







目录
概念:
从数据的来源(如传感器、应用端口、文件、数据库等)汇总到目的地的过程,包含收集、网络传送、处理和存储数据的过程,以便进行后续的数据分析、数据挖掘等其他使用。
数据采集涉及数据的 源端获取、 数字化、信号调理器、数据信号传输、数据存储,数据采集是所有类型的研究、分析和决策的重要关键阶段,是 数据价值 最大化所需的最基础工作,是AI赋能社会的基石。
数据采集的具体意义
- 支持决策:通过数据采集,企业可以更好地了解市场需求,优化产品和服务,提高竞争力。
- 提升服务质量:在医疗领域,数据采集有助于疾病的预防和治疗,提升医疗服务水平;在政府管理中,数据采集帮助制定更科学的政策,提升公共服务质量。
- 优化运营:在商业领域,数据采集用于市场调研、客户分析、产品开发等方面,帮助企业做出更明智的决策
- 优化生产:企业可以更加精确地了解生产过程中的物料消耗、能源消耗、过程质量、过程安全等情况,从而实现智能化的高效生产。
一、数据来源分类
1.从数据产生的物质种类:
数据的产生主要来源于以下几种物质种类:
- 传感器和物联网设备:随着物联网的快速发展,越来越多的传感器被应用于各个领域,包括工业、农业、交通、医疗等。这些传感器可以感知和记录各种物理量,如温度、湿度、压力、光照、摄像头等。传感器产生的数据量庞大,且具有实时性,为大数据的产生提供了重要的来源。机器设备运转生成的过程数据:巨量机器在运行过程中也会产生大量数据。这些数据通常来自于各种设备和系统的运行状态、性能参数等,对于工业生产和自动化控制具有重要意义。
- 社交媒体和互联网:随着互联网的普及和社交媒体的兴起,用户在互联网上产生了大量的数据。社交媒体平台如Facebook、Twitter、Instagram等每天都有数以亿计的用户在上面发布文字、图片、视频等内容。这些用户生成的数据包含了丰富的信息,如用户兴趣、社交关系、消费行为等。同时,互联网上还有大量的网页、博客、论坛等网站,用户在浏览和搜索过程中产生的点击、评论、收藏等行为也会产生大量的数据。
- 企业和政府数据的业务或服务:企业和政府机构在日常运营和管理过程中产生了大量的数据。企业在销售、生产、采购、财务等方面产生的数据,如销售额、库存量、价格变化、交易记录、评价、售后等,可以用于企业的业务分析和决策支持。政府部门在政策、法规、通知、人口统计、经济发展、环境监测、网上办事等方面产生的数据,如人口普查数据、GDP数据、环境污染数据、网上办事等结果或过程数据,可以用于社会管理和政策制定。
