







一、关于过拟合
1、如何判断过拟合还是欠拟合?
如果验证集和测试集的准确率都较低,说明欠拟合;如果两者的准确率差异较大,说明过拟合。
过拟合的应对措施包括:
1)交叉验证,例如K折交叉验证。
2)用更多的数据参与训练,数据增强是其中的一中方法,包括翻转、平移、旋转、缩放、更改亮度等。
3)移除特征,移除特征可以降低模型的复杂度,在一定概率上减少噪声。或者在神经网络中移除部分隐藏层或者减少神经元数量,这两点可以理解为降维。
4)早停
当验证损失由低点开始上升时,应该停止训练。
5)正则化
包括但不限于L1正则化和L2正则化。
L1:
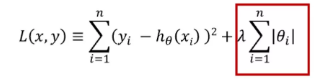
L2:
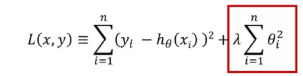
与正则化控制模型复杂度,防止过拟合思想相似的做法还有决策树中的前减枝操作,例如限制决策树的最大深度,每个叶节点的最小样本数量,每个节点允许继续划分的最小样本数量等。
6)dropout
随机地禁用部分神经元,该情况多发生在隐藏层,可以减小对其它神经元的依赖,使网络学习独立的相关性。该措施与3)类似,深度学习中经常看到dropout操作。
2、什么是偏倚(bias)、方差(variable)均衡?
偏倚指的是模型预测值与真实值的差异,是由使用机器学习算法的某些错误或过于简单的假设错误造成的错误。它会导致模型欠拟合,很难有高的预测准确率。
方差指的是不同训练数据训练的模型的预测值之间的差异,它是由于使用的算法模型过于复杂,导致对训练数据的变化十分敏感,这样会导致模型过拟合,使得模型带入过多的噪音。
任何算法的学习误差都可以分解为偏倚、方差和噪音导致的固定误差。模型越复杂,会降低偏倚增加方差。为了降低整体的误差,我们需要对偏倚方差均衡,使得模型中不会由有高偏倚或高方差。
二、关于归一化和标准化
1、为何要进行归一化或者标准化
原因有以下个:
1)某些模型求解需要
情况一是在使用梯度下降的方法求解最优化问题时, 归一化/标准化后可以加快梯度下降的求解速度,即提升模型的收敛速度。下图就是未归一化/标准化和归一化/标准化的梯度下降对比效果图。

情况二是一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
2)无量纲化
例如房子数量和收入,因为从业务层知道,这两者的重要性一样,所以把它们全部归一化。 这是从业务层面上作的处理。
3)避免异常数值问题
太大的数会引发数值问题。
2、归一化、标准化、中心化的概念与区别
归一化:把数据变成(0,1)或者(-1,1)之间的小数。作用是把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。归一化的方法有多种,例如Min-Max Normalization、平均归一化、非线性归一化等。
标准化:标准化后会使每个特征中的数值平均变为0,标准差变为1,这个方法被广泛的使用在许多机器学习算法中(例如:支持向量机、逻辑回归和类神经网络)。
中心化:平均值为0,对标准差无要求,简单地说就是变量数值减去其对应的均值。
归一化和标准化的相同:它们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
归一化和标准化的区别:两者的计算方法不同;归一化中仅最大值和最小值发挥作用,但是标准化中每个数据都对结果产生影响;适用场景不同,当数据较为稳定,不存在极端的最大最小值时,用归一化即可;但是当变量中有噪音(异常极值)时,选择标准化更合适;两者处理后的值域不同,归一化的 输出范围在 0-1 之间,标准化的输出范围是负无穷到正无穷,但是标准化处理后的数据也将大部分处于0左右。
标准化和中心化的区别:两者的计算方法不同;通常标准化要先中心化。
3、补充
如果不是必须要做归一化,建议用标准化,因为其除了具备归一化缩小数值范围的功能外,还能规避极值影响。
三、最小二乘估计与最大似然估计的区别与联系
简单地说,最小二乘的思想就是要使得观测点和估计点的距离的平方和达到最小.这里的“二乘”指的是用平方来度量观测点与估计点的远近(在古汉语中“平方”称为“二乘”)。其推导过程如下所示,其中Q表示误差,Yi表示估计值,Yi’表示观测值。

