






一、精读代码
积极利用市面上的各种AI大模型(chatgpt、Kimi、星火讯飞、文心一言、通义千问等)分析代码框架,将代码分块拆分开来进行阅读,最后达到对整个代码的结构和功能的熟悉。只要你掌握到一些提问技巧,它们有时比你直接在浏览器上反复键入好几次问题来得快和精准。
二、数据准备
场景描述由自己给出,通过询问AI如(你是一个文生图专家,我们现在要做一个实战项目,就是要编排一个文生图话剧 话剧由8张场景图片生成,你需要输出每张图片的生图提示词)得出大致的提示词,最后再根据生成的效果进行微调。
最后的场景表格如下:
| 图片编号 | 场景描述 | 正向提示词 | 反向提示词 |
| 图片1 | 一个小男孩抱着一个篮球,露出憧憬的神情 | 日漫,一个黑色头发的小男孩,双手紧紧抱着篮球,憧憬的目光望向远方,全身,站在夕阳下的篮球场 | 丑陋,变形,嘈杂,模糊,低对比度 |
| 图片2 | 他看着电视上科比在NBA的赛场上疯狂表演,一颗篮球梦在他心中渐渐发芽 | 日漫,一个黑色头发的小男孩,上半身,坐在客厅的沙发上,专注地盯着电视屏幕,电视里播放着科比在NBA赛场上的精彩瞬间 | 丑陋,变形,嘈杂,模糊,低对比度 |
| 图片3 | 于是他日复一日的在篮球场练习基本功 | 日漫,一个黑色头发的小男孩,身穿24号球衣,全身,正在篮球场上反复练习运球和投篮,背景是黄昏的篮球场 | 丑陋,变形,嘈杂,模糊,低对比度 |
