







介绍hadoop环境的搭建
hadoop安装模式有三种,本地模式,伪分布模式,全分布模式,本地模式不做介绍,本次介绍hadoop伪分布模式的搭建(一台linux虚拟机),后面介绍全分布模式的搭建(至少三台linux虚拟机)
安装前的准备工作,关闭防火墙,JDK的安装,设置主机名

使用winscp工具将hadoop安装包上传到linux的tools目录下(以后组件安装包都上传到tools下)

进入tools目录,将hadoop解压到training目录下(以后组件解压目录都为training目录)

进入解压后的hadoop目录,看到如上的目录结构
bin目录:存放hadoop所有的可执行文件
etc目录:存放hadoop所有的配置文件
sbin目录:存放hadoop集群的管理命令目录
share目录:存放hadoop所依赖的jar包和公共的jar包
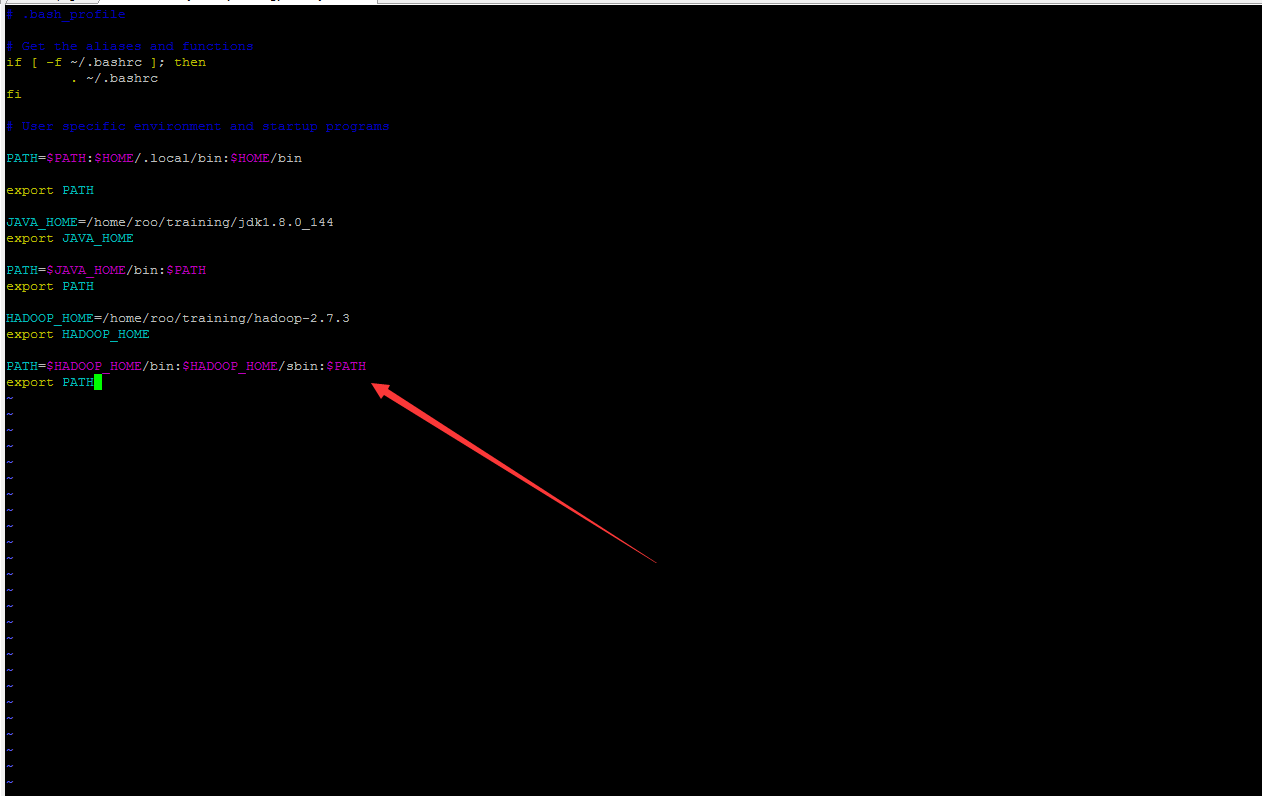

