







面向对象编程:https://www.liaoxuefeng.com/wiki/1016959663602400/1017495723838528
面向对象高级编程:https://www.liaoxuefeng.com/wiki/1016959663602400/1017501628721248
1、类、对象 相关概念
什么是 "类" ?、什么是 "对象(实例)" ?
类 和 对象 是面向对象编程的两个主要方面。
- 类 是创建一个 新类型,用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 对象 是类 的 实例 。在面向对象编程时,可以认为 "对象就是实例,实例就是对象"
方法 和 函数 在 python中是不同的概念,
- 方法是类中定义的函数,即在类中的函数才叫方法。
- 函数是就是一般的函数
一般在类里面定义的函数与 "类、对象(实例)" 绑定,所以称作为方法;
而在类外定义的函数一般没有同对象进行绑定,就称为函数。
实例变量 ( 又叫 "实例属性")、类变量( 又叫 "类属性")
- 实例变量:定义在实例(对象)中的变量,只作用于当前实例(对象)。
- 类变量 :定义在类中且在函数体之外。类变量通常不作为实例变量使用。类变量在整个实例化的对象中是公用的。
- 方法重载:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),重载。
- 继承 :即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。
类属性就是类对象所拥有的属性,它被所有类对象的实例对象所共有,在内存中只存在一个副本,这个和C++中类的静态成员变量有点类似。
class People:
name = 'jack' # 公有的类属性
__age = 12 # 私有的类属性
obj = People()
print(obj.name) # 正确
print(People.name) # 正确
print(obj.__age) # 错误,不能在类外通过实例访问私有的类属性
print(People.__age) # 错误,不能在类外通过类访问私有的类属性实例属性是不需要在类中显示定义的,可以动态添加。比如:
class People:
name = 'jack'
obj = People()
obj.age = 12
print(obj.name) # 正确
print(obj.age) # 正确
print(People.name) # 正确
print(People.age) # 错误类People 实例化之后,产生了一个 对象 obj,然后 obj.age = 12这句给obj添加了一个实例属性age,赋值为12。这个实例属性是实例对象obj所特有的,注意,类对象 People 并不拥有它(所以不能通过类对象来访问这个age属性)。当然还可以在实例化对象的时候给age赋值。
class People:
name = 'jack'
# __init__()是内置的构造方法,在实例化对象时自动调用
def __init__(self, age):
self.age = age
Obj = People(12)
print(obj.name) # 正确
print(obj.age) # 正确
print(People.name) # 正确
print(People.age) # 错误如果需要在类外修改类属性,必须通过类对象去引用然后进行修改。如果通过实例对象去引用,会产生一个同名的实例属性,这种方式修改的是实例属性,不会影响到类属性,并且之后如果通过实例对象去引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除了该实例属性。
class People:
country = 'china'
print(People.country)
p = People()
print(p.country)
p.country = 'japan'
print(p.country) # 实例属性会屏蔽掉同名的类属性
print(People.country)
del p.country # 删除实例属性
print(p.country)实例方法、类方法、静态方法
在 Python类中定义的方法通常有三种:实例方法、类方法、静态方法。这三者之间的区别是:
- 实例方法:以 self 作为第一个参数,必须和具体的对象实例进行绑定才能访问。
- 类方法:如果方法需要类的信息,用 @classmethod 对其进行装饰 就变成了 类方法,类方法的第一个参数总是 cls。类方法经常被用作 factory。cls表示类本身,通过 cls 引用的必定是类对象的属性和方法;
- 静态方法:就是一般的普通函数放到了类里面。定义的时候使用@staticmethod 修饰。静态方法中不需要额外定义参数,因此在静态方法中引用类属性的话,必须通过类的对象来引用。静态方法并不是真正意义上的类方法,因为它没有关于 class 或 object 的任何信息,所以它实际上是一个独立的函数,只是被放到了类里。( 静态方法可以访问类属性 )
静态方法通常用于组织代码,例如如果认为将某个函数放到某个类里,整体代码会因此更符合逻辑,于是可以将这个函数变成该类的静态方法。所以如果需要在类里放一个函数进去,此函数不会用到任何关于类或实例的信息,那么就可以用 @staticmethod 对其进行装饰。
三种方法中,实例方法和类方法用得最多,静态方法不常用。
class Book(object):
TYPES = ("hardcover", "paperback") # 精装,平装
def __init__(self, name, book_type, weight):
self.name = name
self.book_type = book_type
self.weight = weight
def __repr__(self):
return f"<Book {self.name}, {self.book_type}, weighing {self.weight}g>"
def instance_method(self):
print(f"Called instance method of {self}")
@classmethod
def class_method(cls):
print(f"called class method of {cls}")
@classmethod
def hardcover(cls, name, paper_weight): # cls 名称任意,使用 cls 是 convention
# 下一行的cls,改成 Book,代码也能跑,但应该写成 cls, 以避免在 inheritance 可能会遇到的问题
return cls(name, cls.TYPES[0], paper_weight + 100) #
@classmethod
def paperback(cls, name, paper_weight):
# 下一行的cls,改成 Book,代码也能跑,但应该写成 cls, 以避免在 inheritance 可能会遇到的问题
return cls(name, cls.TYPES[1], paper_weight)
@staticmethod
def static_method():
print("Called static method")
book = Book("Dive into Python", Book.TYPES[1], 800)
book.instance_method()
# 下一行代码和上一行完全等价
Book.instance_method(book)
Book.class_method()
Book.static_method()
h_book = Book.hardcover("Harry Potter", 1500)
light = Book.paperback("Python 101", 600)
print(h_book)
print(light)
Python 不允许实例化的类访问私有数据,但你可以使用 object._className__attrName 访问这些私有属性。
构造方法 __init__() 和 析构方法 __del__()
- __init__(self) 方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法。构造方法支持重载,如果没有构造方法,系统就自动执行默认的构造方法。
-
__del__(self) 方法也是一种特殊的方法,叫做 析构方法。在释放对象时调用,支持重载,可以在里面进行一些释放资源的操作,不需要显示调用。
__init__ 方法
在 Python 的类中,有很多方法的名字有特殊的重要意义。现在看下 __init__方法的意义。__init__ 方法在类的一个对象被建立时,马上运行。这个方法可以用来对你的对象做一些你希望的 初始化 。注意,这个名称的开始和结尾都是双下划线 __init__
#!/usr/bin/python
# Filename: class_init.py
class Person:
def __init__(self, name):
self.name = name
def say_hi(self):
print('Hello, my name is', self.name)
p = Person('one')
p.say_hi()
Person('two').say_hi()这个__init__方法有两个参数,分别是 self、name,方法里面是 self.name = name。注意它们是两个不同的变量,尽管它们有相同的名字。点号使我们能够区分它们。最重要的是,我们没有专门调用__init__方法,只是在创建一个类的新实例的时候,把参数包括在圆括号内跟在类名后面,从而传递给__init__方法。
给C/C++/Java/C#程序员的注释:__init__方法类似于C++、C#和Java中的 constructor 。
Python 类中 内置属性和方法
Python 类中的属性
- __dict__ : 类的属性(包含一个字典,由类的数据属性组成)
- __doc__ : 类的文档字符串
- __name__ : 类名
- __module__: 类定义所在的模块(类的全名是'__main__.className',如果类位于一个导入模块mymod中,那么className.__module__ 等于 mymod)
- __bases__ : 类的所有父类构成元素(包含了以个由所有父类组成的元组)
Python 类中的方法
在 Python 中有一些内置的方法,这些方法命名都有比较特殊的地方(其方法名以2个下划线开始然后以2个下划线结束)。类中最常用的就是构造方法和析构方法。
- 构造方法 __init__(self,....):在生成对象时调用,可以用来进行一些初始化操作,不需要显示去调用,系统会默认去执行。构造方法支持重载,如果没有构造方法,系统就自动执行默认的构造方法。
- 析构方法 __del__(self):在释放对象时调用,支持重载,可以在里面进行一些释放资源的操作,不需要显示调用。
还有其他的一些内置方法,比如 __cmp__( ), __len( )__等。下面是常用的内置方法:
| 内置方法 | 说明 |
| __init__(self,...) | 初始化对象,在创建新对象时调用 |
| __del__(self) | 释放对象,在对象被删除之前调用 |
| __new__(cls,*args,**kwd) | 实例的生成操作 |
| __str__(self) | 在使用print语句时被调用 |
| __getitem__(self,key) | 获取序列的索引key对应的值,等价于seq[key] |
| __len__(self) | 在调用内联函数len()时被调用 |
| __cmp__(stc,dst) | 比较两个对象src和dst |
| __getattr__(s,name) | 获取属性的值 |
| __setattr__(s,name,value) | 设置属性的值 |