总之,可简单分为以下两大类。
硬件传感器:偏硬件,需要物联网的知识。
软件:应用程序端口的数据流输出、文件、数据库。
2.从数据的可支配使用权:
从不同的角度有不同的划分详细如下:
1) 从数据流通运转的区域划分:
- 私域数据:这是企业、事业等单位拥有的一方数据,包括用户基本信息、行为数据、CRM数据等。私域数据是宝贵的资产,可用于精细化运营和个性化营销。
- 公域数据:这是企业、事业等单位不具有所有权的外部数据,如社交媒体数据、开放数据等。这些数据提供更广泛的信息来源,帮助企业了解市场趋势、竞争对手和消费者偏好。
2)从 数据支配权的拥有方划分:
- 第一方数据:企业、事业等单位自有数据,包括私域数据和其他自有数据。这些数据具有高度可信度和独特性,可为所有者提供深入了解用户和业务的数据基础。
- 第二方数据:与企业或自媒体资源方等建立合作关系可获得的对方数据。
- 第三方数据:来自数据市场、运营商或其他垂直领域的数据提供方。可购买这些第三方数据来增强自身数据的广度和深度,扩大受众群体,优化营销策略和决策过程。
3) 从数据采集技术需要的支撑来看,数据主要分为两类:
- 自主使用数据:
应用程序开发里 规划并编程实现收集 最源端 采集的数据项,存储成文件、数据库表或直接发送给特定网络端口向上游传输,采集手段主要通过 flume或kafka、dataX、kettle、sqoop等工具实现源和目的端数据的高效采集汇总。
- 第三方数据:
开源、公开的,如果是web公开的数据可以爬虫爬取。然而,通过解密方式获取非公开数据是违法的;如果爬虫对目标网站造成干扰或破坏,如导致服务器宕机等是违法的;爬取任何涉及个人隐私的数据,并用于非法途径的,无论数据是否公开,如姓名、身份证件号码、通信通讯联系方式、住址等;爬取数据用于个人研究或公司内部使用一般是合法的,但如果用于商业牟利且造成严重侵权,可能会面临法律责任。 在进行大规模数据采集时,应遵守网站的Robots协议,并咨询相关法律人士。
非开源非公开的数据购买付费后,可获取使用资格,可通过API获取数据。
二、不同来源对应的数据采集
1.硬件传感器,物联网数据采集 基于用户使用角度的简要架构图
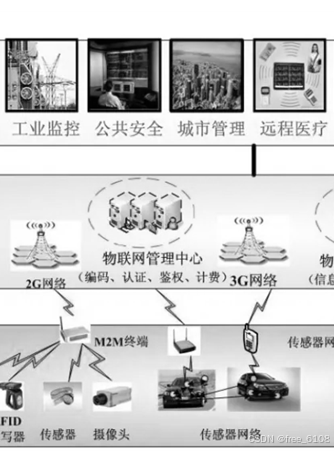
需要购买采集硬件设备、嵌入式等下位机开发和上位机的采集软件开发。