对于最大似然法,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大,也就是概率分布函数或者说是似然函数最大。显然,这是从不同原理出发的两种参数估计方法。因此,最大似然法需要已知这个概率分布函数,一般假设其满足正态分布函数的特性,在这种情况下,最大似然估计和最小二乘估计是等价的,也就是说估计结果是相同的,但是原理和出发点完全不同,其推导过程如下所示。

最小二乘法以估计值与观测值的差的平方和作为损失函数,极大似然法则是以最大化目标值的似然概率函数为目标函数。从概率统计的角度处理线性回归并在似然概率函数为高斯函数的假设下同最小二乘建立了的联系(即两者最终的计算式是相同的)。
四、决策树中的信息增益、信息增益率、基尼系数
决策树建立过程中,需要选择哪个变量对决策树分枝,而变量的选择需要借助一定的指标,ID3决策树使用的是信息增益,C4.5决策树使用的是信息增益率,而CART决策树使用的是基尼系数,下面对上述三项指标的计算方法做以总结。
1、信息增益
G(D, A)=H(D)-H(D|A)
其中,G(D, A)指的是特征 A 对数据集 D 的信息增益;H(D)指的是数据集D的熵;H(D|A)指的是A条件下,数据集D的条件熵。
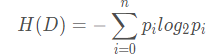
上式中,i=1,2,…n,n为某类别的数量。
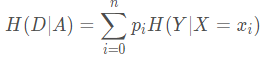
上式中,i=1,2,…n,n为特征A取值的个数。
2、信息增益率
信息增益偏向选择数值个数较多的变量,因此引入了信息增益率。
gR(D, A)=(H(D)-H(D|A))/HA(D)
其中:
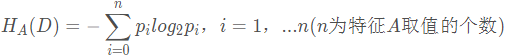
3、基尼系数
首先需要明确数据集D的纯度如何计算:
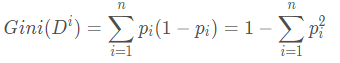
其中,n为样本的类别数。Gini系数反映了数据集中抽取两个样本,其类别不一致的概率,因此Gini系数越小越好。
由此引出特征A的基尼系数:
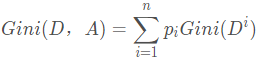
关于上述三个指标的计算案例,可以参考【文献4】。
五、决策树
决策树中的主要知识点可以参阅【文献5】。
六、机器学习效果评价指标
混淆矩阵如下所示:

精确度=TP/(TP+FP)
召回率=TP/(TP+FN)
准确率=(TP+TN)/(TP+FP+FN+TN)
ROC曲线的横坐标是假正率(FPR),纵坐标是真正率(TPR,等同于召回率)。
FPR=FP/(FP+TN)
TPR与FPR各是以真实样本中正例与反例的样本总和作为分母的。
七、正则化
L1正则化和L2正则化的公式见第一部分,由公式可知,L1与L2的区别在于后面的θ项,L1是绝对值,而L2是平方。正则化发挥作用是通过对θ约束实现的,而θ就是回归方程的各阶系数,通过θ控制拟合曲线方程的复杂程度。
L1正则化和L2的区别:
1、L1正则化可以使参数矩阵稀疏化。从图形的角度考虑,L1是一个方形,如右图所示,而L2是一个圆形,如左图所示。这个坐标系是参数的坐标系,与原数据没有关系;红色边框包含的区域是解空间,每个蓝色的圆圈可以取无数个w1和w2组合,这些w1和w2有一个共同的特点,用它们计算的目标函数值是相等的。
从右图中发现,L1的蓝色圆圈与方形的顶点相切,此时w1分量为0,这是一个稀疏解,能够在一定程度上简化模型。