| __delattr__(s,name) | 删除name属性 |
| __getattribute__() | __getattribute__()功能与__getattr__()类似 |
| __gt__(self,other) | 判断self对象是否大于other对象 |
| __lt__(slef,other) | 判断self对象是否小于other对象 |
| __ge__(slef,other) | 判断self对象是否大于或者等于other对象 |
| __le__(slef,other) | 判断self对象是否小于或者等于other对象 |
| __eq__(slef,other) | 判断self对象是否等于other对象 |
| __call__(self,*args) | 把实例对象作为函数调用 |
__new__(): __new__() 在 __init__() 之前被调用,用于生成实例对象。利用这个方法和类属性的特性可以实现设计模式中的单例模式。单例模式是指创建唯一对象吗,单例模式设计的类只能实例化一个对象。
# -*- coding: UTF-8 -*-
class Singleton(object):
__instance = None # 定义实例
def __init__(self):
pass
def __new__(cls, *args, **kwd): # 在__init__之前调用
if Singleton.__instance is None: # 生成唯一实例
Singleton.__instance = object.__new__(cls, *args, **kwd)
return Singleton.__instance__getattr__()、__setattr__() 和__getattribute__() :当读取对象的某个属性时,python会自动调用__getattr__()方法。例如,fruit.color将转换为fruit.__getattr__(color)。当使用赋值语句对属性进行设置时,python会自动调用__setattr__()方法。__getattribute__()的功能与__getattr__()类似,用于获取属性的值。但是__getattribute__()能提供更好的控制,代码更健壮。注意,python中并不存在__setattribute__()方法。代码例子:
# -*- coding: UTF-8 -*-
class Fruit(object):
def __init__(self, color="red", price=0):
self.__color = color
self.__price = price
def __getattribute__(self, item): # 获取属性的方法
return object.__getattribute__(self, item)
def __setattr__(self, key, value):
self.__dict__[key] = value
if __name__ == "__main__":
fruit = Fruit("blue", 10)
print(fruit.__dict__.get("_Fruit__color")) # 获取color属性
fruit.__dict__["_Fruit__price"] = 5
print(fruit.__dict__.get("_Fruit__price")) # 获取price属性__getitem__(): 如果类把某个属性定义为序列,可以使用__getitem__()输出序列属性中的某个元素.假设水果店中销售多钟水果,可以通过__getitem__()方法获取水果店中的没种水果。代码例子:
# -*- coding: UTF-8 -*-
class FruitShop:
def __getitem__(self, i): # 获取水果店的水果
return self.fruits[i]
if __name__ == "__main__":
shop = FruitShop()
shop.fruits = ["apple", "banana"]
print(shop[1])
for item in shop: # 输出水果店的水果
print(item)
# 结果
# banana
# apple
# banana__str__(): __str__()用于表示对象代表的含义,返回一个字符串.实现了__str__()方法后,可以直接使用print语句输出对象,也可以通过函数str()触发__str__()的执行。这样就把对象和字符串关联起来,便于某些程序的实现,可以用这个字符串来表示某个类。代码例子:
# -*- coding: UTF-8 -*-
class Fruit:
"""''Fruit类""" # 为Fruit类定义了文档字符串
def __str__(self): # 定义对象的字符串表示
return self.__doc__
if __name__ == "__main__":
fruit = Fruit()
print(str(fruit)) # 调用内置函数str()触发__str__()方法,输出结果为:Fruit类
print(fruit) # 直接输出对象fruit,返回__str__()方法的值,输出结果为:Fruit类__call__(): 在类中实现__call__()方法,可以在对象创建时直接返回__call__()的内容。使用该方法可以模拟静态方法。代码例子:
# -*- coding: UTF-8 -*-
class Fruit:
class Growth: # 内部类
def __call__(self):
print("grow ...")
grow = Growth() # 调用Growth(),此时将类Growth作为函数返回,即为外部类Fruit定义方法grow(),grow()将执行__call__()内的代码
if __name__ == '__main__':
fruit = Fruit()
fruit.grow() # 输出结果:grow ...
Fruit.grow() # 输出结果:grow ...self 参数
Python 中的 self 等价于 C++ 中的 this 指针。
Python 如何给 self 赋值以及为何你不需要给它赋值?举一个例子会使此变得清晰:假如你有一个类称为 MyClass 和这个类的一个实例MyObject。当你调用这个对象的方法 MyObject.method(arg1, arg2) 的时候,这会由 Python 自动转为 MyClass.method(MyObject, arg1, arg2),这就是self的原理了。这也意味着如果你有一个不需要参数的方法,你还是得给这个方法定义一个self 参数。
Python对象 的 销毁(垃圾回收)
在 Python 内部记录着所有使用中的对象各有多少引用。一个内部跟踪变量,称为一个引用计数器。当对象被创建时, 就创建了一个引用计数, 当这个对象不再需要时, 这个对象的引用计数变为0 时,它被垃圾回收。但是回收不是"立即"的, 由解释器在适当的时机,将垃圾对象占用的内存空间回收。
2、类 与 对象的方法
创建 类、创建 类对象(类实例)
首先使用 class 定义一个类,然后使用 类 去创建 对象(实例)
创建一个 类
class Person:
pass # An empty block使用 class 后跟类名,创建一个新的类。这后面跟着一个缩进的语句块形成类体。这个例子中,使用 pass 语句表示空语句。然后使用类名后跟一对圆括号来创建一个对象/实例。
创建 类对象(类实例)
p = Person()
print(p)# <__main__.Person object at 0x0000022A7241BB20>
为了验证,简单地打印了这个变量的类型。它告诉我们我们已经在__main__模块中有了一个Person类的实例。可以注意到存储对象的计算机内存地址也打印了出来。这个地址在你的计算机上会是另外一个值,因为Python可以在任何空位存储对象。
调用 对象的属性
class Employee(object):
def __init__(self, name, age):
self.name = name
self.age = age
pass
def __del__(self):
pass
def display_employee(self):
print(f'name:{self.name}, age:{self.age}')
emp1 = Employee("one", 2000) # "创建 Employee 类的第一个对象"
emp2 = Employee("two", 5000) # "创建 Employee 类的第二个对象"
# 使用点(.)来访问对象的属性。使用如下类的名称访问类变量:
emp1.display_employee()
# 你可以添加,删除,修改类的属性,如下所示:
emp1.age = 7 # 添加一个 'age' 属性
emp1.age = 8 # 修改 'age' 属性
del emp1.age # 删除 'age' 属性操作 属性 的另一种方式:getattr、hasattr、setattr
class TestClass(object):
name = 'TestClass'
pass
obj = TestClass()
t_name = getattr(obj, 'name') # 访问对象的属性。
print(t_name)
is_have = hasattr(obj, 'name') # 检查是否存在一个属性。
print(is_have)
setattr(obj, 'age', 100) # 设置一个属性。如果属性不存在,会创建一个新属性。
# delattr(obj, 'name') # 删除属性。使用 对象的方法
class Person(object):
def say_hi(self):
print('Hello, how are you?')
p = Person()
p.say_hi()
这里可以看到 self 的用法。注意 say_hi 方法没有任何参数,但仍然在函数定义时有 self。
类变量、对象(实例)变量
在Python中,有类属性和实例属性。类属性是属于类本身的,被所有的类实例共享。
类属性可以通过类名访问和修改,也可以通过类实例进行访问和修改。但是,当实例定义了跟类同名的属性后,类属性就被隐藏了。
类的变量 由一个类的所有对象(实例)共享使用。只有一个类变量的拷贝,所以当某个对象对类的变量做了改动的时候,这个改动会反映到所有其他的实例上。
对象的变量 由类的每个对象/实例拥有。因此每个对象有自己对这个域的一份拷贝,即它们不是共享的,在同一个类的不同实例中,虽然对象的变量有相同的名称,但是是互不相关的。通过一个例子会使这个易于理解。
使用 类与对象 的 变量
class Person:
"""Represents a person."""
population = 0
def __init__(self, name):
"""Initializes the person's data."""
self.name = name
print('(Initializing %s)' % self.name)
# When this person is created, he/she
# adds to the population
Person.population += 1
def __del__(self):
"""I am dying."""
print('%s says bye.' % self.name)
Person.population -= 1
if Person.population == 0:
print('I am the last one.')
else:
print('There are still %d people left.'% Person.population)
def sayHi(self):
"""Greeting by the person.
