






论文、代码和数据集地址:DensePose
摘要
本文的主要贡献:Dense human pose estimation: establish dense correspondences between an RGB image and a surface-based representation of the human body(image-to-surface mapping)
1 Introduction
本文采用监督学习
贡献1:DensePose-COCO数据集,manually-collected ground-truth dataset,between SMPL model and people in COCO dataset
贡献2:在fully-convolutional network(Deeplab)和region-based system(Mask-RCNN)上应用了上述dataset,发现后者更优。结合两者特点提出了DensePose-RCNN
贡献3:由于人工标注的点的数量是有限的(每个人体100-150个点,随机采样),本文训练了一个“teacher network”,可以在image中未被标注的位置“impaint”监督信号,增强训练效果
2 COCO-DensePose dataset
将人体分为24个部分,每个部分都有对应的UV field。其中头、手和脚的UV field与SMPL model里提供的相同,其余的部分通过对成对测地距离进行多维缩放得到二维展开。

还有一些具体做标注的方法,和标注准确性的evaluation,此处略
3 Learning Dense Human Pose Estimation
3.1 Fully Convolutional Dense Pose Regression
此网络和DenseReg类似
Step 1:将input image中的每个pixel分类到background或body part中,并估计一个粗略的坐标。此部分相当于分类任务,训练时采用标准交叉熵损失函数(standard cross-entropy loss)
Step 2:通过regression system获得每个pixel在body part内部的精确坐标。
3.2 Region-based Dense Pose Regression
上述FCN系统训练起来比较容易,但是在同一个神经网络中实现part segmentation和pixel localization两个任务同时保持结果不变形是一个challenge,于是本文提出了region-based regression system。
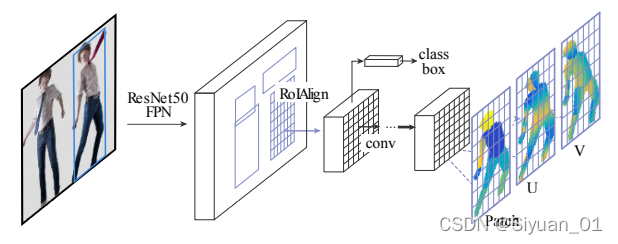
上图为DensePose-RCNN的结构。本文在RoIAlign之前加了一个FCN(即3.1中介绍的那个),用来提供分类信息,即pixel属于哪个部位。其余部分和Mask-RCNN完全一致。
Inference速度:25fps on 320x240 images and 4-5fps on 800x1100 images using a GTX1080 graphics card


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









