







目录
一、软件项目的认识
软件项目:是指使用编程语言开发的一套程序或软件,通常包含多个代码文件、模块、包以及相关资源,他们协同工作以实现特定的功能或解决特定的问题,除功能外还体现了一定的结构组织性。
软件项目包含的 常见功能性 和 组织性成分如下:
- .py文件:是Python中最基本的源代码程序文件,用于存储纯文本形式的源代码。开发者通过编辑.py文件来编写程序,它包含函数、类、变量定义以及执行逻辑,由Python解释器直接读取并执行,是编写和执行Python程序的主要载体。
- 模块(Module):按照Python的惯用约定,模块通常与.py文件重合,对应一个包含函数定义、类定义、变量赋值的.py文件。模块可以被其他Python代码导入,以实现代码和功能重用。
与.py文件的区别:模块名是对功能的一种抽象表示,它暂时不直接对应具体的文件名或文件位置,执行时由Python解释器通过一定的机制动态(如搜索路径)对应到.py文件。
注意:意味着同一个模块名可以对应不同的.py文件,取决于当前工作路径里包含的.py名和解释器搜索路径里包含的.py名与模块名的对照一致性。
- 包:包是包含多个模块的文件夹,其中包含一个特殊的__init__.py文件(即使这个文件为空也可以)。包允许开发者按不同设计目的,实现结构清晰的组织模块和代码。例如,你可以创建一个名为mypackage的文件夹,其中包含一个__init__.py文
包、文件、模块形成了不同的层次区域性的、自己的命名空间,在此区间里不允许同名。意味着不同层次中的命名可以是相同的,而不会相互干扰,主要作用总结:
- 封装性:可以将一系列相关的函数和变量封装起来,形成一个独立的命名空间。
- 可重用性:通过导入,可以在不同的程序中重复使用。
- 组织性:可以帮助你组织代码,使得代码更加清晰、易于维护
命名空间(Namespace)是一种用于组织代码和防止命名冲突的重要机制。通过命名空间,开发者可以将标识符(如变量、函数、类等)封装在一个独立的作用域中,从而避免不同模块或库中的同名标识符发生冲突。
Python中的命名空间主要有内置、全局和局部三种类型。内置命名空间在解释器启动时创建,自动映射到全局空间,全局命名空间在模块定义时创建,局部命名空间在函数调用时创建。
二、软件的规模认识
软件按规模划分:
- 微型:代码行数较少,功能简单一,一般代码行数在两千行以内,通常一个人完成。
- 小型:功能较为单一或几个核心功能,代码行数在几千到几万行之间的项目,团队规模较小约1到5人。
- 中型:功能较为复杂,代码行数在几万到几,团队规模较约6到15人。
- 大型项:代码行数超过几十万行,甚至可能达到百万级。团队规模约16到50人。
三、如何应对规模较大的软件开发——软件架构
应对大规模软件开发的手段包括:需求管理机制、技术架构设计、开发过程控制、团队协作优化。这里只谈架构方面。
软件架构 是指软件系统中各要素的基本结构和组织方式,它定义了软件系统的各个部分之间的关系和交互方式,以及系统的整体设计方案。软件架构设计包括软件的组成部分和模块的划分、以及它们之间的关系和依赖等。
