







一,环境信息
CDH集群,Cloudera Manager5安装部署CDH5.X详细请见:http://blog.csdn.net/freedomboy319/article/details/44804721
二,在CDH5.3.2中配置运行Spark SQL的Thrift Server
1,root用户登录CDH5.3.2集群中的某一个节点
2,cd /opt/cloudera/parcels/CDH/lib/spark/sbin 执行./start-thriftserver.sh –help
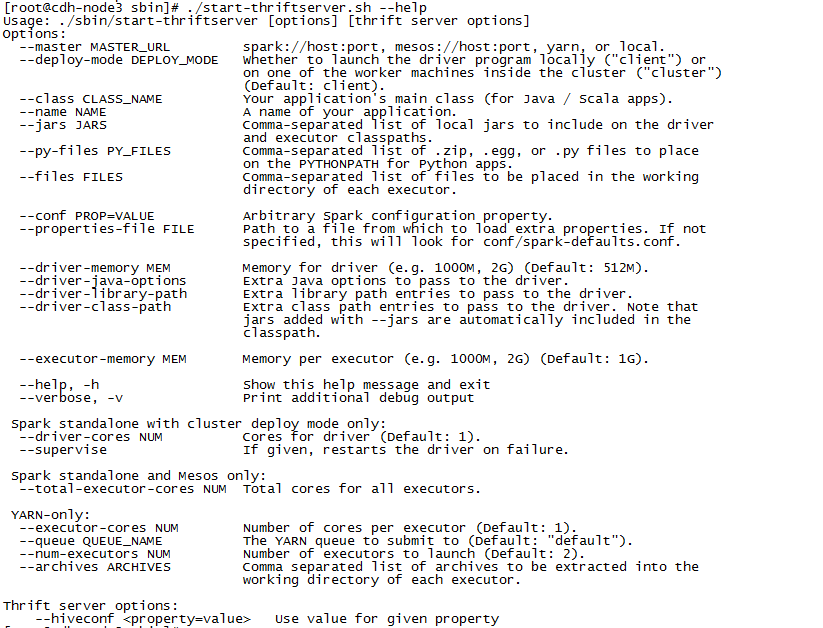
3,执行./start-thriftserver.sh
4,进入/opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/spark/logs目录,查看日志文件spark-root-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-cdh-node3.grc.out,发现报如下错:
Spark Command: /usr/java/jdk1.7.0_67-cloudera/bin/java -cp
::/opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/spark/conf
:/opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/spark/lib/spark-assembly.jar
:/etc/hadoop/conf:/opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/hadoop/client/*
......
:/opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/spark/lib/jline.jar
-XX:MaxPermSize=128m -Xms512m -Xmx512m org.apache.spark.deploy.SparkSubmit --class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 spark-internal
========================================
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hive/service/server/HiveServer2
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:800)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
5,原因是缺失jar包。解决方法:
1)cd /opt/cloudera/parcels/CDH/lib/spark/bin 目录。
2)vi compute-classpath.sh 文件,在此文件中最后添加如下hive的jar包。
CLASSPATH="$CLASSPATH:/opt/cloudera/parcels/CDH/lib/hive/lib/*"6,执行./start-thriftserver.sh
7,进入/opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/spark/logs目录,查看日志文件spark-root-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-cdh-node3.grc.out,发现报如下错:
15/06/02 16:32:13 INFO HiveThriftServer2: HiveThriftServer2 started
15/06/02 16:32:13 ERROR ThriftCLIService: Error:
org.apache.thrift.transport.TTransportException: Could not create ServerSocket on address 0.0.0.0/0.0.0.0:10000.
at org.apache.thrift.transport.TServerSocket.<init>(TServerSocket.java:93)
at org.apache.thrift.transport.TServerSocket.<init>(TServerSocket.java:79)
at org.apache.hive.service.auth.HiveAuthFactory.getServerSocket(HiveAuthFactory.java:229)
at org.apache.hive.service.cli.thrift.ThriftBinaryCLIService.run(ThriftBinaryCLIService.java:89)
at java.lang.Thread.run(Thread.java:745)
15/06/02 16:32:13 INFO SparkUI: Stopped Spark web UI at http://cdh-node3.grc:4040
15/06/02 16:32:13 INFO DAGScheduler: Stopping DAGScheduler
15/06/02 16:32:14 INFO MapOutputTrackerMasterActor: MapOutputTrackerActor stopped!
