







公共表表达式(Common Table Expressions, CTE)是MySQL在单一语句中执行过程中,预先定义的临时结果集。
有时我们需要在一个SQL中重复执行同一个子查询,而每次子查询都会重新计算结果,带来性能的浪费。而采用CTE可以在查询的一开始就定义好子查询的结果集,MySQL只会计算一次结果,然后在查询中使用CTE的名称可以反复引用。
目录
一、CTE定义及分类
CTE的定义方式是在with子句后跟一个子查询,如果一个SQL中需要定义多个CTE,则用逗号分隔即可。
定义语法:
with_clause:
WITH [RECURSIVE]
cte_name [(col_name [, col_name] ...)] AS (subquery)
[, cte_name [(col_name [, col_name] ...)] AS (subquery)] ...CTE分为两种:
- 普通CTE:定义一个简单子查询
- 递归CTE:定义时可以引用自己,产生一个递归的结果集
普通CTE和递归CTE的区别在于,递归CTE多了一个recursive关键字,且需要引用自己。
二、普通CTE
2.1 普通CTE示例
以下的演示SQL可以在在MySQL的官方示例数据库中执行:
with
cte1 as (select emp_no,first_name,last_name from employees where emp_no=10012), -- 定义cte1
cte2 as (select emp_no,dept_no from dept_emp) -- 定义cte2
select cte1.emp_no,cte2.dept_no,cte1.first_name
from cte1
join cte2 on cte1.emp_no=cte2.emp_no;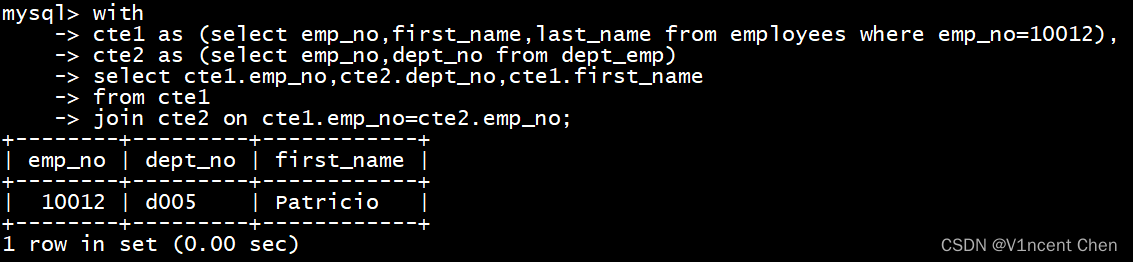
示例中在select子句前定义了cte1和cte2(以逗号分隔),随后在select子句中可以直接引用cte1和cte2的名称进行查询。
cte定义时也可以引用其他cte,例如在上面的定义中,cte2的定义可以引用cte1:
with
cte1 as (select emp_no,first_name,last_name from employees where emp_no=10012),
cte2 as (select emp_no,last_name from cte1) -- cte2的定义引用了cte1
select cte1.emp_no,cte2.last_name
from cte1
join cte2 on cte1.emp_no=cte2.emp_no;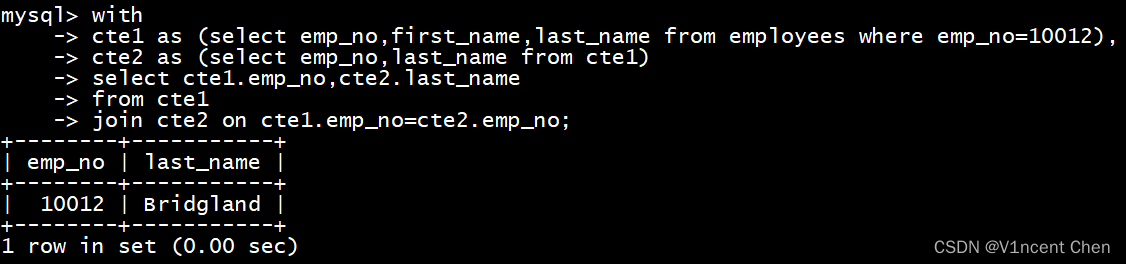
注意之只有后定义的cte可以引用前面的定义的cte,如果把cte2定义位置调到前面,则会报错:cte1不存在.

