







一、概述
CN来自于IEEE802.1Qau,它的目地是为带宽-时延积的量级为5Mbit或更小值的网络域中的长时间存在的流增加拥塞管理功能。这种流常存在于DCB网络,存储网络,计算机集群网络等环境中,因而DCB也常用在这些网络环境中。为了使CN技术可以工作,网络中的网桥以及终端都需要支持CN。以及该技术可用于是DCB的一部分,它用于避免网络拥塞,以减少丢包和降低网络的延迟(拥塞会导致丢包,丢包后重传将增加报文的延迟)。为达到避免网络拥塞的目的,以太网交换机和端点站(在数据中心当中,通常指服务器)均需支持CN:
该技术的基本原理是
- 当网桥发现拥塞时,它就发送拥塞通告给其上游
- 拥塞通告最终会被传递到网络中的能够限制自己发送速率的终端(即数据源)
- 终端在收到拥塞信息后就根据收到的拥塞信息降低自己的发送速率从而消除拥塞进而避免因拥塞而导致的丢包。同时
- 终端还会周期性的尝试增加报文的发送速率,如果拥塞已经消除,增加报文的发送速率并不会引起拥塞,也就不会再收到拥塞通告,报文的发送速率最终得以恢复到拥塞之前的值,以充分利用网络带宽。
二、基本概念
拥塞通告(CN)包括了在虚拟桥接的局域网中(in Virtual Bridged Local Area Networks)为选定的流提供队列拥塞检测并减轻队列拥塞的能力。CN被用在带宽-时延积为5Mbit量级或更小的网络中,以降低受拥塞控制的流(CCF,Congestion Controlled Flow)由于拥塞而丢包的可能性。CN的实现需要支持VLAN的网桥和终端的协作。一个网络中也可能存在非协作者即不支持CN的网桥或者终端,这时候CN通过对网桥和终端资源的划分来保证来自非协作者的数据很少会和CCF竞争资源。
2.1 CP
CP: Congestion Point。指的是支持VLAN的网桥或者终端的端口功能,该功能用于监测一个服务于一个或多个拥塞通告优先级值的队列,并且能够产生拥塞通告消息,移除拥塞通告标签。简单的说可以认为CP就是一个拥塞监测点,是产生拥塞的候选点。对于一个CP
- CP根据自己的发送缓存队列以及QCN算法来计算每个CCF的状态。
- 它不维护关于CCF或者RP的任何信息,它可以从CCF中的任意一个帧中找到CCF以及RP的信息。
- 它独立的根据自己的发送缓存状态来决定是否需要发送CNM。
2.2 RP
RP:Reaction Point。一个终端的端口功能,该功能用于控制CCF的发送速率,同时会接收拥塞通告信息并且将其用于计算CCF的发送速率。对于RP:
每一个RP有一个状态机。
每个终端独立的决定产生多少个CCF,如何标识每个CCF,怎么样为CCF分配RP。
RP状态机的状态变化不会影响相关联的CCF的CN-TAG
一个源自RP的流在网络中经过的路径对RP和CP是透明的,它们不知道该流的数据所选择的路径是什么样的。源自RP的流可能会经过不同的路径,RP对自己发送出去的流所走过的路径不做任何假设。
2.3 QCN协议
QCN:数值化拥塞通告协议(Quantized Congestion Notification protocol)该协议包括两部分:
- CP算法:发生拥塞的网桥或者终端对在发送缓存中正被发送的帧进行取样,并产生一个拥塞通告消息(CNM)给被取样的帧的源。CNM中包含了在该CP上的拥塞程度的信息。
- RP算法:数据源基于收到的CNM的信息对其发送的速率进行限制,同时数据源也会逐渐增大其发送速率来进行可用带宽的探测或者恢复由于拥塞而“损失”的速率。
2.3.1 CP算法
CP算法是基于一个缓存队列实现的。CP算法也利用该队列来探测是否产生拥塞。CP维护的缓存队列如图所示: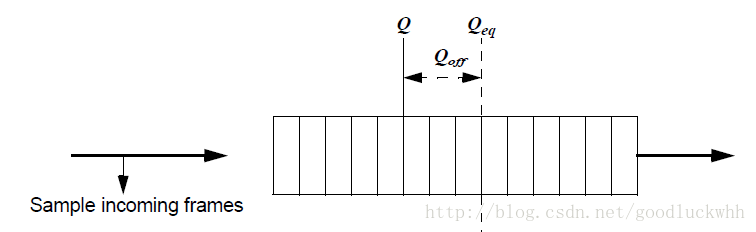
CP会计算一个拥塞指示信息F b ,并且以一个与拥塞程序相关的概率选择一个进入该队列的帧,并向该帧的源地址发送一个包含了F b 的CNM。F b 的计算过程如下:
Qoff = Q – Qeq
Qδ = Q – Qold.