| 图片4 | 在长大的过程中,他一直接收着偶像科比的激励 | 日漫,一个黑色头发的少年,上半身,身穿24号球衣,手持篮球,站在房间内,墙上贴满了科比的照片和海报 | 丑陋,变形,嘈杂,模糊,低对比度 |
| 图片5 | 无数个夜晚,他对着天空中的星星许愿 | 日漫,一个黑色头发的少年,上半身,抬头仰望着星空,手合十许愿,背景是夜空中闪烁的星星 | 丑陋,变形,嘈杂,模糊,低对比度 |
| 图片6 | 他在比赛最后时刻惨遭绝杀,失去了想要的冠军 | 日漫,一个黑色头发的少年,身穿24号球衣,全身,正在进行激烈的篮球比赛,背景是充满观众的篮球场 | 丑陋,变形,嘈杂,模糊,低对比度 |
| 图片7 | 但是他没有放弃,在接下来的训练和比赛中更加努力认真,突破极限 | 日漫,一个黑色头发的年轻人,身穿24号球衣,全身,在比赛中上篮得分 | 丑陋,变形,嘈杂,模糊,低对比度 |
| 图片8 | 他没有放弃,继续追逐梦想,终于,他登上了NBA的舞台 | 日漫,一个黑色头发的年轻人,身穿24号球衣,全身,站在NBA的球场上,正准备投篮,背景是NBA标志性的场地和热情的观众 | 丑陋,变形,嘈杂,模糊,低对比度 |
三、执行Task1的速通baseline