2.自主使用 软件形式 的数据采集:
软性来源 数据具体的数据采集工具和技术:Flume、Kafka、dataX、kettle、sqoop,主要架构概述:
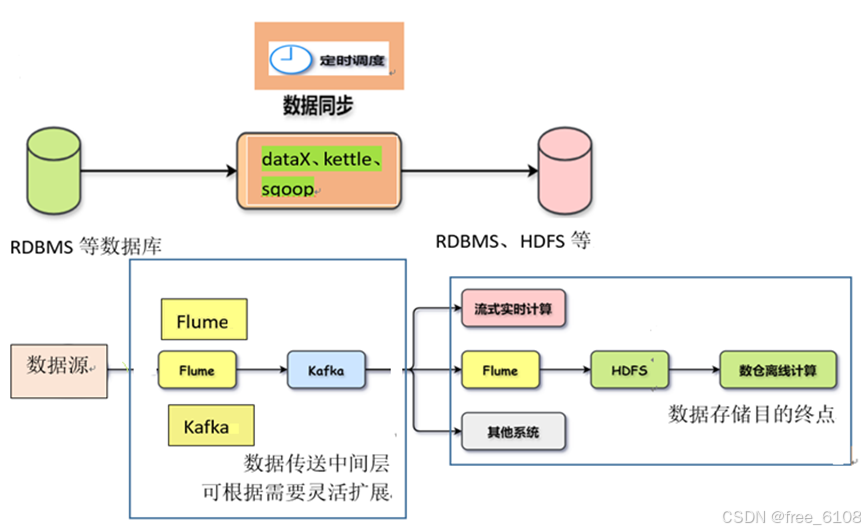
其中:
数据源可以是文件、应用的URI端口、数据库、HDFS等丰富的软性资源类型。
数据采集可以离线、定时、实时,数据内容可以分类也可以不分类。
采集可以以配置文件方式实现,也可以以API方式开发实现。
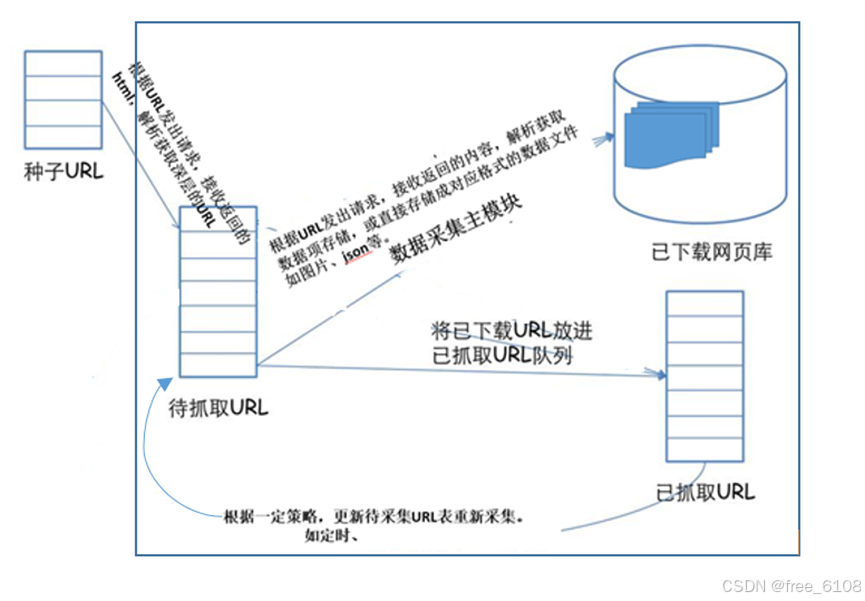
3、开源 软件形式的 web数据采集:
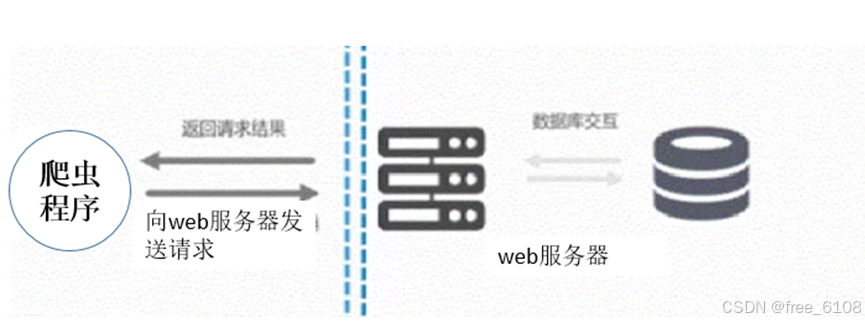
爬虫的定义:爬虫实质是 程序模拟浏览器发送 携带URL等参数 的请求->接收服务器响应->提取有用的数据->存放于数据库或文件中的程序。
注意:
- 爬取行为必须是为了合法的目的,如科学研究、数据分析、市场调研等,而不能用于非法目的,如商业欺诈、侵犯他人隐私等。
- 尊重Robots协议:在爬取前,检查阅读 网站的 Robots.txt文件,确保不违反网站规定。Robots协议是网站所有者用来指导爬虫行为的一种标准,遵循这一协议是爬虫开发的基本要求。
三、采集数据的 存储形式和存储介质选择
1、从存储的管理与容量:
例如:如下windows、linuxu、Oralcle默认、sqlserver2000文件的存储容量如下:
总结:从存储形式看,如何选择主要由提供的 数据存储容量、数据管理GUI服务、数据使用API 的丰富性决定。
2、从存储介质和使用时间开销:
在分级存储系统中,数据根据访问频率和访问响应速度被划分为不同层级。
-
热数据(Hot Data):这些数据高频被访问,通常会存储在性能最优的介质上(如SSD、高性能硬盘或内存)。
-
温数据(Warm Data):这些数据不常被访问,但偶尔需要使用,通常存储在性能适中的硬盘或云存储中。
-
冷数据(Cold Data):这些数据很少访问,甚至可能几年才会用一次,通常存储在低成本的存储介质(如磁带、光盘)中。

总结:数据访问频率和访问响应速度是 数据存储 架构设计和方案选择的决策依据。

















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