Fb = – (Qoff + w Qδ)
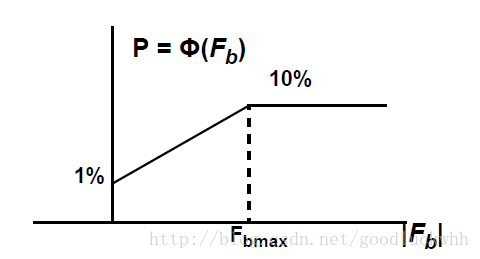
其中Q为即时的队列大小,Q old 是上一次发送CNM时的队列大小。因此Q off 表示的是当前队列大小超过期望值的程度,Q δ 表示当前队列大小超过上次拥塞时队列大小的程度,实际上即为当前速率与上次拥塞时速率的偏差。w是一个非负常量(标准中提到在模拟时取值为2)。F b 在发送之前会被数值化为一个6比特的值。如果该值小于0表示有拥塞,否则没有拥塞,不会发送CNM。
出现拥塞时,发送CNM的概率与F b 的关系如图所示:
2.3.2 基本的RP算法
RP算法需要一种本地的机制来确定何时、怎么样来增大发送速率。RP算法涉及到的几个基本概念:
- Current Rate (CR): 任意时刻经速率限制器(RL)限制后的发送速率。
- Target Rate (TR): 在收到最后一个CNM消息之前的发送速率,它是CR的新的增长目标(即增大CR的目地是增大到该值)。
- Byte Counter: 用于统计发送出去的字节数的计数器。
- Timer:用于触发速率限制器增大发送速率的定时器。
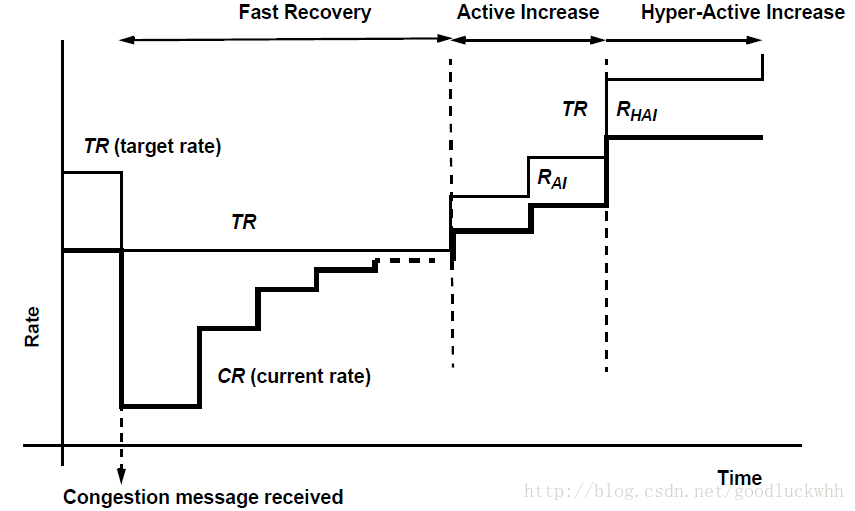
2.3.2.1 降低速率
只有当收到CNM时,RP才会降低发送速率。在收到CNM后,TR被更新为CR。然后CR按照如下公式更新
CR =CR*(1 – G d * |F b|)其中G d 是一个常量,其取值需要保证G d * |F bmax | = ½,因此速率最多降低到原来值的一半。
2.3.2.2 增大速率
增大速率分为两个阶段。快速恢复阶段(FR,Fast Recovery)和主动增加(AI,Active Increase)阶段。1.快速恢复阶段
每当速率被降低时,字节计数器就被重置,同时进入FR阶段。FR阶段包括5个周期,每个周期相当于速率限制器发送150k字节需要的时间。每个周期结束时,TR不变,CR按照如下公式被更新:
CR =½ * (CR + TR)每个周期取150k字节是因为,150k字节相当于发送100个1500字节长的帧,如果CP的采样速率是1%,则如果它还有拥塞时它也能够采样到本源发送的帧 并发送新的拥塞通告上来了。因此如果在这样的一个周期内没有收到新的CNM,就可以认为没有拥塞了,因而就可以来尝试恢复自己因拥塞而“损失”的速率。在这个阶段采取的是快速恢复。(相比之下,TCP采用的是乘性减加性增)。
2. 主动增加阶段
在快速恢复的五个周期执行完后,字节计数器进入主动增加阶段。该阶段用于发现多余的可用带宽(TCP的加性增也有类似功能)。此时RP将探测周期设置为50个帧(也可以设置为100个帧)探测一次,在每个周期完后,RP执行如下操作:
TR=TR+R AIR AI 是一个常量(标准中给出的是5Mbps)。
CR =½ * (CR + TR)
2.3.3带定时器的RP算法