Really, that's all it does."""
print('Hi, my name is %s.' % self.name)
def howMany(self):
"""Prints the current population."""
if Person.population == 1:
print('I am the only person here.')
else:
print('We have %d persons here.'% Person.population)
swaroop = Person('Swaroop')
swaroop.sayHi()
swaroop.howMany()
kalam = Person('Abdul Kalam')
kalam.sayHi()
kalam.howMany()
swaroop.sayHi()
swaroop.howMany()结果:
(Initializing Swaroop)
Hi, my name is Swaroop.
I am the only person here.
(Initializing Abdul Kalam)
Hi, my name is Abdul Kalam.
We have 2 persons here.
Hi, my name is Swaroop.
We have 2 persons here.
Swaroop says bye.
There are still 1 people left.
Abdul Kalam says bye.
I am the last one.这里,
- population 属于 Person类,因此是一个类的变量。
- name变量 属于 对象(它使用self赋值),因此是对象的变量。
在 __init__ 方法中,我们让 population 增加1,这是因为我们增加了一个人。同样可以发现,self.name 的值根据每个对象指定,这表明了它作为对象的变量的本质。
记住,你只能使用 self变量 来 引用 同一个对象的变量和方法。
在这个程序中,还可以看到 docstring 对于类和方法同样有用。我们可以在运行时使用 Person.__doc__ 和 Person.sayHi.__doc__来分别访问类与方法的文档字符串,就如同 __init__ 方法一样,还有一个特殊的方法 __del__,它在对象消逝的时候被调用。对象消逝即对象不再被使用,它所占用的内存将返回给系统作它用。在这个方法里面,我们只是简单地把 Person.population 减 1。
当对象不再被使用时,__del__方法运行,但很难保证这个方法究竟在 什么时候 运行。如果你想要指明它的运行,你就得使用 del 语句。
给C/C++/Java/C#程序员的注释
- Python 中所有的 类成员(包括数据成员)都是 公共的 ,所有的方法都是 有效的 。
- 只有一个例外:如果你使用的数据成员名称以 "双下划线前缀", 比如 __privatevar,Python 的名称管理体系会有效地把它作为私有变量。
- 这样就有一个惯例,如果某个变量 只想在类或对象中使用,就应该以 "单下划线前缀"。而其他的名称都将作为公共的,可以被其他类/对象使用。记住这只是一个惯例,并不是Python所要求的(与双下划线前缀不同)。
- 同样,注意 __del__ 方法与 destructor 的概念类似。
类方法、实例方法、静态方法
下面来看一下类方法、实例方法 和 静态方法 的区别。
类方法:是类对象所拥有的方法,需要用修饰器"@classmethod"来标识其为类方法,对于类方法,第一个参数必须是类对象,一般以"cls"作为第一个参数(当然可以用其他名称的变量作为其第一个参数,但是大部分人都习惯以'cls'作为第一个参数的名字,就最好用'cls'了),能够通过实例对象和类对象去访问。
class People:
country = 'china'
# 类方法,用classmethod来进行修饰
@classmethod
def getCountry(cls):
return cls.country
p = People()
print(p.getCountry()) # 可以用过实例对象引用
print(People.getCountry()) # 可以通过类对象引用类方法还有一个用途就是可以对类属性进行修改:
class People:
country = 'china'
# 类方法,用classmethod来进行修饰
@classmethod
def getCountry(cls):
return cls.country
@classmethod
def setCountry(cls, country):
cls.country = country
p = People()
print(p.getCountry()) # 可以用过实例对象引用
print(People.getCountry()) # 可以通过类对象引用
p.setCountry('japan')
print(p.getCountry())
print(People.getCountry())运行结果:
china
china
japan
japan 结果显示在用类方法对类属性修改之后,通过类对象和实例对象访问都发生了改变。
实例方法:在类中最常定义的成员方法,它至少有一个参数并且必须以实例对象作为其第一个参数,一般以名为'self'的变量作为第一个参数(当然可以以其他名称的变量作为第一个参数)。在类外实例方法只能通过实例对象去调用,不能通过其他方式去调用。
class People:
country = 'china'
# 实例方法
def getCountry(self):
return self.country
p = People()
print(p.getCountry()) # 正确,可以用过实例对象引用
print(People.getCountry()) # 错误,不能通过类对象引用实例方法静态方法: 需要通过修饰器"@staticmethod"来进行修饰,静态方法不需要多定义参数。
class People:
country = 'china'
@staticmethod
# 静态方法
def getCountry():
return People.country
print(People.getCountry())对于类属性和实例属性,如果在类方法中引用某个属性,该属性必定是类属性,而如果在实例方法中引用某个属性(不作更改),并且存在同名的类属性,此时若实例对象有该名称的实例属性,则实例属性会屏蔽类属性,即引用的是实例属性,若实例对象没有该名称的实例属性,则引用的是类属性;如果在实例方法更改某个属性,并且存在同名的类属性,此时若实例对象有该名称的实例属性,则修改的是实例属性,若实例对象没有该名称的实例属性,则会创建一个同名称的实例属性。想要修改类属性,如果在类外,可以通过类对象修改,如果在类里面,只有在类方法中进行修改。
从类方法和实例方法以及静态方法的定义形式就可以看出来,类方法的第一个参数是类对象cls,那么通过cls引用的必定是类对象的属性和方法;而实例方法的第一个参数是实例对象self,那么通过self引用的可能是类属性、也有可能是实例属性(这个需要具体分析),不过在存在相同名称的类属性和实例属性的情况下,实例属性优先级更高。静态方法中不需要额外定义参数,因此在静态方法中引用类属性的话,必须通过类对象来引用。
3、继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过 继承 机制。继承完全可以理解成:类之间的类型和子类型 关系。
假设写个程序来记录学校中教师和学生情况。他们有一些共同属性,比如姓名、年龄和地址。他们也有专有的属性,比如教师的薪水、课程和假期,学生的成绩和学费。
可以为教师和学生建立两个独立的类来处理它们,但这样做的话,如果要增加一个新的共有属性,就意味着要在这两个独立的类中都增加这个属性。这很快就会显得不实用。
一个比较好的方法是创建一个共同的类称为SchoolMember然后让教师和学生的类 继承 这个共同的类。即它们都是这个类型(类)的子类型,然后我们再为这些子类型添加专有的属性。使用这种方法有很多优点。如果我们增加/改变了SchoolMember中的任何功能,它会自动地反映到子类型之中。例如,你要为教师和学生都增加一个新的身份证域,那么你只需简单地把它加到SchoolMember类中。然而,在一个子类型之中做的改动不会影响到别的子类型。另外一个优点是你可以把教师和学生对象都作为SchoolMember对象来使用,这在某些场合特别有用,比如统计学校成员的人数。一个子类型在任何需要父类型的场合可以被替换成父类型,即对象可以被视作是父类的实例,这种现象被称为多态现象。另外,我们会发现在 重用 父类的代码的时候,我们无需在不同的类中重复它。而如果我们使用独立的类的话,我们就不得不这么做了。
在上述的场合中,SchoolMember类被称为 基本类 或 超类 。而Teacher和Student类被称为导出类 或子类 。
使用继承
# !/usr/bin/python
# Filename: inherit.py
class SchoolMember:
"""Represents any school member."""
def __init__(self, name, age):
self.name = name
self.age = age
print('(Initialized SchoolMember: %s)' % self.name)
def tell(self):
"""Tell my details."""
print('Name:"%s" Age:"%s"' % (self.name, self.age))
class Teacher(SchoolMember):
"""Represents a teacher."""
def __init__(self, name, age, salary):
SchoolMember.__init__(self, name, age)
self.salary = salary
print('(Initialized Teacher: %s)' % self.name)
def tell(self):
SchoolMember.tell(self)
print('Salary: "%d"' % self.salary)
class Student(SchoolMember):
"""Represents a student."""