15/06/02 16:32:14 INFO MemoryStore: MemoryStore cleared
15/06/02 16:32:14 INFO BlockManager: BlockManager stopped
15/06/02 16:32:14 INFO BlockManagerMaster: BlockManagerMaster stopped8,原因是与Hive中的HiveServer2 进程端口冲突。
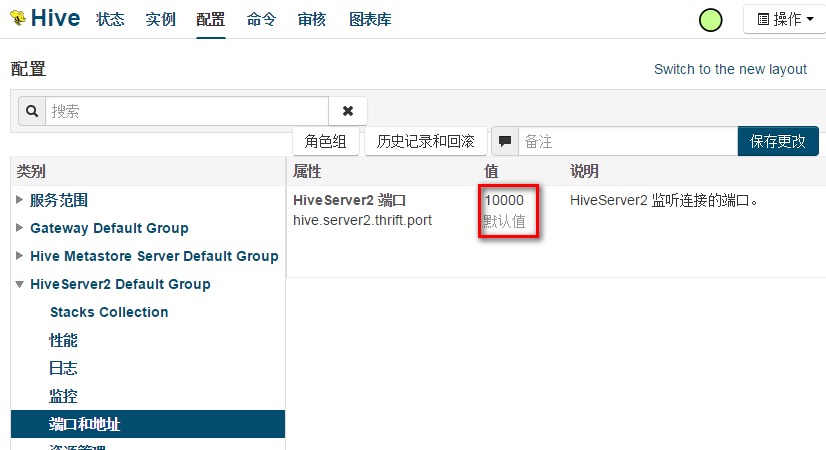
9,解决方法,在/opt/cloudera/parcels/CDH/lib/spark/conf目录下,添加hive-site.xml文件,此文件的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://cdh-node3.grc:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
<description>Port number of HiveServer2 Thrift interface.
Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>cdh-node3.grc</value>