软件架构作用:软件架构是开发项目的蓝图,是设计团队布置需要执行的任务的依据,使复杂问题被规划成规模合理的子问题,简化问题,有助于提高系统的可维护性、可扩展性和可重用性,同时体现了工程思维。软件架构具体规划了如下内容:
- 软件的组成构件和功能:系统要实现的功能和业务是什么。
- 软件系统的性能和可靠性:包括系统的响应速度、容错能力、可用性和安全性等方面。
- 软件系统的接口和交互:包括系统内部构件间交互,软件系统与外界的接口和交互方式,涉及与用户的交互、与其他系统的数据交换等。
- 软件系统的部署和维护:考虑系统的可部署性、可配置性、可测试性和可监控性等方面。
1、常见软件架构:
- 分层架构:是最常见的架构模式之一,通常被称为n层架构。它将软件分为多个层次,如展现层、业务逻辑层和持久层。这种架构有助于提高代码的可维护性和可扩展性,但可能会导致性能下降,并且增加系统生产成本和复杂性。
- 事件驱动架构:组件通过事件进行通信,适用于需要高度解耦的系统,如实时数据处理和异步工作流。这种架构可以提高系统的响应速度和灵活性,但不适合交互性强的系统。
- 微服务架构:将应用程序划分为一组小的、松散耦合的服务,每个服务实现特定的业务功能并通过轻量级通信机制(如HTTP RESTful API)相互协作。适用于需要高度可扩展性和灵活性的大型复杂应用。
2、分层架构的设计:
在软件工程中,分层架构是一种将应用或系统划分为多个独立层次(或模块)的方法,每个层次负责不同的功能。分层架构的主要目的是降低层与层之间的依赖,实现功能模块的合理粒度规划和高内聚低耦合,以提高系统的灵活性和可维护性,同时实现开发任务的可控划分、分配与高效管理,这是分层架构软件设计的重点和精髓。
分层架构通常包括用户接口层、应用层、领域层(可选)和基础层。分层架构的实现是如何体现的,首先体现在项目的结构上,如下:

四、分层架构的python综合例子:
1、项目简介:
名称students_Score
功能包含登录注册功能、成绩录入与成绩可视化;
数据表成绩表(包含数学、英语、专业课字段)用户表(包含用户名和密码字段)。
系统软件的分层架构:数据访问层model,服务控制层service,界面显示层view。
特点:每层间的依赖是单向的,非跳跃的,通过分层设计,系统各层之间的依赖关系被明确界定,降低了层与层之间的耦合度,从而提高了系统的灵活性和可维护性。
2、项目的分层结构与文件组织结构的对照图:
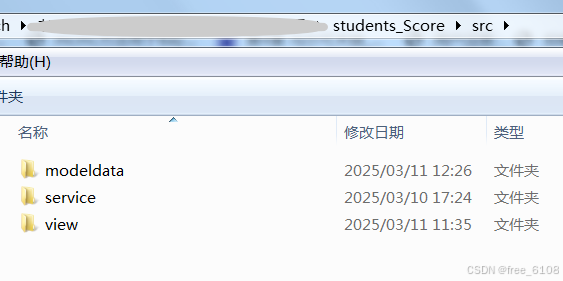
数据访问层model
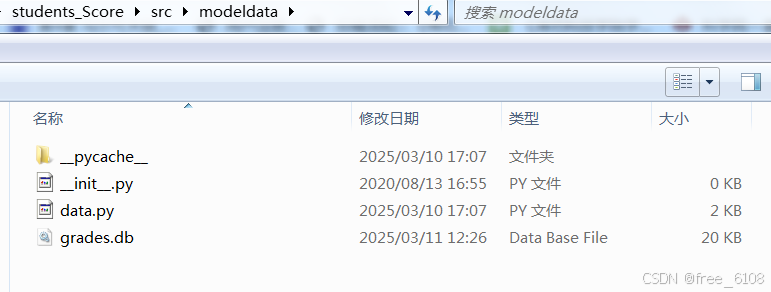
服务控制层service
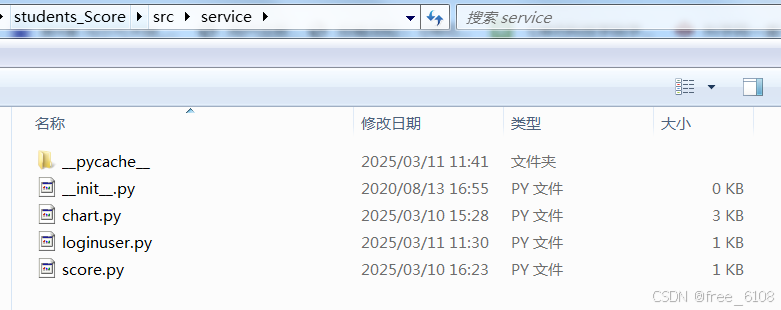
界面显示层view
3、主要功能运行界面:
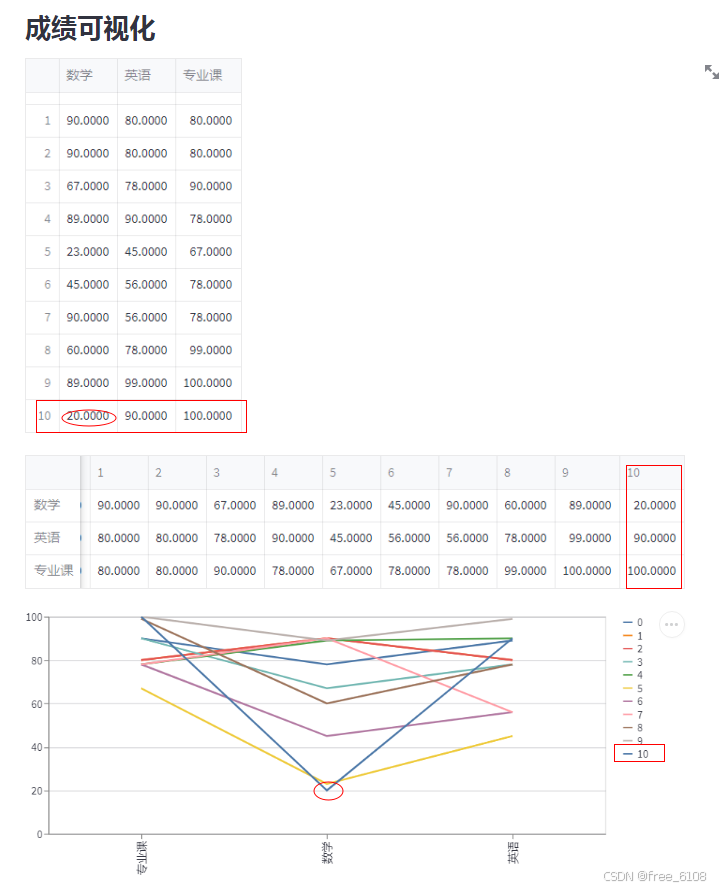
4.主要代码的部分实例:
服务控制层 service包里 的loginuser模块代码如下:

附录:未分层代码可以参考,运行体会.