2、L1的下降速度要快于L2。L1和L2作为代价函数的一部分,我们需要将其最小化,这个最小化的计算过程就与犹如下坡。如下图所示,L1按照绝对值函数下降的,而L2是按照二次函数下降的,从曲线斜率的角度考虑,L1下降速度比L2下降速度快,会更快地下降到0。

对L1和L2做以下总结:
L1范数:L1范数在正则化的过程中会趋向于产生少量的特征,而其他的特征都是0(L1会使得参数矩阵变得稀疏)。因此L1不仅可以起到正则化的作用,还可以起到特征选择的作用。
L2范数:L2范数是通过使权重衰减,进而使得特征对于总体的影响减小而起到防止过拟合的作用的。L2的优点在于求解稳定、快速。
八、KNN和K-means有哪些区别?
相同之处:这两种算法有些相似,都需要计算样本之间的距离。
不同之处:
- KNN是一种监督学习算法,而k-means是非监督的。
- 算法基本思想不同。KNN算法需要事先已有标注好的数据,当需要对未标注的数据进行分类时,统计它附近最近的k个样本,将其划分为样本数最多的类别中。k-means聚类只需要一些数据点和阈值,算法会逐渐将样本点分成族类。
九、贝叶斯
1、什么是贝叶斯定理,它是如何使用在机器学习中的?
贝叶斯定理会根据一件事发生的先验知识告诉你它后验概率。数学上,它表示为:一个条件样本发生的真正率占真正率和假正率之和的比例,即:
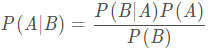
举个例子: 已知某疾病的患病概率为5%,现用某检验方法进行诊断,若患有该病,则有90%的几率检验结果呈阳性。但即使正常人使用该检验方法,也有10%的几率误诊而呈阳性。某人检验结果为阳性,求此人患病的概率。

贝叶斯定理是一些机器学习算法如:朴素贝叶斯等的理论基础。
2、为什么我们要称“朴素“贝叶斯?
因为我们在用到它的时候,有一个很强的假设,现实数据中几乎不会出现的:假设特征之间是相互独立,也就是计算条件概率时可以简化成它的组件的条件概率乘积。
九、第Ⅰ类误差和第 II 类误差有什么区别?
第Ⅰ类错误(alpha类错误):原假设是正确的,但拒绝了原假设(弃真);第 II 类错误(beta类错误):原假设是错误的,但没有拒绝原假设(存伪)。
以上弃真,存伪都是从原假设出发的。放弃原假设就可能发生”弃真”,接受原假设有可能“存伪”。

这里我们举个简单的例子说明这个问题,假设我们从某个指标一组检测结果判断某个人是否是肝病病人。原假设:健康人,备择假设:肝病病人。那么,当这组数据表明应该拒绝原假设,那么,我们可能会犯第Ⅰ类错误,将健康人误诊为肝病病人(图中黄色部分)。但是如果我们接受了原假设,认为该人为健康人,我们有可能会犯第II类错误,将肝病病人认为是健康人(图中红色部分),因为有一部分肝病病人该指标的表现和正常人类似,从数据无法判断。