def __init__(self, name, age, marks):
SchoolMember.__init__(self, name, age)
self.marks = marks
print('(Initialized Student: %s)' % self.name)
def tell(self):
SchoolMember.tell(self)
print('Marks: "%d"' % self.marks)
t = Teacher('Mrs. Shrividya', 40, 30000)
s = Student('Swaroop', 22, 75)
print() # prints a blank line
members = [t, s]
for member in members:
member.tell() # works for both Teachers and Students
# 输出
# (Initialized SchoolMember: Mrs. Shrividya)
# (Initialized Teacher: Mrs. Shrividya)
# (Initialized SchoolMember: Swaroop)
# (Initialized Student: Swaroop)
#
# Name:"Mrs. Shrividya" Age:"40"
# Salary: "30000"
# Name:"Swaroop" Age:"22"
# Marks: "75"为了使用继承,我们把基本类的名称作为一个元组跟在定义类时的类名称之后。然后,我们注意到基本类的__init__方法专门使用self变量调用,这样我们就可以初始化对象的基本类部分。这一点十分重要——Python不会自动调用基本类的constructor,你得亲自专门调用它。我们还观察到我们在方法调用之前加上类名称前缀,然后把self变量及其他参数传递给它。注意,在我们使用SchoolMember类的tell方法的时候,我们把Teacher和Student的实例仅仅作为SchoolMember的实例。另外,在这个例子中,我们调用了子类型的tell方法,而不是SchoolMember类的tell方法。可以这样来理解,Python总是首先查找对应类型的方法,在这个例子中就是如此。如果它不能在导出类中找到对应的方法,它才开始到基本类中逐个查找。基本类是在类定义的时候,在元组之中指明的。一个术语的注释——如果在继承元组中列了一个以上的类,那么它就被称作 多重继承 。
继承语法 :
基类名写在括号里,基本类是在类定义的时候,在元组之中指明的。
class 派生类名( 基类1,[基类2, 基类3, ... 基类N] ):
pass示例:
class SubClassName (ParentClass1[, ParentClass2, ...]):
'Optional class documentation string'
class_suite单继承
示例:
# coding=utf-8
# !/usr/bin/python
class Parent: # 定义父类
parentAttr = 100
def __init__(self):
print("调用父类构造函数")
def parentMethod(self):
print('调用父类方法')
def setAttr(self, attr):
Parent.parentAttr = attr
def getAttr(self):
print("父类属性 :", Parent.parentAttr)
class Child(Parent): # 定义子类
def __init__(self):
print("调用子类构造方法")
def childMethod(self):
print('调用子类方法 child method')
c = Child() # 实例化子类
c.childMethod() # 调用子类的方法
c.parentMethod() # 调用父类方法
c.setAttr(200) # 再次调用父类的方法
c.getAttr() # 再次调用父类的方法执行结果如下:
调用子类构造方法
调用子类方法 child method
调用父类方法
父类属性 : 200多继承
如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。
class A: # 定义类 A
.....
class B: # 定义类 B
.....
class C(A, B): # 继承类 A 和 B
.....
可以使用 issubclass() 或者 isinstance() 方法来检测。
- issubclass():判断一个类是另一个类的子类或者子孙类,语法:issubclass(sub,sup)
- isinstance(obj, Class):如果 obj 是 Class类的实例对象或者是一个Class子类的实例对象则返回true。
继承中的一些特点
查找对应类型的方法时,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。
(先在本类中查找调用的方法,找不到才去基类中找)。继承中基类的构造(__init__()方法)不会被自动调用,它需要在其派生类的构造中亲自专门调用。
示例:
class A(object):
x = 1
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
print(A.x, B.x, C.x, D.x) # 1 1 1 1
C.x = 2
print(A.x, B.x, C.x, D.x) # 1 1 2 2
B.x = 3
print(A.x, B.x, C.x, D.x) # 1 3 2 3super() 【继承顺序说明】
class A:
def __init__(self):
print "enter A"
print "leave A"
class B(A):
def __init__(self):
print "enter B"
A.__init__(self)
print "leave B"
>>> b = B()
enter B
enter A
leave A
leave B使用非绑定的类方法(用类名来引用的方法),并在参数列表中,引入待绑定的对象(self),从而达到调用父类的目的。这样做的缺点是,当一个子类的父类发生变化时(如类B的父类由A变为C时),必须遍历整个类定义,把所有的通过非绑定的方法的类名全部替换过来,例如下面代码,
class B(C): # A --> C
def __init__(self):
print "enter B"
C.__init__(self) # A --> C
print "leave B"如果代码简单,这样的改动或许还可以接受。但如果代码量庞大,这样的修改可能是灾难性的。因此,自Python 2.2开始,Python 添加了一个关键字 super,来解决这个问题。
class A(object): # A must be new-style class
def __init__(self):
print "enter A"
print "leave A"
class B(C): # A --> C
def __init__(self):
print "enter B"
super(B, self).__init__()
print "leave B"尝试执行上面同样的代码,结果一致,但修改的代码只有一处,把代码的维护量降到最低,是一个不错的用法。因此在开发过程中,super 关键字被大量使用,
在我们的印象中,对于 super(B, self).__init__() 是这样理解的:super(B, self) 首先找到B的父类(就是类A),然后把类B的对象 self 转换为类A的对象,然后 "被转换" 的类A对象调用自己的__init__函数。考虑到 super 中只有指明子类的机制,因此,在多继承的类定义中,通常我们保留使用类似代码段1的方法。
有一天某同事设计了一个相对复杂的类体系结构(我们先不要管这个类体系设计得是否合理,仅把这个例子作为一个题目来研究就好),代码如下:
class A(object):
def __init__(self):
print "enter A"
print "leave A"
class B(object):
def __init__(self):
print "enter B"
print "leave B"
class C(A):
def __init__(self):
print "enter C"
super(C, self).__init__()
print "leave C"
class D(A):
def __init__(self):
print "enter D"
super(D, self).__init__()
print "leave D"
class E(B, C):
def __init__(self):
print "enter E"
B.__init__(self)
C.__init__(self)
print "leave E"
class F(E, D):
def __init__(self):
print "enter F"
E.__init__(self)
D.__init__(self)
print "leave F"
f = F()结果:
enter F
enter E
enter B
leave B
enter C
enter D
enter A
leave A
leave D
leave C
leave E
enter D
enter A
leave A
leave D
leave F
明显地,类A和类D的初始化函数被重复调用了2次,这并不是所期望的结果!期望的结果是最多只有类A的初始化函数被调用2次——其实这是多继承的类体系必须面对的问题。我们把代码段4的类体系画出来,如下图:
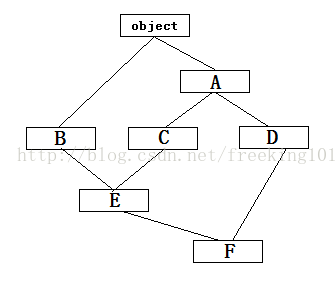
按我们对 super 的理解,从图中可以看出,在调用类C的初始化函数时,应该是调用类A的初始化函数,但事实上却调用了类D的初始化函数。好一个诡异的问题!