有了提示词就可以按照之前的方法跑baseline,最后经过对提示词及一些模型参数如 Classifier-Free Guidance Scale(cfg_scale)较高的 cfg_scale值使图像更接近正向提示,较少变化。较低的 cfg_scale值图使像更具创造性,可能与正向提示有所偏差。 num_inference_steps,字如其名,它是一个用于控制文本到图像生成过程中的迭代次数的参数,在像Stable Diffusion这样的扩散模型中。这个参数直接影响了生成图像的质量和细节水平。举例来说,较少的steps可能生成更快的结果,但是细节和质量可能会不如较多的steps,而较多的steps可能生成更细节和高质量的图像,但是会消耗更多的时间。在训练模型中的参数有lora_rank(指定 LoRA 的秩,控制额外可训练矩阵的大小),lora_alpha(指定 LoRA 的缩放因子),max_epochs(指定最大训练轮次),use_gradient_checkpointing(启用梯度检查点,以节省内存)等重要参数可根据实际需要调整。
四、结果展示
| 一个小男孩抱着一个篮球,露出憧憬的神情 | 他看着电视上科比在NBA的赛场上疯狂表演,一颗篮球梦在他心中渐渐发芽 | 于是他日复一日的在篮球场练习基本功 | 在长大的过程中,他一直接收着偶像的激励 |
|---|---|---|---|
 |  |  |  |