<description>Bind host on which to run the HiveServer2 Thrift interface.
Can be overridden by setting $HIVE_SERVER2_THRIFT_BIND_HOST</description>
</property>
</configuration>其中hive.metastore.uris的配置,是Spark SQL可以使用Hive的matestore元数据,既在Spark SQL可以访问Hive的数据库以及表信息。
10,执行jps可以看到SparkSubmit和SparkSubmitDriverBootstrapper进程。
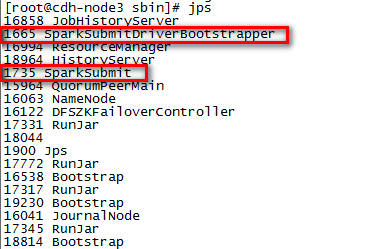
并查看日志文件,可以看到如下信息:

11,到此为止local方式的Spark SQL 的ThrifServer启动成功。
12,停止掉Spark SQL 的ThrifServer。
执行kill -9 SparkSubmit的进程号。这里是:kill -9 1735
13,已yarn的cluster模式启动thriftserver。进入/opt/cloudera/parcels/CDH/lib/spark/sbin目录
执行:./start-thriftserver.sh –master yarn-cluster
14,在/opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/spark/logs中的spark-root-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-cdh-node3.grc.out文件报如下错:
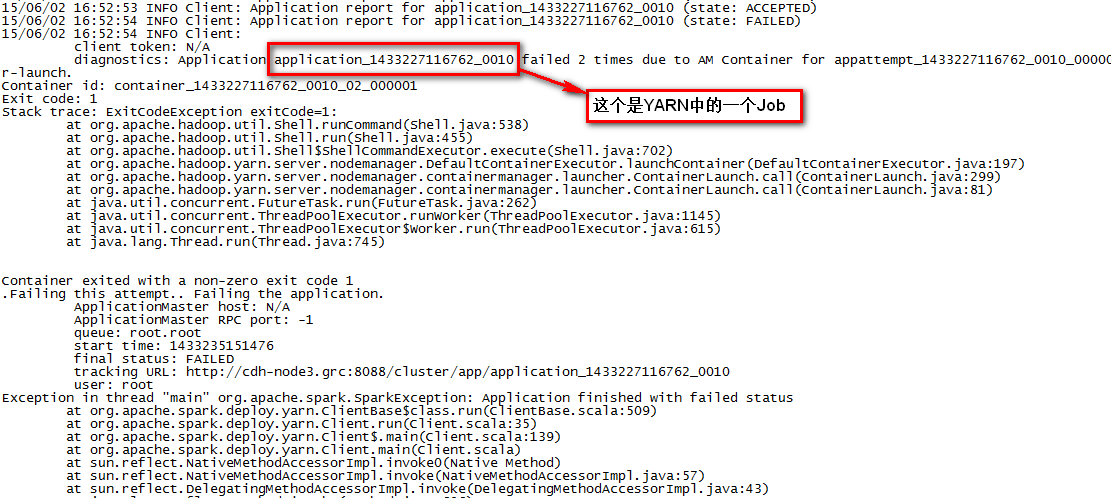
在YARN Resource Manager控制台中有如下错误:
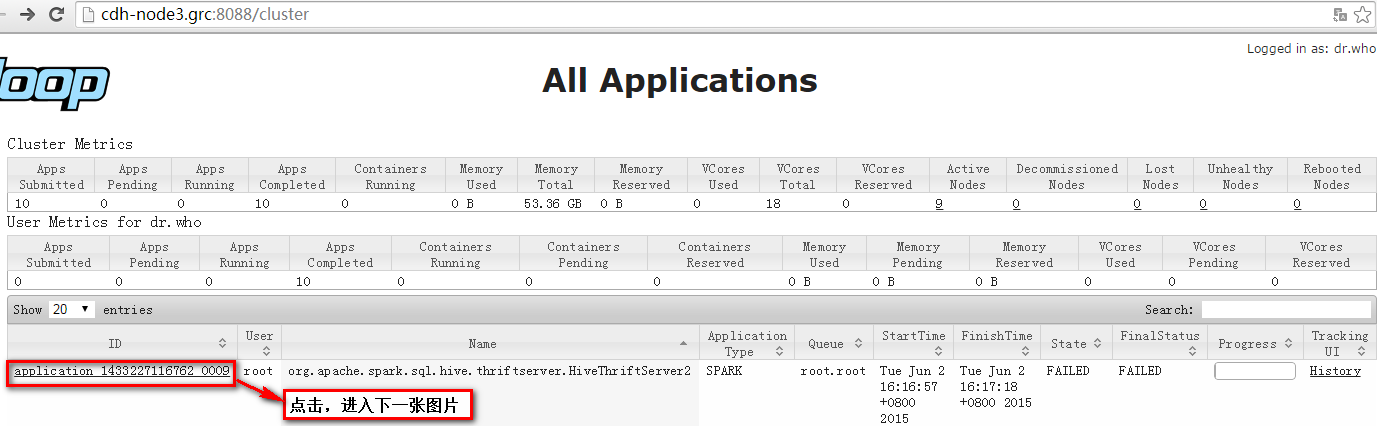
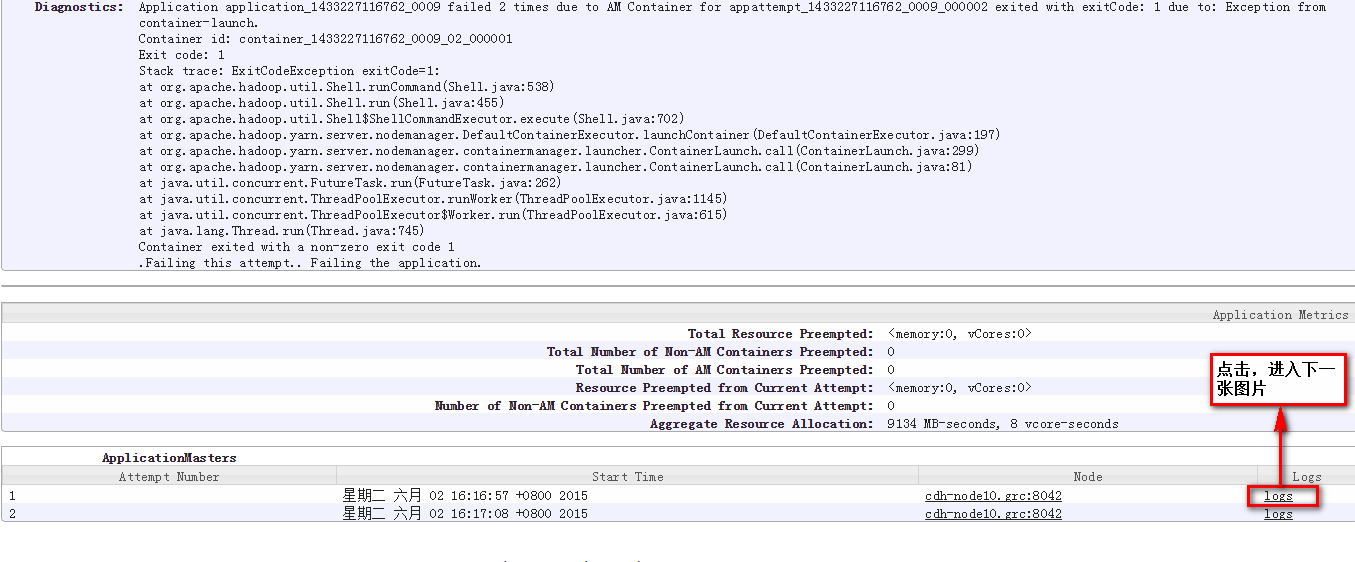
注意,这里是cdh-node10.grc主机(由YARN随机调度ResourceManager节点启动Spark SQL Driver)
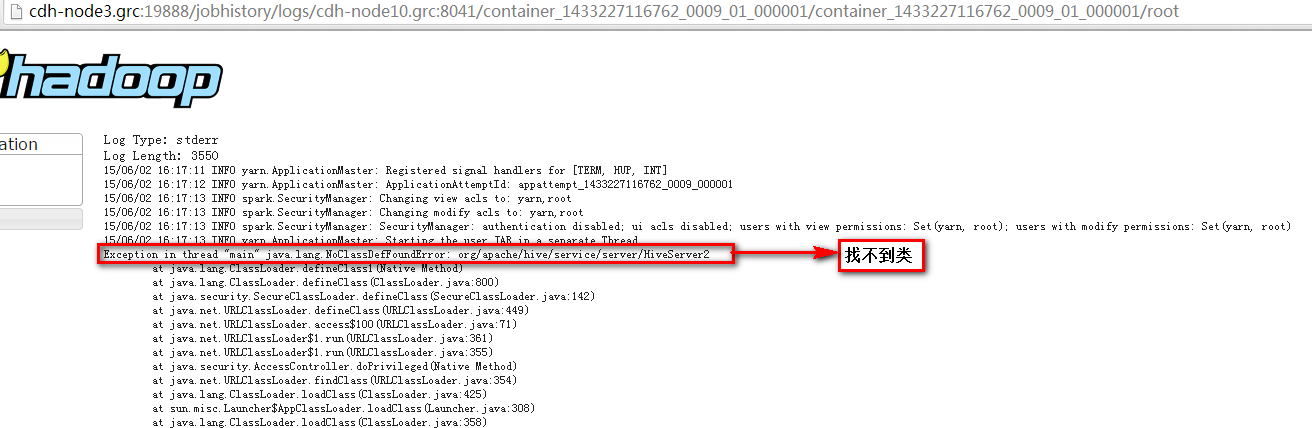
15,解决方法,
在所有的ResourceManager节点的/opt/cloudera/parcels/CDH/lib/spark/bin目录下的compute-classpath.sh文件添加如下配置:
CLASSPATH="$CLASSPATH:/opt/cloudera/parcels/CDH/lib/hive/lib/*"问题还在,不知道为啥?