也就是说,mro中记录了一个类的所有基类的类类型序列。查看 mro 的记录,发觉包含7个元素,7个类名分别为:F E B C D A object
从而说明了为什么在 C.__init__ 中使用 super(C, self).__init__() 会调用类D的初始化函数了。
我们把代码段改写为:
class A(object):
def __init__(self):
print("enter A")
super(A, self).__init__() # new
print("leave A")
class B(object):
def __init__(self):
print("enter B")
super(B, self).__init__() # new
print("leave B")
class C(A):
def __init__(self):
print("enter C")
super(C, self).__init__()
print("leave C")
class D(A):
def __init__(self):
print("enter D")
super(D, self).__init__()
print("leave D")
class E(B, C):
def __init__(self):
print("enter E")
super(E, self).__init__() # change
print("leave E")
class F(E, D):
def __init__(self):
print("enter F")
super(F, self).__init__() # change
print("leave F")
f = F()结果:
enter F
enter E
enter B
enter C
enter D
enter A
leave A
leave D
leave C
leave B
leave E
leave F
Python 3 中 super 用法
class A(object):
def __init__(self):
print("enter A")
super().__init__()
print("leave A")
class B(object):
def __init__(self):
print("enter B")
super().__init__()
print("leave B")
class C(A):
def __init__(self):
print("enter C")
super().__init__()
print("leave C")
class D(A):
def __init__(self):
print("enter D")
super().__init__()
print("leave D")
class E(B, C):
def __init__(self):
print("enter E")
super().__init__()
print("leave E")
class F(E, D):
def __init__(self):
print("enter F")
super().__init__()
print("leave F")
f = F()
明显地,F 的初始化不仅完成了所有的父类的调用,而且保证了每一个父类的初始化函数只调用一次。再看类结构:

E-1,D-2 是 F 的父类,其中表示 E类在前,即 F(E,D)。所以初始化顺序可以从类结构图来看出 : F ---> E ---> B --> C --> D --> A
由于C,D 有同一个父类,因此会先初始化 D 再是 A。
延续的讨论
我们再重新看上面的类体系图,如果把每一个类看作图的一个节点,每一个从子类到父类的直接继承关系看作一条有向边,那么该体系图将变为一个有向图。不能发现mro的顺序正好是该有向图的一个拓扑排序序列。
从而,我们得到了另一个结果——Python是如何去处理多继承。支持多继承的传统的面向对象程序语言(如C++)是通过虚拟继承的方式去实现多继承中父类的构造函数被多次调用的问题,而Python则通过mro的方式去处理。
但这给我们一个难题:对于提供类体系的编写者来说,他不知道使用者会怎么使用他的类体系,也就是说,不正确的后续类,可能会导致原有类体系的错误,而且这样的错误非常隐蔽的,也难于发现。
小结
- Python 的多继承类是通过 mro 的方式来保证各个父类的函数被逐一调用,而且保证每个父类函数只调用一次(如果每个类都使用super);
- 混用 super类和 非绑定的函数 是一个危险行为,这可能导致应该调用的父类函数没有调用或者一个父类函数被调用多次。
方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法,示例:
#coding=utf-8
#!/usr/bin/python
class Parent: # 定义父类
def myMethod(self):
print '调用父类方法'
class Child(Parent): # 定义子类
def myMethod(self):
print '调用子类方法'
c = Child() # 子类实例
c.myMethod() # 子类调用重写方法输出结果如下:
调用子类方法
基础重载方法
Python 运算符重载
示例:
#!/usr/bin/python
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print v1 + v2
以上代码执行结果如下所示:
Vector(7,8)访问私有属性
类 的 私有属性:__private_attrs:两个下划线开头,声明该属性为私有,不能在类地外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
# coding=utf-8
# !/usr/bin/python
class JustCounter:
__secretCount = 0 # 私有变量
publicCount = 0 # 公开变量
def count(self):
self.__secretCount += 1
self.publicCount += 1
print(self.__secretCount)
counter = JustCounter()
counter.count()
counter.count()
print(counter.publicCount)
print(counter.__secretCount) # 报错,实例不能访问私有变量上面代码最后一行报错,因为 Python不允许 实例化的对象 访问私有数据,但你可以使用 object._className__attrName 访问属性。
将上面最后一行代码换成:print(counter._JustCounter__secretCount) 即可访问私有属性
python _、__和__xx__的区别
"_"单下划线
Python 中不存在真正的私有方法。为了实现类似于 C++ 中私有方法,可以在类的方法或属性前加一个 "_" 单下划线,意味着该方法或属性不应该去调用,它并不属于API。
在使用 property 时,经常出现这个问题:
class BaseForm(StrAndUnicode):
...
def _get_errors(self):
"Returns an ErrorDict for the data provided for the form"
if self._errors is None:
self.full_clean()
return self._errors
errors = property(_get_errors)上面的代码片段来自于 django 源码(django/forms/forms.py)。这里的 errors 是一个属性,属于 API 的一部分,但是 _get_errors 是私有的,是不应该访问的,但可以通过 errors 来访问该错误结果。
"__"双下划线
这个双下划线更会造成更多混乱,但它并不是用来标识一个方法或属性是私有的,真正作用是用来避免子类覆盖其内容。
让我们来看一个例子:
class A(object):
def __method(self):
print "I'm a method in A"
def method(self):
self.__method()
a = A()
a.method()输出是这样的:
$ python example.py
I'm a method in A很好,出现了预计的结果。 现在我们给A添加一个子类,并重新实现一个__method:
class B(A):
def __method(self):
print "I'm a method in B"
b = B()
b.method()现在,结果是这样的:
$ python example.py
I'm a method in A就像我们看到的一样,B.method()不能调用B.__method的方法。实际上,它是"__"两个下划线的功能的正常显示。
因此,在我们创建一个以"__"两个下划线开始的方法时,这意味着这个方法不能被重写,它只允许在该类的内部中使用。
在Python中如是做的?很简单,它只是把方法重命名了,如下:
a = A()
a._A__method() # never use this!! please!
$ python example.py
I'm a method in A如果你试图调用a.__method,它还是无法运行的,就如上面所说,只可以在类的内部调用__method。
"__xx__"前后各双下划线 (特殊的属性和方法)
当你看到"__this__"的时,就知道不要调用它。为什么?因为它的意思是它是用于Python调用的,如下:
>>> name = "igor"
>>> name.__len__() 4
>>> len(name) 4
>>> number = 10
>>> number.__add__(20) 30
>>> number + 20 30“__xx__”经常是操作符或本地函数调用的magic methods。在上面的例子中,提供了一种重写类的操作符的功能。
在特殊的情况下,它只是python调用的hook。例如,__init__()函数是当对象被创建初始化时调用的;__new__()是用来创建实例。
class CrazyNumber(object):
def __init__(self, n):
self.n = n
def __add__(self, other):
return self.n - other
def __sub__(self, other):
return self.n + other
def __str__(self):
return str(self.n)
num = CrazyNumber(10)
print num # 10
print num + 5 # 5
print num - 20 # 30 另一个例子
class Room(object):
def __init__(self):
self.people = []
def add(self, person):
self.people.append(person)
def __len__(self):
return len(self.people)
room = Room()
room.add("Igor")
print len(room) # 1结论
- 使用 _one_underline 来表示该方法或属性是私有的,不属于API;
- 当创建一个用于 python 调用或一些特殊情况时,使用 __two_underline__;
- 使用 __just_to_underlines,来避免子类的重写!
在Python中没有像C++中public和private这些关键字来区别公有属性和私有属性,它是以属性命名方式来区分,如果在属性名前面加了2个下划线'__',则表明该属性是私有属性,否则为公有属性(方法也是一样,方法名前面加了2个下划线的话表示该方法是私有的,否则为公有的)。
4、多 态
多态即多种形态,在运行时确定其状态,在编译阶段无法确定其类型,这就是多态。Python中的多态和Java以及C++中的多态有点不同,Python中的变量是弱类型的,在定义时不用指明其类型,它会根据需要在运行时确定变量的类型(个人觉得这也是多态的一种体现),并且Python本身是一种解释性语言,不进行预编译,因此它就只在运行时确定其状态,故也有人说Python是一种多态语言。在Python中很多地方都可以体现多态的特性,比如内置函数len(object),len函数不仅可以计算字符串的长度,还可以计算列表、元组等对象中的数据个数,这里在运行时通过参数类型确定其具体的计算过程,正是多态的一种体现。这有点类似于函数重载(一个编译单元中有多个同名函数,但参数不同),相当于为每种类型都定义了一个len函数。这是典型的多态表现。有些朋友提出Python不支持多态,我是完全不赞同的。
本质上,多态意味着可以对不同的对象使用同样的操作,但它们可能会以多种形态呈现出结果。len(object)函数就体现了这一点。在C++、Java、C#这种编译型语言中,由于有编译过程,因此就鲜明地分成了运行时多态和编译时多态。运行时多态是指允许父类指针或名称来引用子类对象,或对象方法,而实际调用的方法为对象的类类型方法,这就是所谓的动态绑定。编译时多态有模板或范型、方法重载(overload)、方法重写(override)等。而Python是动态语言,动态地确定类型信息恰恰体现了多态的特征。在Python中,任何不知道对象到底是什么类型,但又需要对象做点什么的时候,都会用到多态。
方法多态
# -*- coding: UTF-8 -*-
_metaclass_ = type # 确定使用新式类
class Calculator:
def count(self, args):
return 1
calc = Calculator() # 自定义类型
from random import choice
obj = choice(['hello,world', [1, 2, 3], calc]) # obj是随机返回的 类型不确定
print(type(obj))
print(obj.count('a')) # 方法多态对于一个临时对象 obj,它通过 Python 的随机函数取出来,不知道具体类型(是字符串、元组还是自定义类型),都可以调用count方法进行计算,至于count由谁(哪种类型)去做怎么去实现我们并不关心。
有一种称为 "鸭子类型( duck typing )" 的东西,讲的也是多态:
_metaclass_ = type # 确定使用新式类
class Duck:
def quack(self):
print("Quaaaaaack!")
def feathers(self):
print("The duck has white and gray feathers.")
class Person:
def quack(self):
print("The person imitates a duck.")
def feathers(self):
print("The person takes a feather from the ground and shows it.")