与混淆矩阵相结合分析,发现第 Ⅰ 类错误其实就是混淆矩阵中的FN,而第II类错误就是FP。
十、数据
1、如何处理一个不平衡的数据集?
1) 采样
采样方法是通过对训练集进行处理使其从不平衡的数据集变成平衡的数据集,在大部分情况下会对最终的结果带来提升。采样分为上采样(Oversampling)和下采样(Undersampling),上采样是把小众类复制多份,下采样是从大众类中剔除一些样本,或者说只从大众类中选取部分样本。
上采样后的数据集中会反复出现一些样本,训练出来的模型会有一定的过拟合;而下采样的缺点显而易见,那就是最终的训练集丢失了数据,模型只学到了总体模式的一部分。
上采样会把小众样本复制多份,一个点会在高维空间中反复出现,这会导致一个问题,那就是运气好就能分对很多点,否则分错很多点。为了解决这一问题,可以在每次生成新数据点时加入轻微的随机扰动,经验表明这种做法非常有效。
因为下采样会丢失信息,如何减少信息的损失呢?第一种方法叫做EasyEnsemble,利用模型融合的方法(Ensemble):多次下采样(放回采样,这样产生的训练集才相互独立)产生多个不同的训练集,进而训练多个不同的分类器,通过组合多个分类器的结果得到最终的结果,K折交叉检验就是这样的思路。第二种方法叫做BalanceCascade,利用增量训练的思想(Boosting):先通过一次下采样产生训练集,训练一个分类器,对于那些分类正确的大众样本不放回,然后对这个更小的大众样本下采样产生训练集,训练第二个分类器,以此类推,最终组合所有分类器的结果得到最终结果。第三种方法是利用KNN试图挑选那些最具代表性的大众样本,叫做NearMiss,这类方法计算量很大,感兴趣的可以参考“Learning from Imbalanced Data”这篇综述的3.2.1节。
2)数据合成
数据合成方法是利用已有样本生成更多样本,这类方法在小数据场景下有很多成功案例,比如医学图像分析等。较为常用的方法是Borderline-SMOTE与ADASYN。
3)一分类
对于正负样本极不平衡的场景,我们可以换一个完全不同的角度来看待问题:把它看做一分类(One Class Learning)或异常检测(Novelty Detection)问题。这类方法的重点不在于捕捉类间的差别,而是为其中一类进行建模,经典的工作包括One-class SVM等。
4)如何选择
解决数据不平衡问题的方法有很多,上面只是一些最常用的方法,如何根据实际问题选择合适的方法呢?
(1)在正负样本都非常之少的情况下,应该采用数据合成的方式;
(2)在负样本足够多,正样本非常之少且比例及其悬殊的情况下,应该考虑一分类方法;
(3)对于下采样,如果计算资源相对较多且有良好的并行环境,应该选择Ensemble方法。
(未完待续)
参考文献:
【1】过拟合
https://mp.weixin.qq.com/s?__biz=MzIyNjM2MzQyNg==&mid=2247548842&idx=1&sn=899649a179c05d89095f600b1cd32275&chksm=e873eee7df0467f1d18b1d62d44076fd68c5c8a49752531fa937720aee30257aa34f8f09db30&mpshare=1&scene=1&srcid=0127C3jKiZaQt5xx5EGZp7dM&sharer_sharetime=1611738984303&sharer_shareid=b9d406c7c7238a4ce0e2f09c49498ae1&exportkey=AROyGhxv15hnNVFrMJvB7%2BA%3D&pass_ticket=V5eR%2FJV1c%2BcvPqF%2FwCFCDQEqV%2BddiEdO9qTtznEwiQZCsDld%2B1s3Moxj%2BUc51qgN&wx_header=0#rd
https://blog.csdn.net/wyisfish/article/details/79167271
【2】归一化与标准化
https://www.jianshu.com/p/95a8f035c86c
https://www.jianshu.com/p/982bd6051488
【3】最小二乘与最大似然估计
https://www.cnblogs.com/fclbky/p/6836883.html
https://blog.csdn.net/rosenor1/article/details/52268039?utm_source=blogxgwz7
【4】决策树中的信息增益、信息增益率、基尼系数
https://blog.csdn.net/t4ngw/article/details/111244340
【5】决策树知识点
https://www.cnblogs.com/liuyingjun/p/10590095.html
【6】机器学习效果评价指标
https://baijiahao.baidu.com/s?id=1619821729031070174&wfr=spider&for=pc
【7】正则化
https://blog.csdn.net/weiyongle1996/article/details/78161512
https://blog.csdn.net/u010381985/article/details/57955274
【8】第一类误差和第二类误差
https://zhidao.baidu.com/question/565962190654962404.html
【9】处理不平衡的数据集
https://blog.csdn.net/lujiandong1/article/details/52658675
https://www.leiphone.com/news/201706/dTRE5ow9qBVLkZSY.html















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