cte定义的名称后面可以添加括号,显式定义cte的列名,但要和后面子查询返还的列数量相同:
with
cte1(col1, col2, col3) as (select emp_no,first_name,last_name from employees where emp_no=10012)
select col1, col2, col3 -- 引用定义的列名
from cte1;
此时后续cte则必须通过显示定义的列名来引用(col1, col2, col3),定义中子查询的列名不能再引用了。
2.2 CTE的使用场景
cte的定义不仅仅用在select中,也可以用在update/delete语句前,子查询中,以及其他可以嵌套select语句的地方(例如 insert …select):
- WITH ... SELECT ...
- WITH ... UPDATE ...
- WITH ... DELETE …
- SELECT ... WHERE id IN (WITH ... SELECT ...) ...
- SELECT * FROM (WITH ... SELECT ...) AS dt ...
- INSERT ... WITH ... SELECT ...
- REPLACE ... WITH ... SELECT ...
- CREATE TABLE ... WITH ... SELECT ...
- CREATE VIEW ... WITH ... SELECT ...
- DECLARE CURSOR ... WITH ... SELECT ...
- EXPLAIN ... WITH ... SELECT ...
三、递归CTE
3.1 递归CTE示例
如果一个cte定义过程中引用了自己,则是递归cte,此时需要with recursive子句定义,其中recursive关键字是必须的。
递归cte包含2个部分,使用union all 或 union [distinct]连接:
with recursive
cte(n) as (
select 1
union all
select n+1 from cte where n<5)
select * from cte;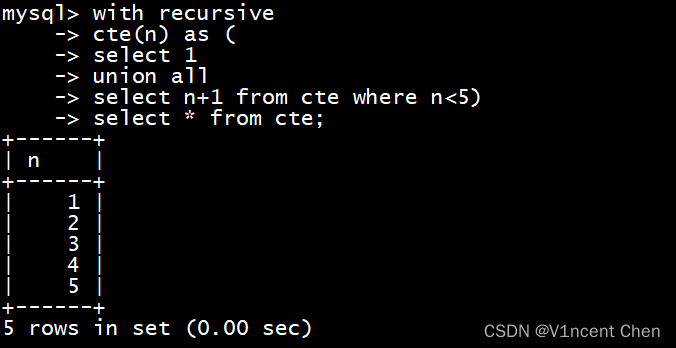
上述cte定义中第1部分生成了一条初始数据,union all后面的第二部分引用了cte自己,且递归执行,直到不再满足条件(n<5)。
1个递归cte其实包含了非递归部分和递归部分,递归的第二部分每次都以上一次产生的结果集为基础计算数据。但是大小是以非递归部分为准,如果递归产生列越来越长,可能会发生错误。
例如下面的递归拼接:
with recursive
cte as (