def in_the_forest(duck):
duck.quack()
duck.feathers()
def game():
donald = Duck()
john = Person()
in_the_forest(donald)
in_the_forest(john)
game()就 in_the_forest 函数而言,参数对象是一个鸭子类型,它实现了方法多态。但是实际上我们知道,从严格的抽象来讲,Person类型和 Duck 完全风马牛不相及。
运算符多态
def add(x, y):
return x + y
print(add(1, 2)) # 输出3
print(add("hello,", "world")) # 输出hello,world
print(add(1, "abc")) # 抛出异常 TypeError: unsupported operand type(s) for +: 'int' and 'str'上例中,显而易见,Python 的加法运算符是 "多态" 的,理论上,我们实现的add方法支持任意支持加法的对象,但是我们不用关心两个参数x和y具体是什么类型。
Python同样支持运算符重载,实例如下:
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self, other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2, 10)
v2 = Vector(5, -2)
print(v1 + v2)一两个示例代码当然不能从根本上说明多态。普遍认为面向对象最有价值最被低估的特征其实是多态。我们所理解的多态的实现和子类的虚函数地址绑定有关系,多态的效果其实和函数地址运行时动态绑定有关。在C++, Java, C#中实现多态的方式通常有重写和重载两种,从上面两段代码,我们其实可以分析得出Python中实现多态也可以变相理解为重写和重载。在Python中很多内置函数和运算符都是多态的。
5、面向对象高级编程
使用__slots__
正常情况下,当定义一个class,创建了一个class的实例后,可以给该实例绑定任何属性和方法,这就是动态语言的灵活性。先定义class:
class Student(object):
pass
然后,尝试给实例绑定一个属性:
>>> s = Student()
>>> s.name = 'Michael' # 动态给实例绑定一个属性
>>> print(s.name)
Michael
还可以尝试给实例绑定一个方法:
>>> def set_age(self, age): # 定义一个函数作为实例方法
... self.age = age
...
>>> from types import MethodType
>>> s.set_age = MethodType(set_age, s) # 给实例绑定一个方法
>>> s.set_age(25) # 调用实例方法
>>> s.age # 测试结果
25
但是,给一个实例绑定的方法,对另一个实例是不起作用的:
>>> s2 = Student() # 创建新的实例
>>> s2.set_age(25) # 尝试调用方法
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Student' object has no attribute 'set_age'
为了给所有实例都绑定方法,可以给class绑定方法:
>>> def set_score(self, score):
... self.score = score
...
>>> Student.set_score = set_score给class绑定方法后,所有实例均可调用:
>>> s.set_score(100)
>>> s.score
100
>>> s2.set_score(99)
>>> s2.score
99
通常情况下,上面的 set_score 方法可以直接定义在 class 中,但动态绑定允许在程序运行的过程中动态给class加上功能,这在静态语言中很难实现。
使用__slots__
但是,如果我们想要限制实例的属性怎么办?比如,只允许对Student实例添加name和age属性。
为了达到限制的目的,Python允许在定义class的时候,定义一个特殊的__slots__变量,来限制该class实例能添加的属性:
class Student(object):
__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
然后,我们试试:
>>> s = Student() # 创建新的实例
>>> s.name = 'Michael' # 绑定属性'name'
>>> s.age = 25 # 绑定属性'age'
>>> s.score = 99 # 绑定属性'score'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Student' object has no attribute 'score'
由于'score'没有被放到__slots__中,所以不能绑定score属性,试图绑定score将得到AttributeError的错误。
使用__slots__要注意:__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的:
>>> class GraduateStudent(Student):
... pass
...
>>> g = GraduateStudent()
>>> g.score = 9999
除非在子类中也定义__slots__,这样,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__。
使用 @property
在绑定属性时,如果我们直接把属性暴露出去,虽然写起来很简单,但是,没办法检查参数,导致可以把成绩随便改:
s = Student()
s.score = 9999
这显然不合逻辑。为了限制score的范围,可以通过一个set_score()方法来设置成绩,再通过一个get_score()来获取成绩,这样,在set_score()方法里,就可以检查参数:
class Student(object):
def get_score(self):
return self._scoredef set_score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
现在,对任意的Student实例进行操作,就不能随心所欲地设置score了:
>>> s = Student()
>>> s.set_score(60) # ok!
>>> s.get_score()
60
>>> s.set_score(9999)
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!
但是,上面的调用方法又略显复杂,没有直接用属性这么直接简单。
有没有既能检查参数,又可以用类似属性这样简单的方式来访问类的变量呢?对于追求完美的Python程序员来说,这是必须要做到的!
还记得装饰器(decorator)可以给函数动态加上功能吗?对于类的方法,装饰器一样起作用。Python内置的@property装饰器就是负责把一个方法变成属性调用的:
class Student(object):
@property
def score(self):
return self._score@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
@property的实现比较复杂,先看如何使用。把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值,于是,我们就拥有一个可控的属性操作:
>>> s = Student()
>>> s.score = 60 # OK,实际转化为s.set_score(60)
>>> s.score # OK,实际转化为s.get_score()
60
>>> s.score = 9999
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!
注意到这个神奇的@property,我们在对实例属性操作的时候,就知道该属性很可能不是直接暴露的,而是通过getter和setter方法来实现的。
还可以定义只读属性,只定义getter方法,不定义setter方法就是一个只读属性:
class Student(object):
@property
def birth(self):
return self._birth@birth.setter
def birth(self, value):
self._birth = value@property
def age(self):
return 2015 - self._birth
上面的 birth 是可读写属性,而age就是一个只读属性,因为age可以根据birth和当前时间计算出来。要特别注意:属性的方法名不要和实例变量重名。例如,以下的代码是错误的:
class Student(object):
# 方法名称和实例变量均为birth:
@property
def birth(self):
return self.birth这是因为调用s.birth时,首先转换为方法调用,在执行return self.birth时,又视为访问self的属性,于是又转换为方法调用,造成无限递归,最终导致栈溢出报错RecursionError。
小结:@property广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性。
Python中有一个被称为属性函数(property)的小概念,它可以做一些有用的事情。在这篇文章中,我们将看到如何能做以下几点:
- 将类方法转换为只读属性
- 重新实现一个属性的setter和getter方法
在本文中,您将学习如何以几种不同的方式来使用内置的属性函数。希望读到文章的末尾时,你能看到它是多么有用。
开始
使用属性函数的最简单的方法之一是将它作为一个方法的装饰器来使用。这可以让你将一个类方法转变成一个类属性。当我需要做某些值的合并时,我发现这很有用。其他想要获取它作为方法使用的人,发现在写转换函数时它很有用。让我们来看一个简单的例子:
########################################################################
class Person(object):
""""""
#----------------------------------------------------------------------
def __init__(self, first_name, last_name):
"""Constructor"""
self.first_name = first_name
self.last_name = last_name
#----------------------------------------------------------------------
@property
def full_name(self):
"""
Return the full name
"""
return "%s %s" % (self.first_name, self.last_name)在上面的代码中,我们创建了两个类属性:self.first_name和self.last_name。接下来,我们创建了一个full_name方法,它有一个@property装饰器。这使我们能够在Python解释器会话中有如下的交互:
>>> person = Person("Mike", "Driscoll")
>>> person.full_name
'Mike Driscoll'
>>> person.first_name
'Mike'
>>> person.full_name = "Jackalope"
Traceback (most recent call last):
File "<string>", line 1, in <fragment>
AttributeError: can't set attribute正如你所看到的,因为我们将方法变成了属性,我们可以使用正常的点符号访问它。但是,如果我们试图将该属性设为其他值,我们会引发一个AttributeError错误。改变full_name属性的唯一方法是间接这样做:
>>> person.first_name = "Dan"
>>> person.full_name
'Dan Driscoll'这是一种限制,因此让我们来看看另一个例子,其中我们可以创建一个允许设置的属性。
使用Python property取代setter和getter方法
让我们假设我们有一些遗留代码,它们是由一些对Python理解得不够好的人写的。如果你像我一样,你之前已经看到过这类的代码:
from decimal import Decimal
########################################################################
class Fees(object):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
self._fee = None
#----------------------------------------------------------------------
def get_fee(self):
"""
Return the current fee
"""
return self._fee
#----------------------------------------------------------------------
def set_fee(self, value):
"""
Set the fee
"""
if isinstance(value, str):
self._fee = Decimal(value)
elif isinstance(value, Decimal):
self._fee = value要使用这个类,我们必须要使用定义的getter和setter方法:
>>> f = Fees()
>>> f.set_fee("1")
>>> f.get_fee()
Decimal('1')如果你想添加可以使用正常点符号访问的属性,而不破坏所有依赖于这段代码的应用程序,你可以通过添加一个属性函数非常简单地改变它:
from decimal import Decimal
########################################################################
class Fees(object):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
self._fee = None
