







 本文详细介绍了如何在Python中使用os模块进行目录表示、管理(如新建、切换和遍历)、路径处理(相对路径与绝对路径),以及文件操作(如文件名处理、路径检查和移动)。涵盖了os.walk()函数的应用实例,适合深入理解Python文件操作技巧。
本文详细介绍了如何在Python中使用os模块进行目录表示、管理(如新建、切换和遍历)、路径处理(相对路径与绝对路径),以及文件操作(如文件名处理、路径检查和移动)。涵盖了os.walk()函数的应用实例,适合深入理解Python文件操作技巧。
在用python管理文件时,我们经常进行一些文件和目录操作,下面盘点使用python中目录的基本操作方法。
目录
1. 目录的表示
文件有两个关键的属性:路径(所属目录)和文件名。
而在不同的平台下,路径的表示方法是不同的。以最常见的windows和linux平台为例。linux下路径分割符为正斜杠'/',而windows平台下路径分割符为反斜杠'\'。
os.path.join() 会自动根据平台分割符,根据输入的字符串来拼接出路径。
import os
os.path.join('home', 'vincent', 'dir_1')linux平台输出结果:

windows平台输出结果:

注意路径中反斜杠是2个,因为每个斜杠需要另一个斜杠来进行转义。 windows下的路径还可以写成 r'home\vincent\dir_1' 的形式,在字符串前面附件一个字母r,代表原始字符串,路径中的反斜杠则不再需要转义。
2. 目录管理
目录的管理涉及到新建,切换,删除等操作,我们主要用到os模块下的一些函数,使用时,我们要先用import os 导入os模块,部分目录操作示例如下:
使用os.getcwd()获取当前工作目录:
os.getcwd()![]()
使用os.makedirs()新建目录(该函数会自动创建路径上的所有目录):
os.makedirs(r'd:\dir1\dir2\dir3') # 递归创建目录使用os.chdir()切换目录:
os.chdir(r'd:\dir1\dir2\dir3')
os.getcwd()
使用os.listdir()查看目录下的内容:
os.listdir()![]()
os.listdir()函数会将目录下所有的内容都列出,但有时候文件很多,我们只想找出特定类型的问题件,此时可以使用glob模块中的glob函数进行模式匹配。
例如我只想找 .txt后缀的文件:
import glob
glob.glob('*.txt') # 匹配已txt结尾的文件
glob.glob('1.*') # 匹配文件名为1的文件
使用os.path.exists()检查路径是否存在:
os.path.exists(r'd:\dir1\dir2\dir3') ![]()
使用os.path.isdir()检查路径是否为目录:
os.path.isdir(r'd:\dir1\dir2\dir3')使用os.path.isfile()检查是否为文件:
os.path.isfile(r'd:\dir1\dir2\dir3\1.txt')
使用os.rmdir()删除目录(必须为空目录):
os.rmdir(r'd:\dir4\dir5\dir6') # 此目录为空 
3. 相对路径和绝对路径
os.path提供了一些用于处理相对路径和绝对路径的函数。
os.path.isabs()测试某个路径是否为绝对路径('.'代表当前路径):
os.path.isabs('.')![]()
os.path.abspath() 获取某个路径的绝对路径:
os.path.abspath('.')![]() 当前路径的绝对路径为 d:\dir1\dir2\dir3
当前路径的绝对路径为 d:\dir1\dir2\dir3
有时,我们需要从一个目录跳转到另一个目录,就会用到相对路径。我们在D盘下新建另一条路径: d:dir4\dir5\dir6演示。
os.path.relpath(dest, start)返回从start到dest的相对路径:
os.makedirs(r'd:\dir4\dir5\dir6')