| 无数个夜晚,他对着天空中的星星许愿 | 他在比赛最后时刻惨遭绝杀,失去了想要的冠军 | 但是他没有放弃,在接下来的训练和比赛中更加努力认真,突破极限 | 继续追逐梦想的他终于登上了NBA的舞台 |
|---|---|---|---|
 |  |  |  |
五、浅尝scepter webui
魔搭体验网址:https://www.modelscope.cn/studios/iic/scepter_studio
Scepter支持使用创建的数据集进行微调来获取定制化模型。
你可以选择自己想要的模型:
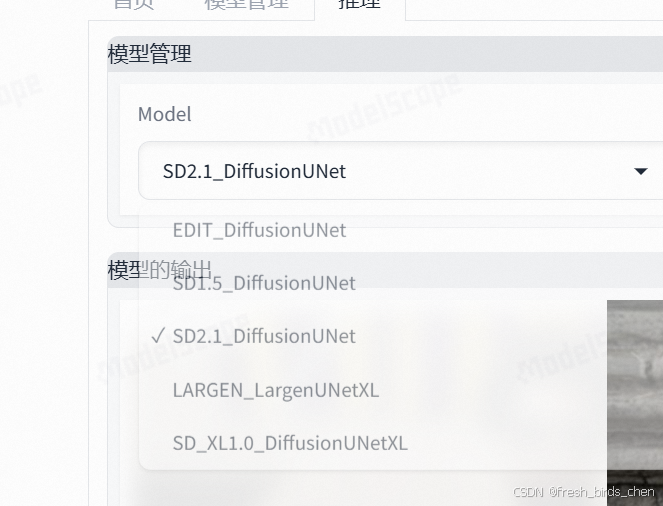
进行生成选项的控制如:模型微调、LAR-Gen(多模态融合编辑算法)-能够对生成图像的局部区域进行替换,支持文本控制其变体等操作。还有StyleBooth(风格编辑模型)-完成例如前段时间爆火的粘土特效的功能

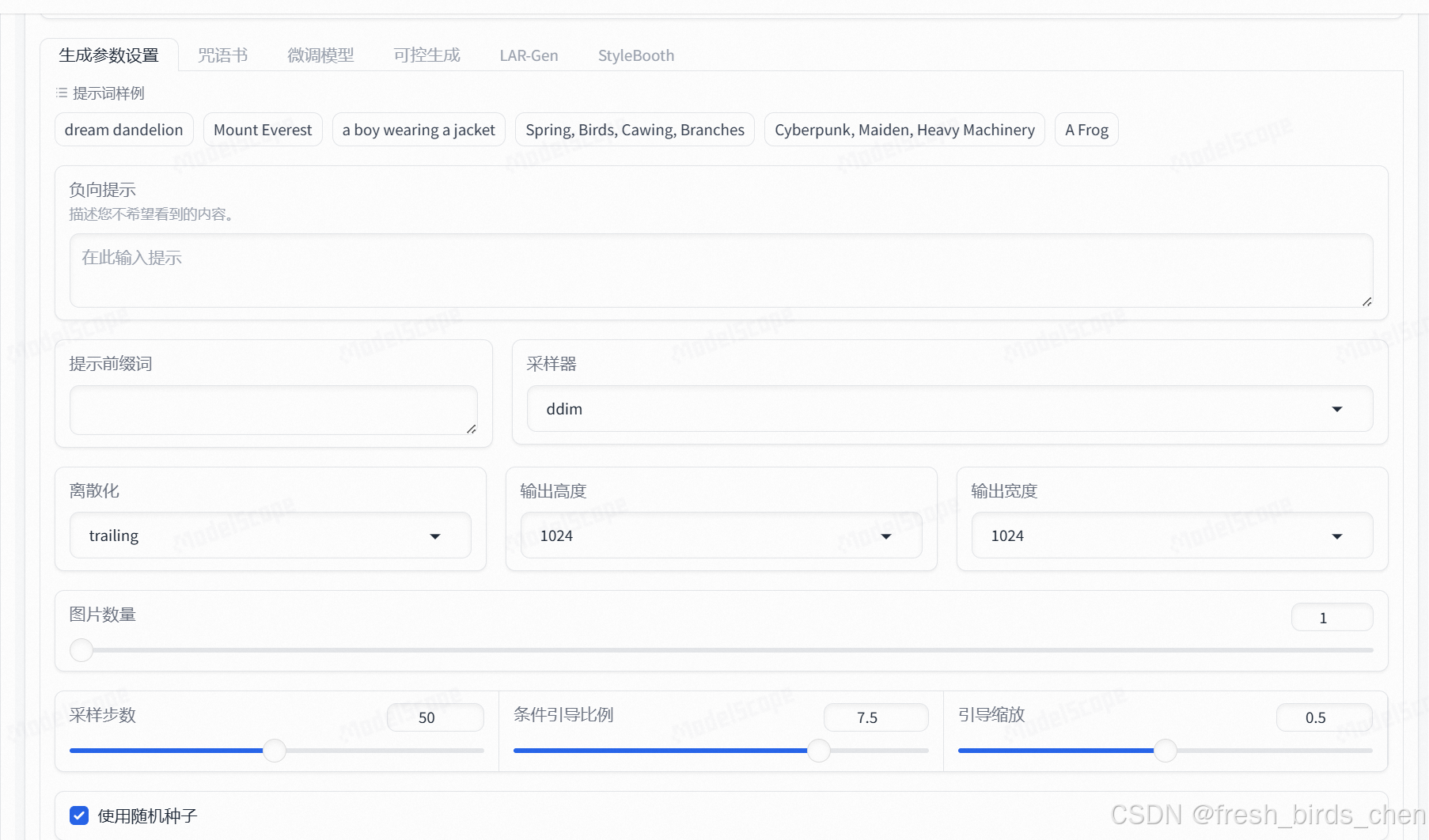
你也可以通过调整生成参数来生成自己想要的风格的图片。

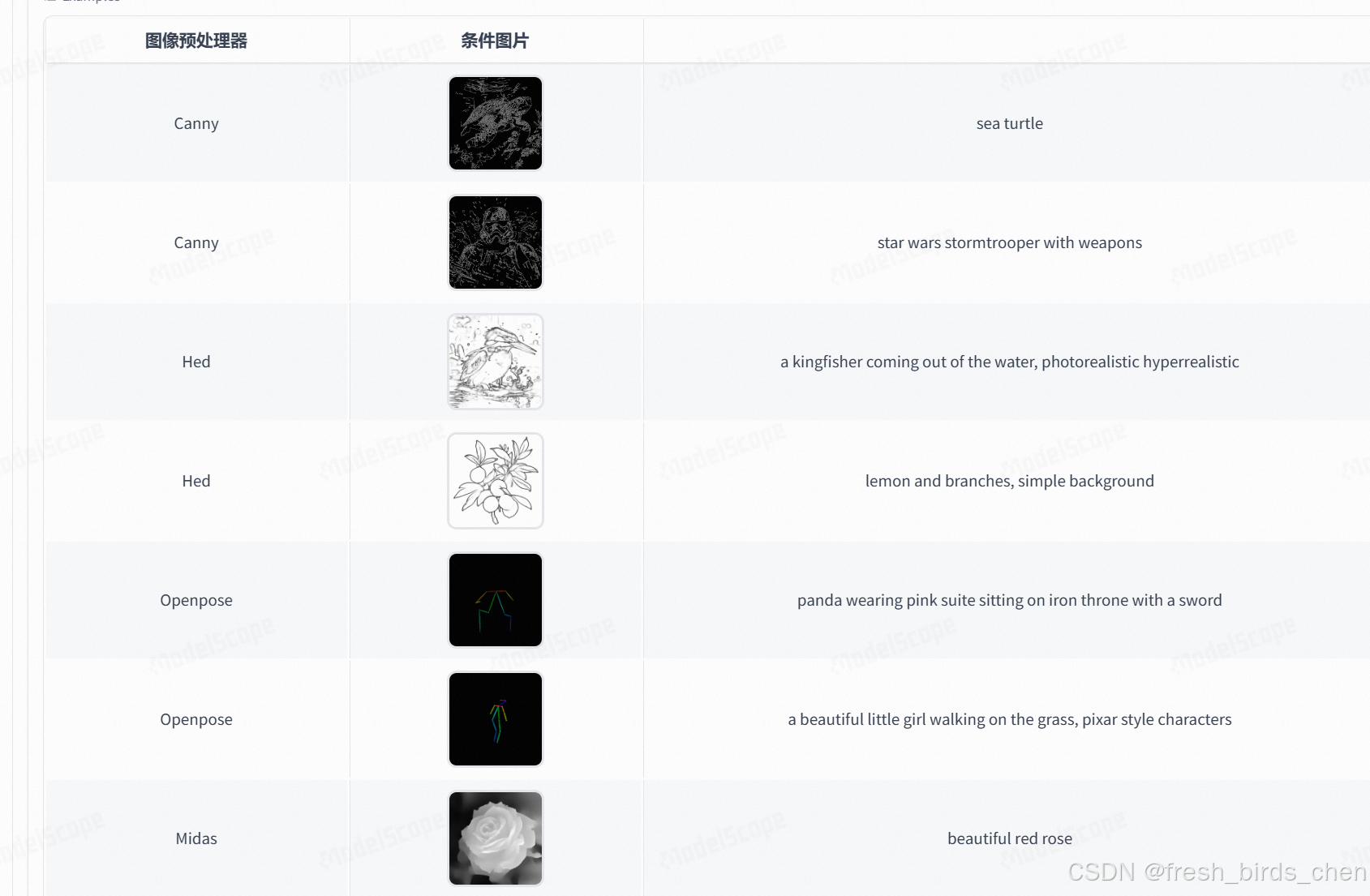
使用图像预处理器:


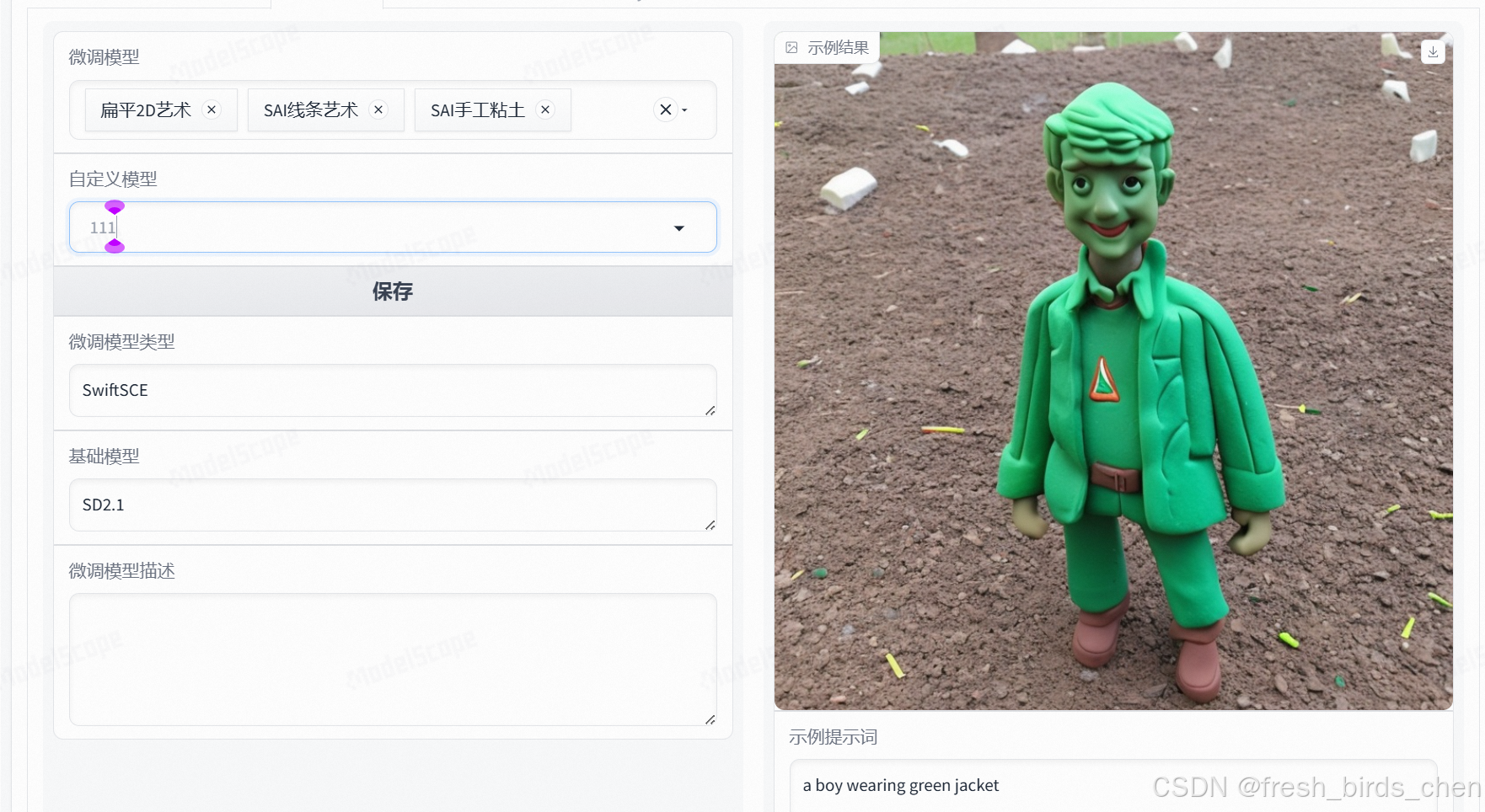
最后将自定义的模型保存

















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