#----------------------------------------------------------------------
def get_fee(self):
"""
Return the current fee
"""
return self._fee
#----------------------------------------------------------------------
def set_fee(self, value):
"""
Set the fee
"""
if isinstance(value, str):
self._fee = Decimal(value)
elif isinstance(value, Decimal):
self._fee = value
fee = property(get_fee, set_fee)我们在这段代码的末尾添加了一行。现在我们可以这样做:
>>> f = Fees()
>>> f.set_fee("1")
>>> f.fee
Decimal('1')
>>> f.fee = "2"
>>> f.get_fee()
Decimal('2')正如你所看到的,当我们以这种方式使用属性函数时,它允许fee属性设置并获取值本身而不破坏原有代码。让我们使用属性装饰器来重写这段代码,看看我们是否能得到一个允许设置的属性值。
from decimal import Decimal
########################################################################
class Fees(object):
""""""
#----------------------------------------------------------------------
def __init__(self):
"""Constructor"""
self._fee = None
#----------------------------------------------------------------------
@property
def fee(self):
"""
The fee property - the getter
"""
return self._fee
#----------------------------------------------------------------------
@fee.setter
def fee(self, value):
"""
The setter of the fee property
"""
if isinstance(value, str):
self._fee = Decimal(value)
elif isinstance(value, Decimal):
self._fee = value
#----------------------------------------------------------------------
if __name__ == "__main__":
f = Fees()上面的代码演示了如何为fee属性创建一个setter方法。你可以用一个名为@fee.setter的装饰器装饰第二个方法名也为fee的方法来实现这个。当你如下所做时,setter被调用:
>>> f = Fees()
>>> f.fee = "1"如果你看属性函数的说明,它有fget, fset, fdel和doc几个参数。如果你想对属性使用del命令,你可以使用@fee.deleter创建另一个装饰器来装饰相同名字的函数从而实现删除的同样效果。
定制类:__str__、__iter__、__getitem__、__getattr__、__call__
:https://docs.python.org/zh-cn/3/reference/datamodel.html#special-method-names
class Student(object):
def __init__(self, name):
self.name = namedef __str__(self):
return 'Student object (name: %s)' % self.name__repr__ = __str__
print(Student('Michael'))
class Fib111(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器a,bdef __iter__(self):
return self # 实例本身就是迭代对象,故返回自己def __next__(self):
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 100000: # 退出循环的条件
raise StopIteration()
return self.a # 返回下一个值
class Fib222(object):
def __getitem__(self, n):
if isinstance(n, int): # n是索引
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
if isinstance(n, slice): # n是切片
start = n.start
stop = n.stop
if start is None:
start = 0
a, b = 1, 1
L = []
for x in range(stop):
if x >= start:
L.append(a)
a, b = b, a + b
return L
for n in Fib111():
print(n)f = Fib222()
print(f[0:5])
# [1, 1, 2, 3, 5]
print(f[:10])
# [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
class Chain(object):
def __init__(self, path=''):
self._path = pathdef __getattr__(self, path):
return Chain('%s/%s' % (self._path, path))def __str__(self):
return self._path__repr__ = __str__
print(Chain().status.user.timeline.list)
print(Chain().one.two.three.four)
这样,无论属性存不存在,都可以完全动态的生成和调用。
class Student(object):
def __init__(self, name):
self.name = namedef __call__(self):
print('My name is %s.' % self.name)
s = Student('Michael')
s()
__call__()还可以定义参数。对实例进行直接调用就好比对一个函数进行调用一样,所以你完全可以把对象看成函数,把函数看成对象,因为这两者之间本来就没啥根本的区别。
如果你把对象看成函数,那么函数本身其实也可以在运行期动态创建出来,因为类的实例都是运行期创建出来的,这么一来,我们就模糊了对象和函数的界限。
那么,怎么判断一个变量是对象还是函数呢?其实,更多的时候,我们需要判断一个对象是否能被调用,能被调用的对象就是一个Callable对象,通过callable()函数,我们就可以判断一个对象是否是“可调用”对象。
使用枚举类
当需要定义常量时,一个办法是用大写变量通过整数来定义,例如月份:
JAN = 1
FEB = 2
MAR = 3
...
NOV = 11
DEC = 12
好处是简单,缺点是类型是int,并且仍然是变量。
更好的方法是为这样的枚举类型定义一个class类型,然后,每个常量都是class的一个唯一实例。Python提供了Enum类来实现这个功能:
from enum import Enum
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
这样我们就获得了Month类型的枚举类,可以直接使用Month.Jan来引用一个常量,或者枚举它的所有成员:
for name, member in Month.__members__.items():
print(name, '=>', member, ',', member.value)
value属性则是自动赋给成员的int常量,默认从1开始计数。
如果需要更精确地控制枚举类型,可以从Enum派生出自定义类:
from enum import Enum, unique
@unique
class Weekday(Enum):
Sun = 0 # Sun的value被设定为0
Mon = 1
Tue = 2
Wed = 3
Thu = 4
Fri = 5
Sat = 6
@unique装饰器可以帮助我们检查保证没有重复值。
访问这些枚举类型可以有若干种方法:
>>> day1 = Weekday.Mon
>>> print(day1)
>>> print(Weekday.Tue)
>>> print(Weekday['Tue'])
>>> print(Weekday.Tue.value)
>>> print(day1 == Weekday.Mon)
>>> print(day1 == Weekday.Tue)
>>> print(Weekday(1))
>>> print(day1 == Weekday(1))
>>> Weekday(7)
Traceback (most recent call last):
...
ValueError: 7 is not a valid Weekday
>>> for name, member in Weekday.__members__.items():
可见,既可以用成员名称引用枚举常量,又可以直接根据value的值获得枚举常量。
使用元类
__new__函数
创建一个实例的时候,实际上是先调用的__new__函数创建实例,然后再调用__init__对实例进行的初始化。
class Test:
def __new__(cls):
print('__new__')
return object().__new__(cls)
def __init__(self):
print('__init__')
单例模式
class SingletonObject:
def __new__(cls, *args, **kwargs):
if not hasattr(SingletonObject, "_instance"):
SingletonObject._instance = object.__new__(cls)
return SingletonObject._instance
def __init__(self):
pass
当然,如果是在并发场景当中使用,还需要加上线程锁防止并发问题,但逻辑是一样的。
除了可以实现一些功能之外,还可以控制实例的创建。因为Python当中是先调用的__new__再调用的__init__,所以如果当调用__new__的时候返回了None,那么最后得到的结果也是None。通过这个特性,我们可以控制类的创建。比如设置条件,只有在满足条件的时候才能正确创建实例,否则会返回一个None。
比如我们想要创建一个类,它是一个int,但是不能为0值,我们就可以利用__new__的这个特性来实现:
class NonZero(int):
def __new__(cls, value):
return super().__new__(cls, value) if value != 0 else None
那么当我们用0值来创建它的时候就会得到一个None,而不是一个实例。
工厂模式
所谓的工厂模式是指通过一个接口,根据参数的取值来创建不同的实例。创建过程的逻辑对外封闭,用户不必关系实现的逻辑。就好比一个工厂可以生产多种零件,用户并不关心生产的过程,只需要告知需要零件的种类。也因此称为工厂模式。
比如说我们来创建一系列游戏的类:
class Last_of_us:
def play(self):
print('the Last Of Us is really funny')
class Uncharted:
def play(self):
print('the Uncharted is really funny')
class PSGame:
def play(self):
print('PS has many games')
然后这个时候我们希望可以通过一个接口根据参数的不同返回不同的游戏,如果不通过__new__,这段逻辑就只能写成函数而不能通过面向对象来实现。通过重载__new__我们就可以很方便地用参数来获取不同类的实例:
class GameFactory:
games = {'last_of_us': Last_Of_us, 'uncharted': Uncharted}
def __new__(cls, name):
if name in cls.games:
return cls.games[name]()
else:
return PSGame()
uncharted = GameFactory('uncharted')
last_of_us = GameFactory('last_of_us')
另一个经常使用__new__场景是元类
type() 动态创建 类
动态语言不同于静态语言的是:就是函数和类的定义,不是编译时定义的,而是运行时动态创建的。比方说我们要定义一个 Hello 的 class,就写一个 hello.py 模块:
class Hello(object):
def hello(self, name='world'):
print('Hello, %s.' % name)
当 Python 解释器载入 hello 模块时,就会依次执行该模块的所有语句,执行结果就是动态创建出一个 Hello 的 class 对象,测试如下:
>>> from hello import Hello
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
<class 'type'>
>>> print(type(h))
<class 'hello.Hello'>
type() 函数可以查看一个类型或变量的类型,
Hello 是一个class,它的类型就是type,
h 是一个实例,它的类型就是class Hello
我们说 class 的定义是运行时动态创建的,而创建 class 的方法就是使用type()函数,type()函数既可以返回一个对象的类型,又可以创建出新的类型,比如,我们可以通过 type() 函数创建出Hello类,而无需通过 class Hello(object)... 的定义:
>>> def fn(self, name='world'): # 先定义函数
... print('Hello, %s.' % name)
...
