







 在CDH5.5.0版本中,Spark SQL和SparkR组件未包含,缺少start-thriftserver.sh脚本,导致SQL查询默认使用MR。要启用Spark SQL,你需要寻找替代方法来配置Thrift Server。
在CDH5.5.0版本中,Spark SQL和SparkR组件未包含,缺少start-thriftserver.sh脚本,导致SQL查询默认使用MR。要启用Spark SQL,你需要寻找替代方法来配置Thrift Server。
CDH5.5.0里面阉割了spark-sql和sparkR,目录里面都没有start-thriftserver.sh,哪怕是spark Standalone部署。
但是问题来了,jdbc如何使用spark-sql?
Hive的配置里面有HiveServer2是开着的,如下:
插图:
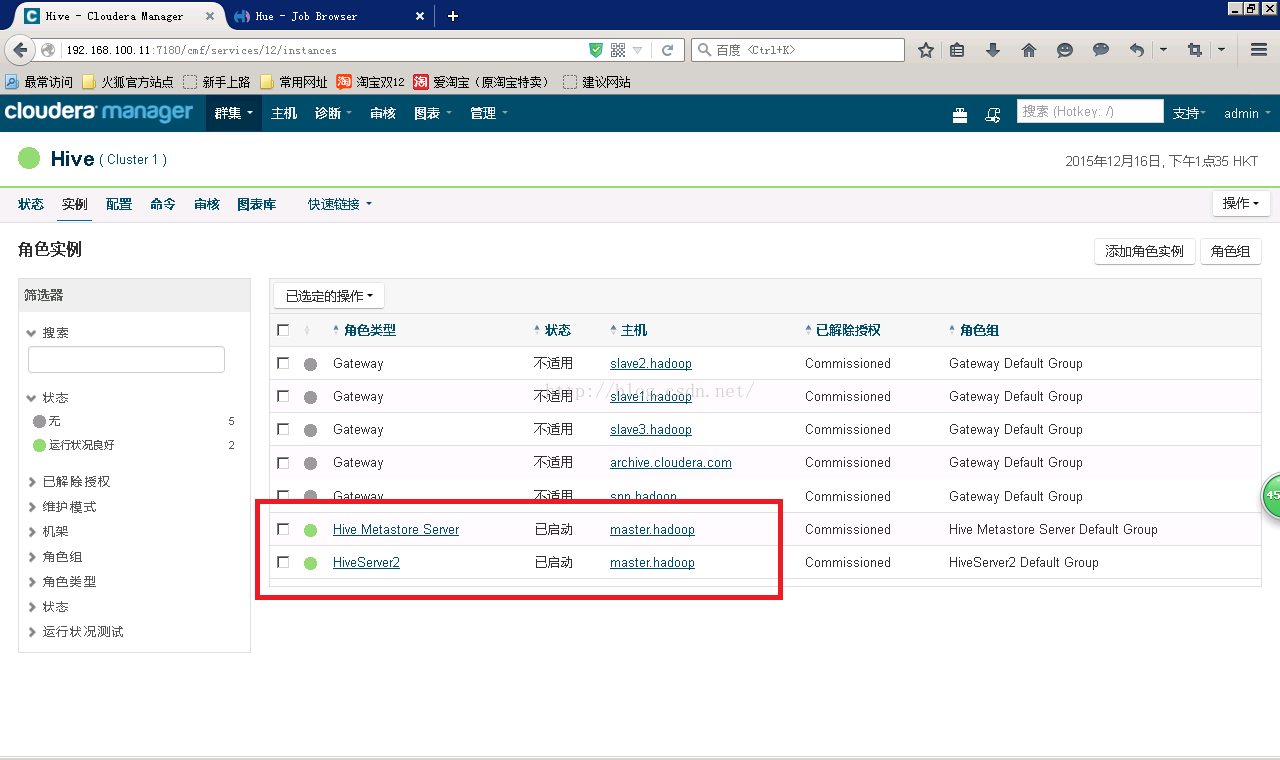
很好,metastore也开着,beeline测试一下
beeline -u jdbc:hive2://192.168.100.11:10000/default -n hive
可以连接上。但是执行的sql,用的是MR,有木有搞错?
插图: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