os.path.relpath(r'd:\dir4\dir5\dir6',r'd:\dir1\dir2\dir3')![]()
其中'..'代表上级路径,如果省略start,代表从当前目录开始
os.getcwd()
os.path.relpath(r'd:\dir4\dir5\dir6')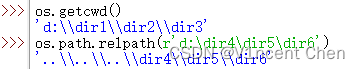
4. 遍历目录
以上的操作都是针对单一目录,当需要遍历整个目录树时,可以使用os.walk()。
os.walk()是一个生成器函数, 从根目录开始遍历,在树的每一个目录中,返回一个三元组(dir, subs, files)分别对应当前目录,当前目录所有子目录(列表),当前目录下所有文件(列表)。我们可以通过for循环来迭代访问每一级目录,每次迭代后进入下一层目录,直至结束(StopIteration)。
我们以下列三层目录结构示例:
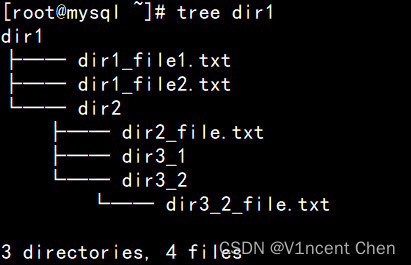
根目录为dir1,dir1中有1个目录dir2和2个文件, dir2中有2个目录(dir3_1和dir3_2)和1个文件,dir3_2下有1个文件。
我们先手动迭代观察os.walk的运行方式:
>>> import os
>>> g = os.walk('dir1')
>>> g.__next__()
('dir1', ['dir2'], ['dir1_file2.txt', 'dir1_file1.txt']) # 第1次迭代,当前目录是根目录dir1
>>> g.__next__()
('dir1/dir2', ['dir3_2', 'dir3_1'], ['dir2_file.txt']) # 第2次迭代,当前目录是 dir1/dir2
>>> g.__next__()
('dir1/dir2/dir3_2', [], ['dir3_2_file.txt']) # 第3次迭代,当前目录是 dir1/dir2/dir3_2
>>> g.__next__()
('dir1/dir2/dir3_1', [], []) # 第4次迭代,当前目录是 dir1/dir2/dir3_1
>>> g.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration # 遍历结束,抛出StopIteration异常
>>> 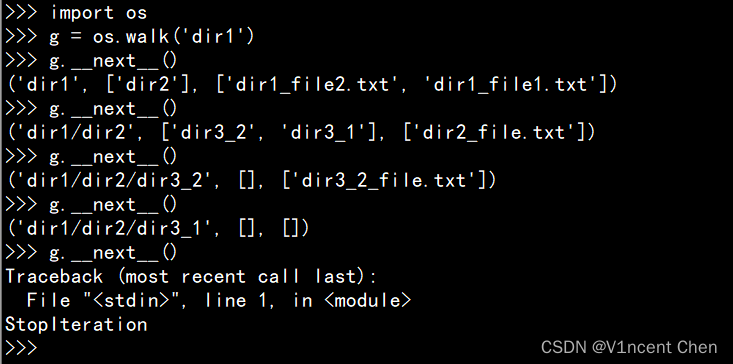
我们可以看到,os.walk()每次迭代返回的三元素元组。第一个元素为字符串(当前目录),第二个元素为列表(当前目录下所有子目录),第三个元素为列表(当前目录下所有文件)。
了解了os.walk()的工作方式,我们便可以在for循环中编写各个目录下的文件处理逻辑。
使用示例:利用os.walk遍历文件夹,将所有子目录中的文件集中到根目录中
import shutil
def gather_files(root_path):
for dir, subs, files in os.walk(root_path):
for file in files:
if dir != root_path: # 当前不是根目录时才操作
print('Moving ',os.path.join(dir,file))
shutil.move(os.path.join(dir,file), os.path.join(root_path, '~'.join(os.path.relpath(dir,root_path).split(os.path.sep))+'~'+file))其中os.path.sep代表平台下的路径分割符,我们将其替换为 '~' 并且附到移动后的文件名前,可以防止不同子目录下的同名文件冲突,并且可以通过文件名知道其来源于哪个子文件夹。

移动后的文件树如下:
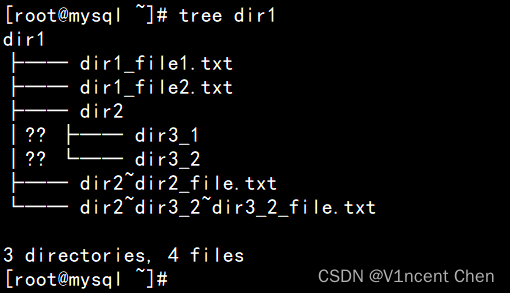
所有文件都移动到了dir1下,并在文件名前附上之前的子目录名称。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