16,执行
./start-thriftserver.sh –master yarn-client
日志文件如下所示,说明启动成功。
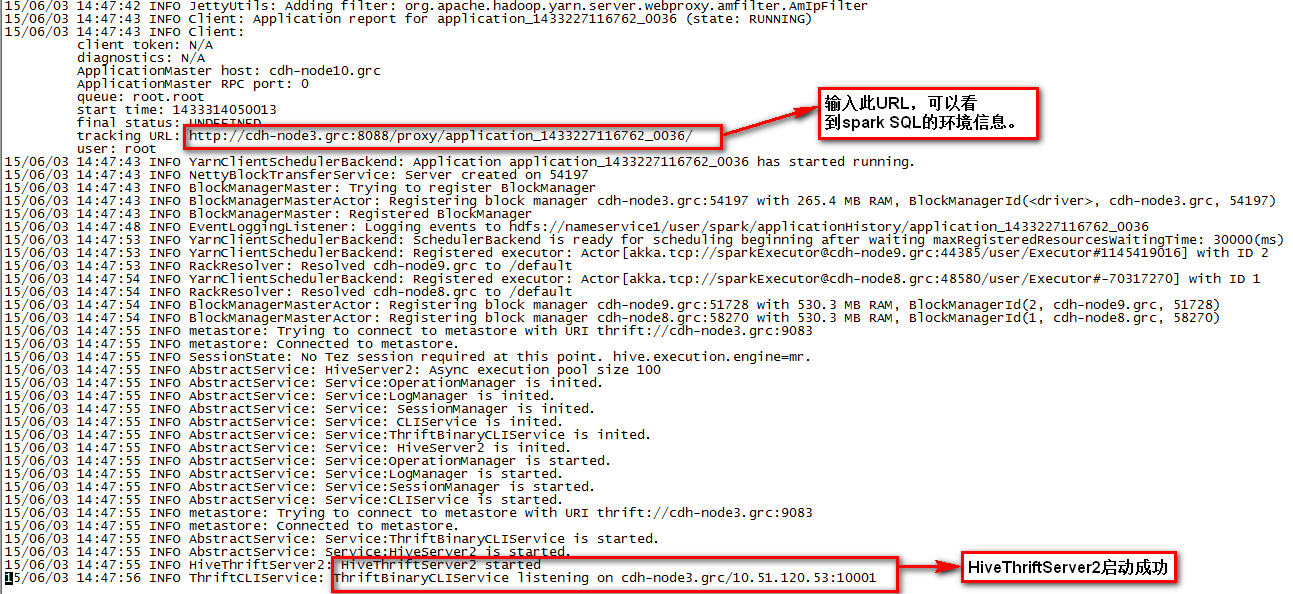

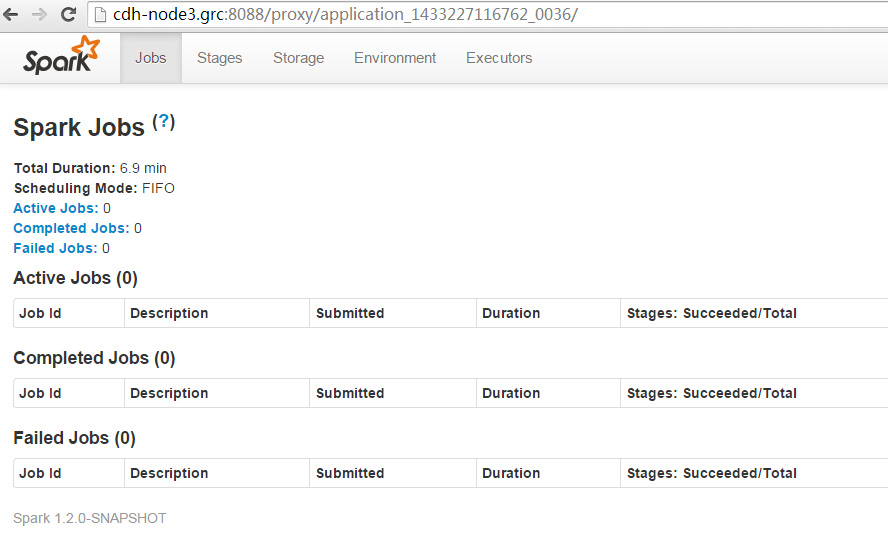
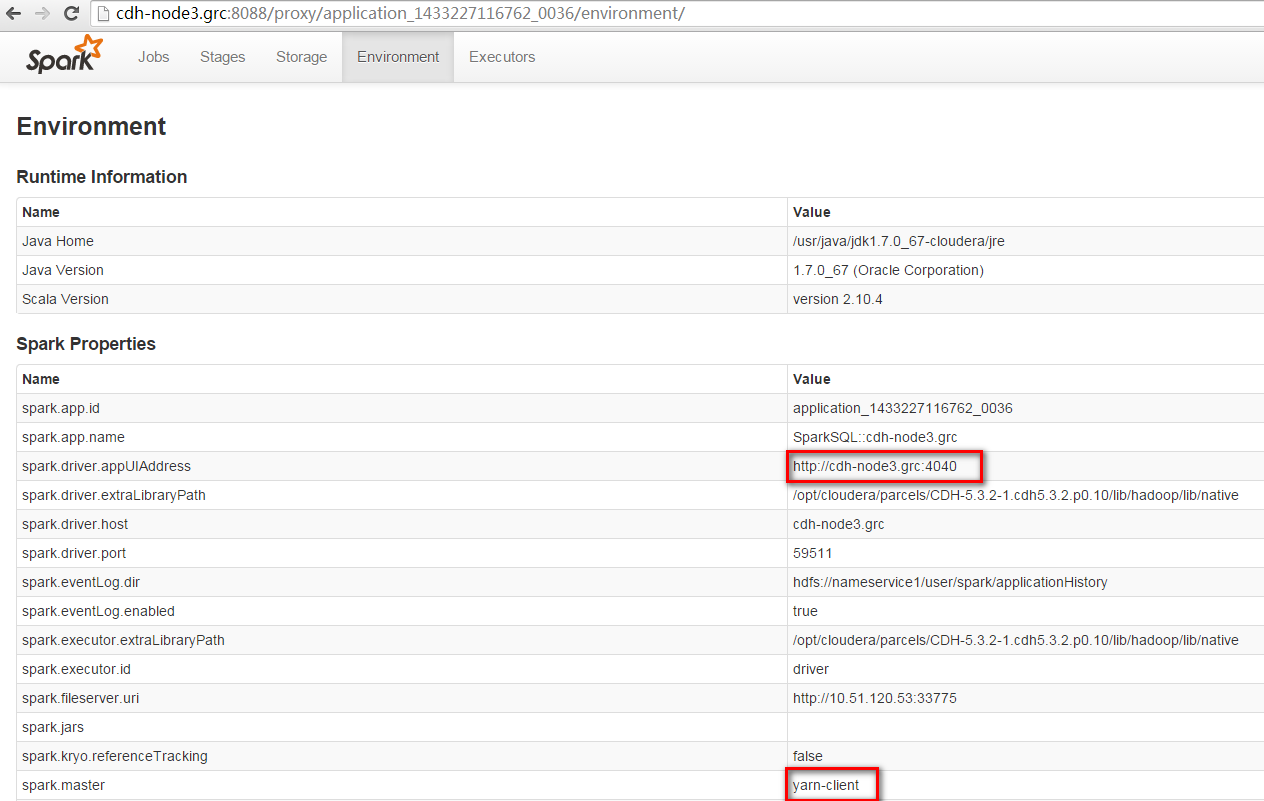
17,通过JDBC方式,在Spark SQL中执行job,则在日志文件有如下错误:
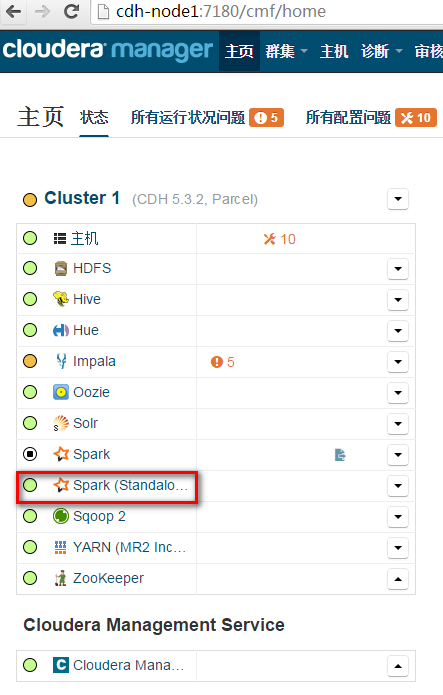