select 1 as n, 'abc' as str -- 非递归部分
union all
select n+1,concat(str,str) from cte where n<3) -- 递归部分
select * from cte;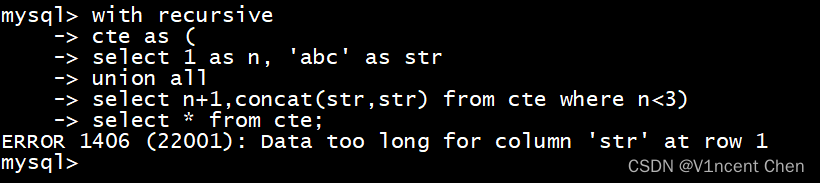
如上图所示,在strict SQL模式下,因为第二列以非递归部分的长度为准,递归后长度列的长度变长导致SQL直接报错。
而在非strict SQL模式下,以上SQL可以执行成功,但是第二列都被按非递归部分截断了,如下所示:
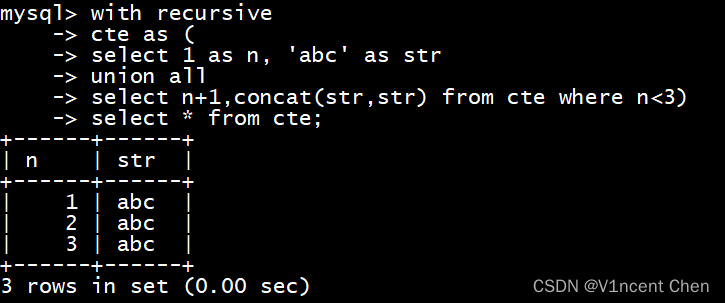
在遇到此类cte定义时,将非递归部分的列定义大一些,例如下面将'abc'的非递归部分加长,即可显示正确的递归结果:
with recursive
cte as (
select 1 as n, cast('abc' as char(20)) as str -- 定义长度
union all
select n+1,concat(str,str) from cte where n<3)
select * from cte;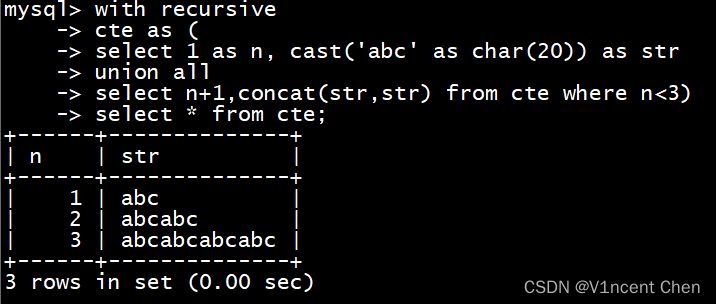
另外,对于递归cte的递归部分(即union后的SQL)还有部分使用限制:
- 递归部分不能包含聚合函数、窗口函数、group by、order by、distinct
- 递归部分引用自身只能引用一次且必须在from子句中,不能在子查询中。
3.2 限制无限递归
对于递归cte,如果没有加限制递归的条件,在逻辑上是可以无限递归的(死循环)。为了限制这种情况,MySQL有4种解决方式:
- 使用参数cte_max_recursion_depth来限制最大递归的次数,超过递归深度强制终止。
- 使用参数max_execution_time来限制最大的执行时间。
- 使用优化器提示 MAX_EXECUTION_TIME来限制最大执行时间。
- MySQL 8.0.19后,可以用limit子句限制最大返还行数。
示例:通过cte_max_recursion_depth限制递归次数,超过10次递归终止
set session cte_max_recursion_depth=10; -- 全局默认值是1000,我们这里修改会话级为10次
with recursive
cte(n) as (
select 1
union all
select n+1 from cte)
select * from cte;
示例:超过10毫秒终止递归
set session cte_max_recursion_depth=100000; -- 将递归次数增大,防止先触发
