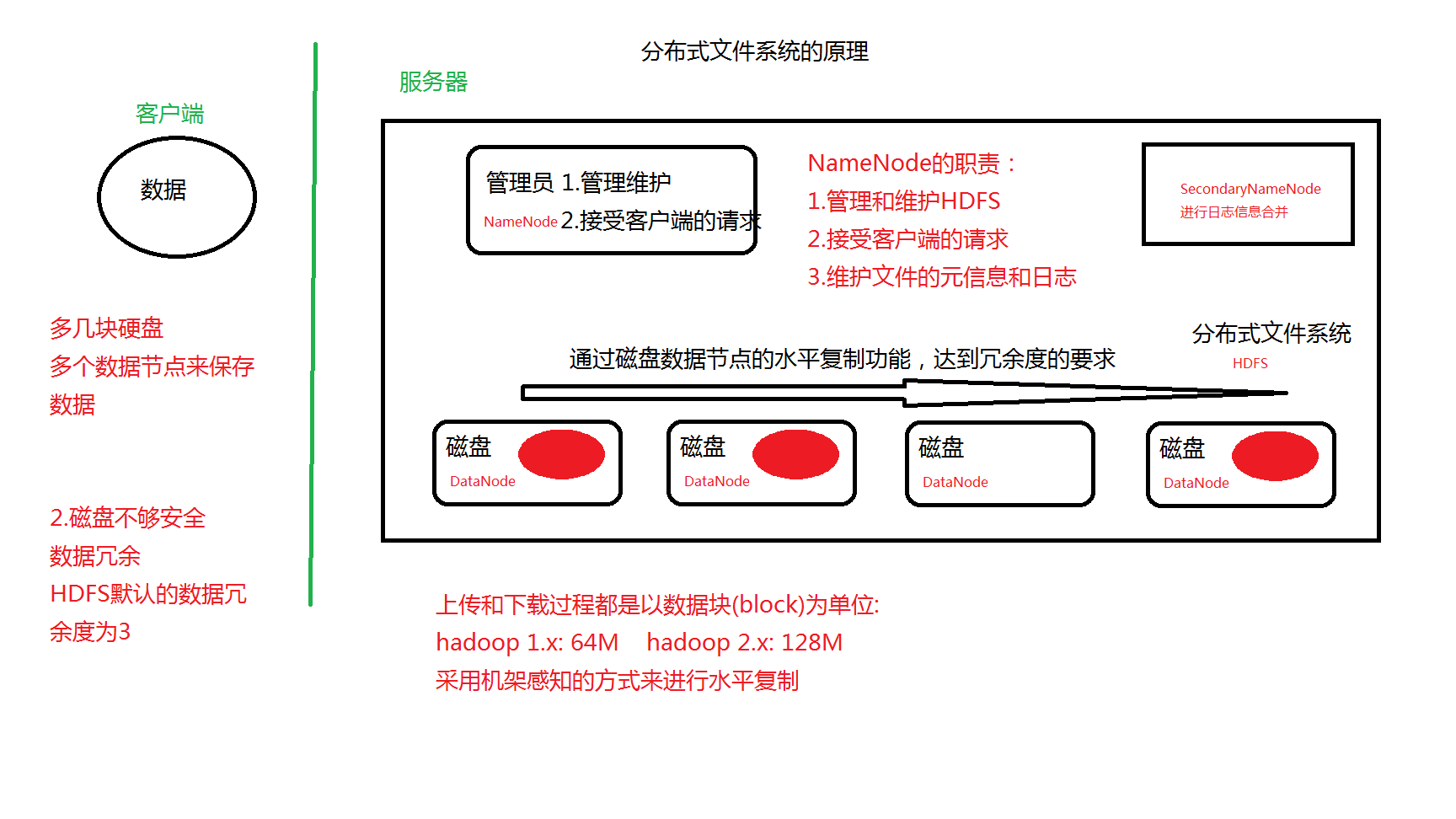
HDFS体系结构中存在三种角色:NameNode, DataNode, SecondaryNameNode, NameNode(名称节点)主要职责是管理和维护 整个HDFS体系,接受客户端的请求,维护文件系统的元信息和日志,DataNode(数据节点)主要职责是存储数据,SecondaryNameNode(第二名称节点)主要职责是合并元信息与日志,这里在后面会详细介绍
MapReduce:大数据计算模型,问题来源于PageRank问题(搜索排名问题),核心思想分为两个阶段,先拆分(Map), 后合并(Reduce)

一个MapReduce任务就是一个Job, 由Map任务和Reduce任务组成,整个MapReduce过程有四对输入输出,都是键值对key-value形式,Map的输出就是Reducer的输入,并且输入输出类型都要实现hadoop的序列化(实现Writable接口),类似于java中的序列化(数据传输),具体过程后面MapReduce程序会谈到
BigTable:大表,NoSql数据库Hbase,大表思想违背了关系型数据库范式的要求,大表当中存在数据的冗余,通过牺牲空间来提高存储时间,大表中可以将所以数据存入一张表中

Hbase是一种面向列的NoSql数据库,而Oracle是面向行的数据库,Hbase在空间上有所浪费,但查询效率很高(面向列族查询),所以适合作查询操作,oracle数据库在增删改的效率会更高















 4804
4804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