(TID 4, cdh-node8.grc): java.lang.NoClassDefFoundError: Lorg/apache/hadoop/hive/ql/plan/TableDesc;18,在Cloudera Manager中安装Spark Standalone组件。
19,执行如下命令:
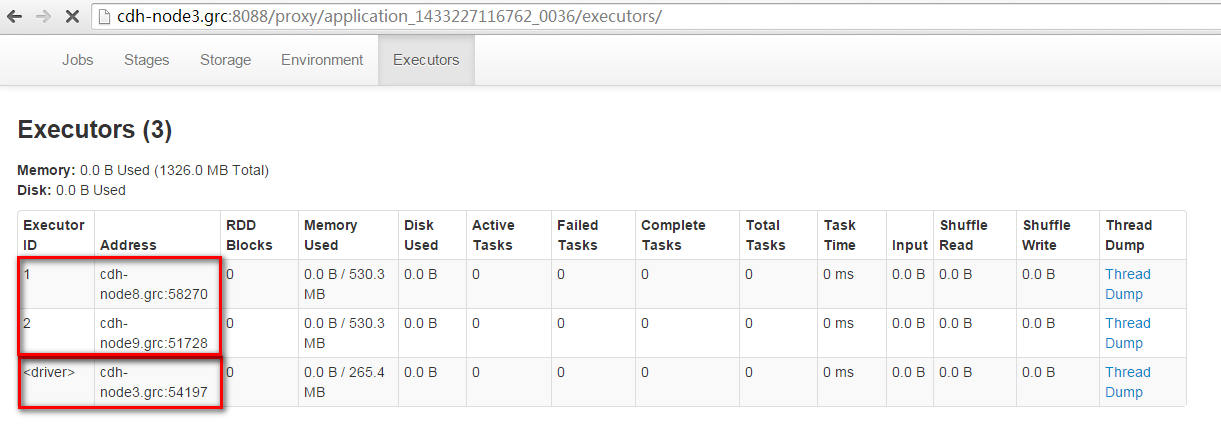
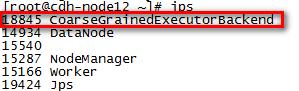
./start-thriftserver.sh --master spark://cdh-node3.grc:7077在所有的Work节点都存在如下“CoarseGrainedExecutorBackend”进程:
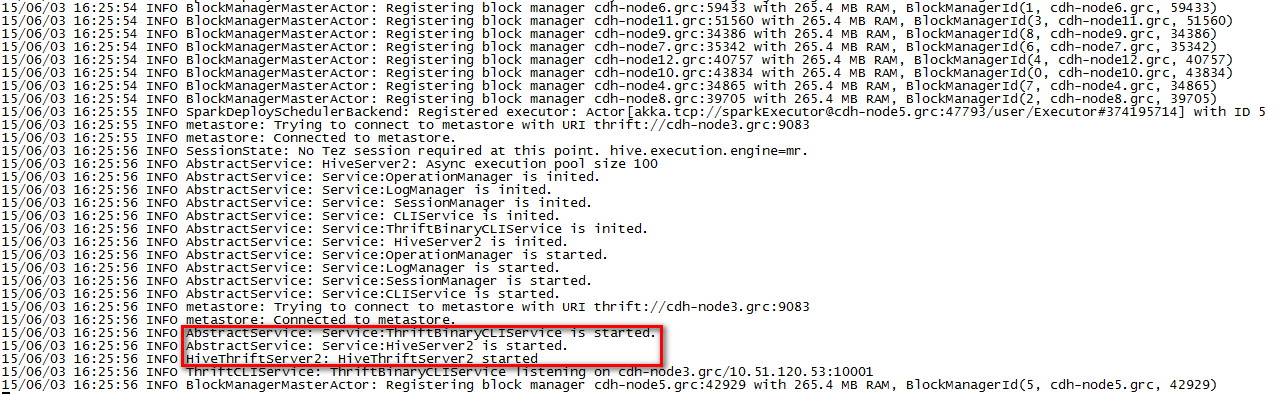
在日志中有“HiveThriftServer2 started”提示:
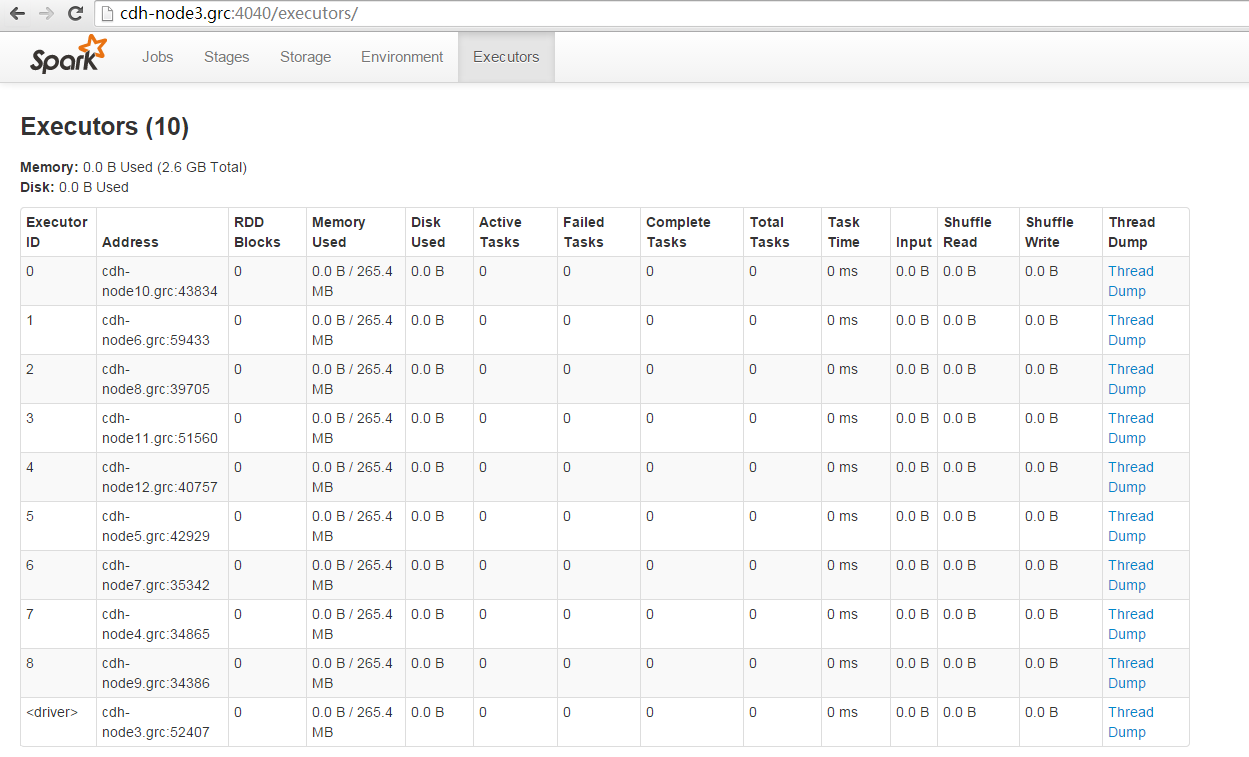
在浏览器中输入“http://cdh-node3.grc:4040/executors/” 可以查到所有的Executors。
20,通过JDBC方式,在Spark SQL中执行job,则在日志文件有如下错误:
(TID 4, cdh-node8.grc): java.lang.NoClassDefFoundError: Lorg/apache/hadoop/hive/ql/plan/TableDesc;
21,在所有的Work节点的/opt/cloudera/parcels/CDH/lib/spark/bin目录下的compute-classpath.sh文件添加如下配置:
CLASSPATH=”$CLASSPATH:/opt/cloudera/parcels/CDH/lib/hive/lib/*”
“`
然后重新启动ThriftServer,在通过JDBC方式,在Spark SQL中执行Job成功。















 1884
1884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