>>> Hello = type('Hello', (object,), dict(hello=fn)) # 创建Hello class
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
<class 'type'>
>>> print(type(h))
<class '__main__.Hello'>
要创建一个class对象,type()函数依次传入3个参数:
- class 的名称;
- 继承的父类集合。Python 支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;
- class 的方法名称与函数绑定,这里我们把函数
fn绑定到方法名hello上。
通过 type() 函数创建的类和直接写class是完全一样的,因为 Python 解释器遇到 class 定义时,仅仅是扫描一下 class 定义的语法,然后调用 type() 函数创建出 class。
正常情况下,我们都用class Xxx...来定义类,但是,type()函数也允许我们动态创建出类来,也就是说,动态语言本身支持运行期动态创建类,这和静态语言有非常大的不同,要在静态语言运行期创建类,必须构造源代码字符串再调用编译器,或者借助一些工具生成字节码实现,本质上都是动态编译,会非常复杂。
metaclass 创建类或者修改类
除了使用type()动态创建类以外,要控制类的创建行为,还可以使用 metaclass。
metaclass,直译为元类,简单的解释就是:当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
但是如果我们想创建出类呢?那就必须根据metaclass创建出类,所以:先定义metaclass,然后创建类。连接起来就是:先定义metaclass,就可以创建类,最后创建实例。
所以,metaclass 允许你创建类或者修改类。换句话说,你可以把类看成是metaclass创建出来的“实例”。
通俗的理解:认为 "元类" 是 "类的类" 的意思即可。
metaclass 是 Python 面向对象里最难理解,也是最难使用的魔术代码。正常情况下,你不会碰到需要使用 metaclass 的情况,所以,以下内容看不懂也没关系,因为基本上你不会用到。
一个经典示例:使用 metaclass 给我们自定义的 MyList 增加一个 add 方法。首先定义ListMetaclass,按照默认习惯,metaclass 的类名总是以 Metaclass 结尾,以便清楚地表示这是一个 metaclass:
# metaclass 是类的模板,所以必须从 `type` 类型派生:
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):# 在类属性当中添加了 add 函数
# 通过匿名函数映射到 append 函数上
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
注意:在 ListMetaclass 当中为 attrs 添加了一个名叫 'add' 的属性。这个属性是添加给类的,而不是类初始化出来的实例的。所以如果print 出 MyList 这个类当中的所有属性,也能看到 add 的存在。
有了ListMetaclass,我们在定义类的时候还要指示使用 ListMetaclass 来定制类,传入关键字参数metaclass:
class MyList(list, metaclass=ListMetaclass):
pass
当我们传入关键字参数 metaclass 时,魔术就生效了,它指示 Python 解释器在创建 MyList 时,要通过 ListMetaclass.__new__() 来创建,在此,我们可以修改类的定义,比如,加上新的方法,然后,返回修改后的定义。
__new__()方法接收到的参数依次是:
- 当前准备创建的类的对象;
- 类的名字;
- 类继承的父类集合;
- 类的方法集合。
测试一下 MyList 是否可以调用add()方法:

而普通的 list 没有 add() 方法:
>>> L2 = list()
>>> L2.add(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'add'
动态修改有什么意义?直接在 MyList 定义中写上 add() 方法不是更简单吗?正常情况下,确实应该直接写,通过 metaclass 修改纯属变态。
但是,总会遇到需要通过 metaclass 修改类定义的。ORM 就是一个典型的例子。
ORM全称“Object Relational Mapping”,即对象-关系映射,就是把关系数据库的一行映射为一个对象,也就是一个类对应一个表,这样,写代码更简单,不用直接操作SQL语句。
要编写一个ORM框架,所有的类都只能动态定义,因为只有使用者才能根据表的结构定义出对应的类来。
让我们来尝试编写一个ORM框架。
编写底层模块的第一步,就是先把调用接口写出来。比如,使用者如果使用这个ORM框架,想定义一个User类来操作对应的数据库表User,我们期待他写出这样的代码:
class User(Model):
# 定义类的属性到列的映射:
id = IntegerField('id')
name = StringField('username')
email = StringField('email')
password = StringField('password')# 创建一个实例:
u = User(id=12345, name='Michael', email='test@orm.org', password='my-pwd')
# 保存到数据库:
u.save()
其中,父类Model和属性类型StringField、IntegerField是由ORM框架提供的,剩下的魔术方法比如save()全部由父类Model自动完成。虽然metaclass的编写会比较复杂,但ORM的使用者用起来却异常简单。
现在,我们就按上面的接口来实现该ORM。
首先来定义Field类,它负责保存数据库表的字段名和字段类型:
class Field(object):
def __init__(self, name, column_type):
self.name = name
self.column_type = column_typedef __str__(self):
return '<%s:%s>' % (self.__class__.__name__, self.name)
在Field的基础上,进一步定义各种类型的Field,比如StringField,IntegerField等等:
class StringField(Field):
def __init__(self, name):
super(StringField, self).__init__(name, 'varchar(100)')class IntegerField(Field):
def __init__(self, name):
super(IntegerField, self).__init__(name, 'bigint')
下一步,就是编写最复杂的ModelMetaclass了:
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
if name=='Model':
return type.__new__(cls, name, bases, attrs)
print('Found model: %s' % name)
mappings = dict()
for k, v in attrs.items():
if isinstance(v, Field):
print('Found mapping: %s ==> %s' % (k, v))
mappings[k] = v
for k in mappings.keys():
attrs.pop(k)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
attrs['__table__'] = name # 假设表名和类名一致
return type.__new__(cls, name, bases, attrs)
以及基类Model:
class Model(dict, metaclass=ModelMetaclass):
def __init__(self, **kw):
super(Model, self).__init__(**kw)def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Model' object has no attribute '%s'" % key)def __setattr__(self, key, value):
self[key] = valuedef save(self):
fields = []
params = []
args = []
for k, v in self.__mappings__.items():
fields.append(v.name)
params.append('?')
args.append(getattr(self, k, None))
sql = 'insert into %s (%s) values (%s)' % (self.__table__, ','.join(fields), ','.join(params))
print('SQL: %s' % sql)
print('ARGS: %s' % str(args))
当用户定义一个class User(Model)时,Python解释器首先在当前类User的定义中查找metaclass,如果没有找到,就继续在父类Model中查找metaclass,找到了,就使用Model中定义的metaclass的ModelMetaclass来创建User类,也就是说,metaclass可以隐式地继承到子类,但子类自己却感觉不到。
在ModelMetaclass中,一共做了几件事情:
-
排除掉对
Model类的修改; -
在当前类(比如
User)中查找定义的类的所有属性,如果找到一个Field属性,就把它保存到一个__mappings__的dict中,同时从类属性中删除该Field属性,否则,容易造成运行时错误(实例的属性会遮盖类的同名属性); -
把表名保存到
__table__中,这里简化为表名默认为类名。
在Model类中,就可以定义各种操作数据库的方法,比如save(),delete(),find(),update等等。
我们实现了save()方法,把一个实例保存到数据库中。因为有表名,属性到字段的映射和属性值的集合,就可以构造出INSERT语句。
编写代码试试:
u = User(id=12345, name='Michael', email='test@orm.org', password='my-pwd')
u.save()
输出如下:
Found model: User
Found mapping: email ==> <StringField:email>
Found mapping: password ==> <StringField:password>
Found mapping: id ==> <IntegerField:uid>
Found mapping: name ==> <StringField:username>
SQL: insert into User (password,email,username,id) values (?,?,?,?)
ARGS: ['my-pwd', 'test@orm.org', 'Michael', 12345]
可以看到,save()方法已经打印出了可执行的SQL语句,以及参数列表,只需要真正连接到数据库,执行该SQL语句,就可以完成真正的功能。
不到100行代码,我们就通过metaclass实现了一个精简的ORM框架,是不是非常简单?
小结:metaclass是Python中非常具有魔术性的对象,它可以改变类创建时的行为。这种强大的功能使用起来务必小心。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