设置hadoop环境变量(与设置jdk环境变量类似),先使用vim编辑.bash_profile隐藏文件,添加
HADOOP_HOME=/home/roo/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
保存退出,source ~/.bash_profile使环境变量生效
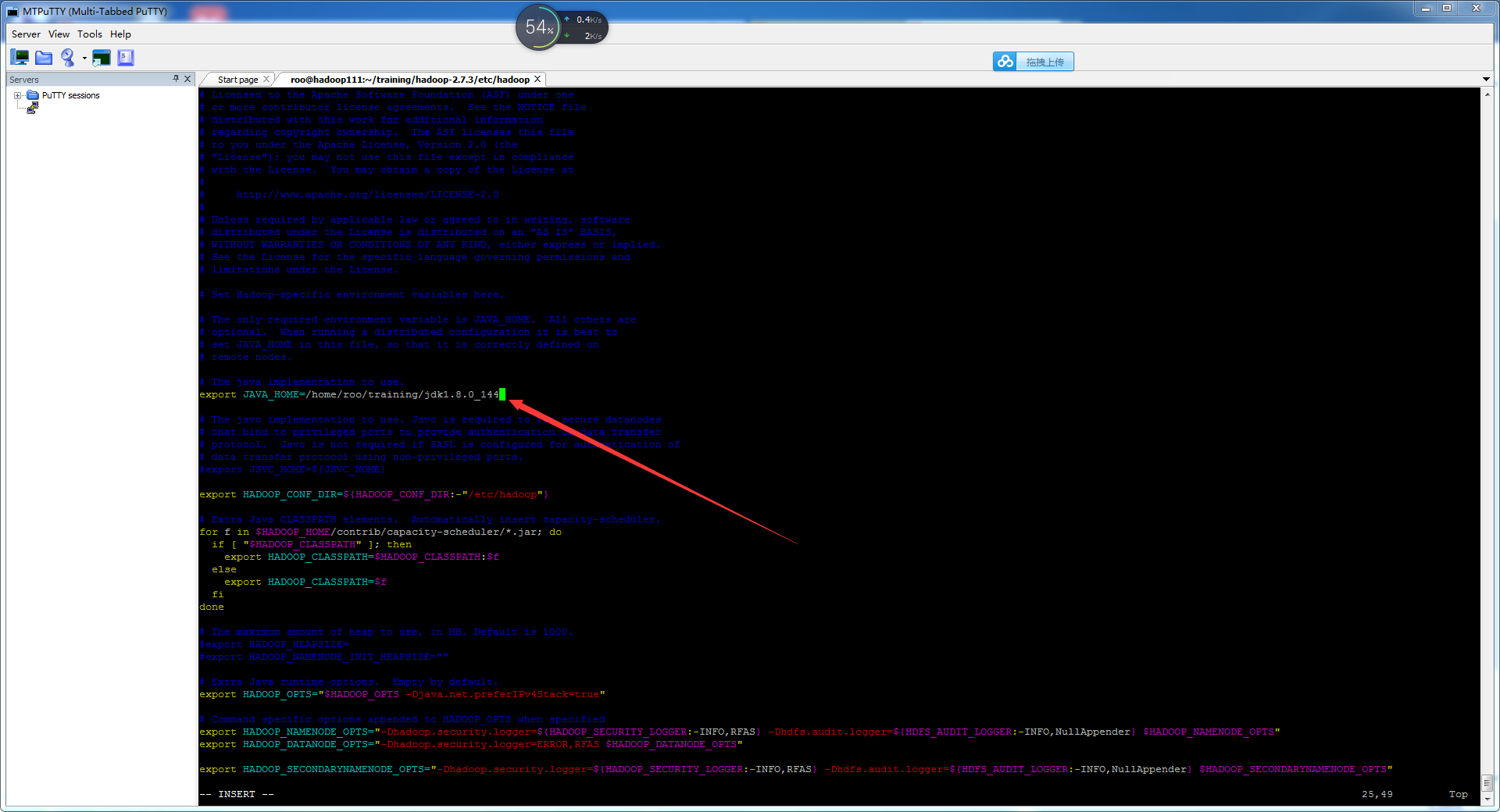
首先进入etc/hadoop目录,更改hadoop-env.sh,将java_home路径更改成本机上的java_home路径


接下来进入到/etc/hadoop目录,更改hdfs-site.xml配置文件,hadoop中配置文件都是以xml格式存放的,添加
<property>
<name>df.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
第一个属性dfs.replication表示数据的冗余程度,这里设置为1,伪分布式,一个名称节点,一个数据节点,第二个属性dfs.permissions表示是否开启hdfs用户权限的检查,这里设置为false,表示不开启检查,保存退出


接下来更改core-site.xml配置文件,添加
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.145.111:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/roo/training/hadoop-2.7.3/tmp</value>
</property>
第一个属性fs.defaultFS表示hadoop管理员namenode的位置,默认为hdfs://<localhost>:9000 端口9000表示RPC(远程过程调用)的端口,关于RPC,后面会详细介绍,第二个属性hadoop.tmp.dir表示数据存放在linux上的保存的位置,这里设置为hadoop的home目录下的tmp目录(tmp目录要事先存在,不存在的话mkdir tmp创建一个目录),更改完毕,保存退出


接下来更改mapred-site.xml, 事先不存在mapred-site.xml文件,但可以看到类似template的模板文件,使用cp命令拷贝一份(cp mapred-site.xml.template mapred-site.xml) 然后编辑mapred-site.xml文件,加入
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<property>
属性mapreduce.framework.name表示mapreduce程序运行时的框架的名称,为yarn, hadoop2以后的mapreduce程序都是提交到yarn平台上去运行


接下来更改yarn-site.xml配置文件,添加
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.145.111</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
第一个属性表示,yarn的主节点resurcemanager的主机名地址,只有一台虚拟机,值为本机的IP地址,第二个属性表示,yarn的从节点nodemanager运行mapreduce程序的方式。

接下来进行hdfs的格式化,hdfs namenode -format, 如果看到
INFO common.Storage: Storage directory /home/roo/training/hadoop-2.7.3/tmp/dfs/name has been successfully formatted.
表明HDFS格式化成功了
然后可以启动hdfs环境了,有三种命令start-dfs.sh只启动dfs,start-yarn.sh只启动yarn平台,start-all.sh两者都启动

然后使用start-all.sh启动,启动过程中需要输入四次yes,输入四次密码,比较麻烦(后面会介绍ssh免密码登录),然后用jps查看进程,可以看到五个节点都启动成功了,表明本机的hadoop的伪分布式环境搭建完成,如果将节点停掉可以,用stop-all.sh来停止节点,期间又要输入四次密码















 5611
5611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