set session max_execution_time=10; -- 将最大递归执行时长修改为10毫秒
with recursive
cte(n) as (
select 1
union all
select n+1 from cte)
select * from cte;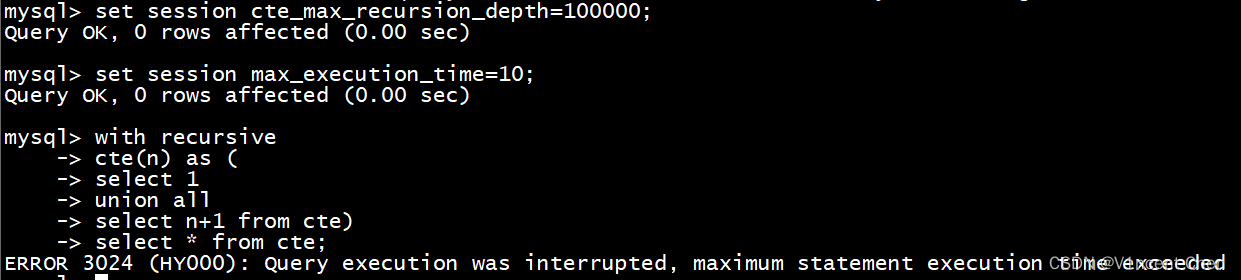
示例:使用优化器提示限制递归执行时间
with recursive
cte(n) as (
select 1
union all
select n+1 from cte)
select /*+ MAX_EXECUTION_TIME(10) */ * from cte; -- 使用提示语法限制执行时间
四、一个递归CTE应用示例
假设我们有一张订单表,
create table orders (dt date,price decimal(10,2));
insert into orders values
('2022-01-01',100),
('2022-01-01',200),
('2022-01-03',200),
('2022-01-03',200),
('2022-01-05',300),
('2022-01-07',200);现在要统计截止'2022-01-07'日的营业额,正常我们使用group by按日期汇集订单金额即可:
select dt, sum(price) sales from orders group by dt;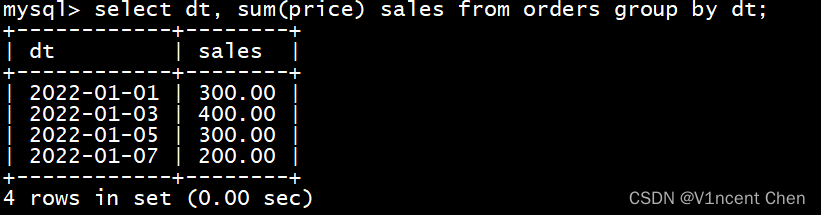
但是注意到由于2号/4号/6号没有订单,所以查询出来的结果中不包含这些日期,而通过递归cte我们可以先按日期递归,将这些日期列出来然后与orders连接:
with recursive cte(dt) as (
select min(dt) from orders
union all
select dt + interval 1 day from cte where dt <(select max(dt) from orders))
select e.dt,ifnull(sum(o.price),0) turnover
from cte e
left join orders o on o.dt=e.dt
group by e.dt
order by e.dt;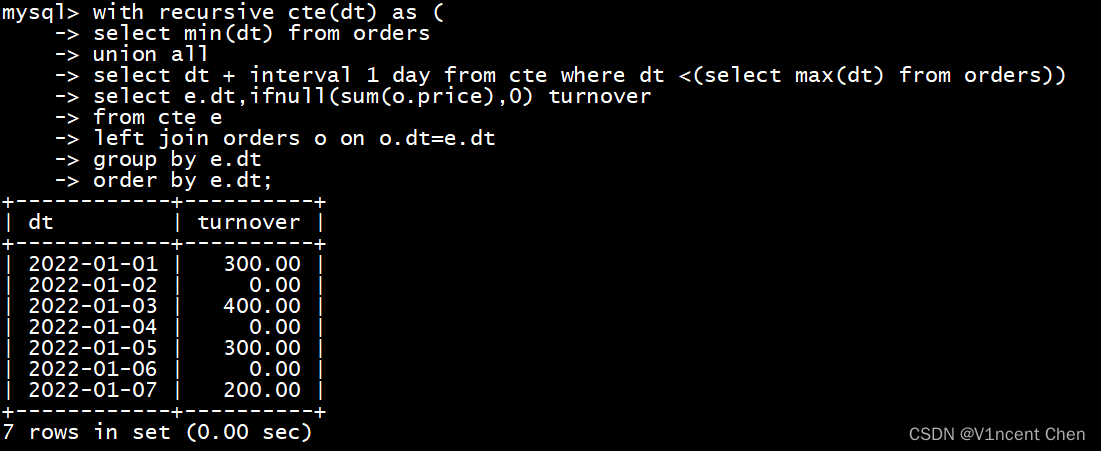
可以看到没有订单的日期也显示出来了,营业额显示为0,这个技巧在做报表类数据时很有用。

















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