import streamlit as st
import pandas as pd
import hashlib
import sqlite3
if 'user' not in st.session_state:
st.session_state.user = None
# Hashing password
def hash_password(password):
return hashlib.sha256(password.encode()).hexdigest()
# Database connection
conn = sqlite3.connect('grades.db', check_same_thread=False)
c = conn.cursor()
# Create tables if they don't exist
def init_db():
c.execute('''
CREATE TABLE IF NOT EXISTS users (
username TEXT PRIMARY KEY,
password_hash TEXT
)
''')
c.execute('''
CREATE TABLE IF NOT EXISTS grades (
id INTEGER PRIMARY KEY AUTOINCREMENT,
math REAL,
english REAL,
major REAL
)
''')
conn.commit()
init_db()
# Login function
def login():
st.subheader("登录")
username = st.text_input("用户名")
password = st.text_input("密码", type="password")
if st.button("登录"):
hashed_password = hash_password(password)
c.execute("SELECT * FROM users WHERE username=? AND password_hash=?", (username, hashed_password))
user = c.fetchone()
if user:
st.success(f"成功登录为 {username}")
st.session_state.user = username
else:
st.error("无效的用户名或密码")
# Register function
def register():
st.subheader("注册")
new_username = st.text_input("新用户名")
new_password = st.text_input("新密码", type="password")
confirm_password = st.text_input("确认密码", type="password")
if st.button("注册"):
if new_password == confirm_password:
hashed_password = hash_password(new_password)
try:
c.execute("INSERT INTO users (username, password_hash) VALUES (?, ?)", (new_username, hashed_password))
conn.commit()
st.success("用户注册成功!")
except sqlite3.IntegrityError:
st.error("用户名已存在")
else:
st.error("密码不匹配")
# Grades input function
def input_grades():
st.subheader("输入成绩")
math = st.number_input("数学成绩", min_value=0, max_value=100, step=1)
english = st.number_input("英语成绩", min_value=0, max_value=100, step=1)
major = st.number_input("专业课成绩", min_value=0, max_value=100, step=1)
if st.button("提交"):
c.execute("INSERT INTO grades (math, english, major) VALUES (?, ?, ?)", (math, english, major))
conn.commit()
st.success("成绩提交成功!")
# Grades visualization function
def visualize_grades():
st.subheader("成绩可视化")
c.execute("SELECT * FROM grades")
grades_data = c.fetchall()
if grades_data:
df = pd.DataFrame(grades_data, columns=["ID", "Math", "English", "Major"])
st.dataframe(df)
st.bar_chart(df.set_index("ID"))
else:
st.warning("没有可用的成绩数据")
# Main application logic
def main():
st.title("学生成绩管理系统")
menu = ["登录", "注册", "输入成绩", "成绩可视化"]
choice = st.sidebar.selectbox("菜单", menu)
if choice == "登录":
login()
elif choice == "注册":
register()
elif choice == "输入成绩":
if st.session_state.user:
input_grades()
else:
st.warning("请先登录以访问此功能")
elif choice == "成绩可视化":
if st.session_state.user:
visualize_grades()
else:
st.warning("请先登录以访问此功能")
if __name__ == "__main__":
main()
总结:分层架构系统 代码 相较未分层 模块化设计,复杂度增加、代码量、存储消耗稍有增加,需要仔细规划依赖和依赖传递。付出这些一次性、不大的代价,换来了功能模块的合理粒度的规划和高内聚低耦合,提高了系统的灵活性和日后的可维护性,同时实现了开发任务的可控性 边界清晰的划分、分配与高效管理等,是应对规模较大软件开发时, 可选的常用架构设计方案之一。
非常感谢你每一次的停留和阅读!这承载了满满厚爱与支持!愿你在编程的道路上日新月异,收获满满的成就和喜悦!

















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