很显然字节计数器与发送速率相关,因而如果CR很小,则字节计数器采样的时间也会很长,最终导致RP的算法变的很慢。因此在RP算法中引入了一个定时器。定时器工作过程类似于字节计数器,也包括FR阶段和AI阶段。当收到CNM消息时,该定时器会被重置,并且进入FR阶段。FR以及AI的基本工作过程与字节计数器中的基本一致,唯一变化的是周期的测量方法,在定时器中FR和AI阶段的每个周期都用定时器来实现。FR阶段,每个周期长度为Tms(标准中给出的模拟时用的时间是10ms),AI阶段,每个周期长度被设置为T/2ms。
字节计数器和定时器共同决定了速率限制器的速率增长。两种机制独立的工作,最终:
- 如果两者都在FR阶段,则速率限制器处于FR阶段。此时周期先到的负责按照快速恢复阶段的算法进行速率更新。
- 只要有任意一个处于AI阶段,则速率限制器就处于AI阶段。此时周期先到者负责按照AI阶段的算法更新速率。
- 如果两者都在AI阶段,则速率限制其处于HAI (for Hyper-Active Increase)阶段。此时如果字节计数器或者定时器的第i个周期结束了,则TR和CR按照如下算式更新:
TR =TR + i * R HAICR =½ * (CR + TR)
R HAI是一个常量(在标准的模拟中被设置为50Mbps。需要注意的是在收到一个CNM后至少需要经过50毫秒或者发送了500个帧之后,速率限制器才能进入HAL状态。
2.4 CCF
CCF(Congestion Controlled Flow):具有相同的优先级的一系列帧,这些帧的发送终端将其看做是单一的流,并且使用同一个响应点来控制这些帧的发送速率。简单的说CCF由来自同一个终端的同一个发送队列的数据组成,比如来自同一个终端的同一个进程的数据,来自同一个终端的同一个UDP socket的数据。同一个CCF中的数据都具有相同的CNPV。需要注意的是终端发出的数据并不一定必须是属于某个CCF的。非CCF的流不会受CN的控制。对CCF的要求:
- 在CP上只有很小的几率会出现由于缓存满而丢包。
- 当前CP上的CCF的平均缓存使用量是带宽-时延积的很小的部分,并且该平均使用量和CCF的数目无关,这是为了保证在进行拥塞避免时还有缓存可以缓存线路上的报文,从而保证避免丢包不会引入大的时延或者时延抖动。否则,如果没有足够的空间来缓存线路上的报文,则为了丢包就要进行重传,从而会导致大的时延或时延抖动。
- 当前CP上的缓存使用量只有很小的几率会underflow。
- 如果多个CCF共享当前CP,则这些CCF会获得几乎相同的带宽。如果每个CCF有自己的当前CP,则它们获得的带宽和该CCF获取的资源成比例。
- 只有很小几率会出现underflow和overflow的限制不依赖于CCF的数目,也不依赖于流上的负载。
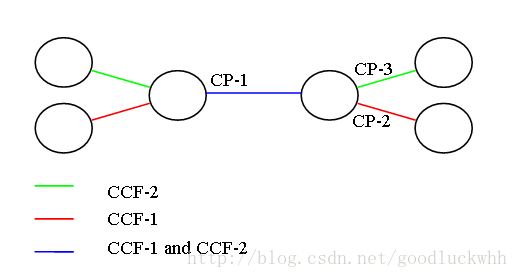
- 每一个CP所被提供的带宽都会被尽量充分利用。只要发送队列不空,就会往外发送。如果有两个CCF:CCF-1,CCF-2经过了同一个CP:CP-1,同时CCF-1还要经过CP-2,CCF-2还要经过CP-3,现在CP-2出现了拥塞,因而CCF-1的流量会受到限制,但是CCF-2不会受到影响。一个简单的图示如下:
2.5 CNPV
CNPV(Congestion Notification Priority Value):拥塞通告优先级值。该值取自优先级参数,并被支持CN的网桥或者终端用于支持拥塞通告。同一个拥塞域中的网桥和终端的端口被配置成使得包含该值的帧被分配给相同的CP/SP。因为有8个优先级值,因而一个端口最多可以支持8个CNPV的值。需要注意的是至少要保证一个值被用于尽力交付的流。2.6 CN-TAG
CN-TAG(Congestion Notification Tag):拥塞通告标签。可以传输流标识的一个标签。RP可以把它加到CCF帧中,CP可以在一个CNM中包含它。Flow ID(Flow Identifier): 流标识。由支持CN的终端分配的一个标识,在由该终端发送的CCF中是唯一的。终端可以从CNM中获取它并最终找到出现拥塞的流以及RP。
添加CN-TAG的原因:
- 通过CN-TAG中的流标识,终端可以找到是一个CCF中的多个流中的哪一触发了该CNM。
- 解析流标签比解析报文内容更容易,因而更容易找到对应的流
CN-TAG包括两种封装格式,分别是以太网封装和和SNAP封装。封装格式分别如下:

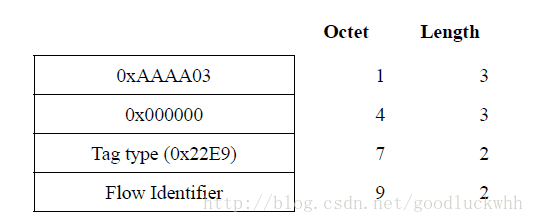
包含了CN-TAG之后的报文个部分顺序为(如果没有就忽略):
| addresses | VLAN-TAG | CN-TAG | data |
2.7 CND
CND(Congestion Notification Domain):拥塞通告域。拥塞域由支持VLAN的网桥和终端组成,这些网桥和终端被连接在一起,并且被配置成支持一个CNPV。支持不同的CNPV的CND可以在网络中共存。不同的CND可以由不同的网桥、终端组成。简单的说CND就是被配置成支持某个CNPV的子网,是拥塞通告所生效的一个虚拟的网络域。CND保证了期望活得拥塞服务的CCF能够真正获得期望的拥塞服务。CND用于:
- 保证只有源自RP的流才会经过CP。
- 保证源自RP的流不会经过一个不包含CP的拥塞端口。
拥塞通告TLV通过LLDP来发送。拥塞通告TLV格式如下图所示:

- Per-priority CNPV:这是一个一字节的比特向量,每个比特对应一个优先级,least-significant 比特对应优先级0,依次类推。如果某个比特为1则表示该优先级被用作CNPV,否则不用做CNPV。
- Per-priority Ready:这也是一个一字节的比特向量,每个比特对应一个优先级。 least-significant比特对应优先级0,依次类推。每个比特对应于相应的CNPV的cnpdXmitReady。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









