







leetcode用堆解决topK问题
基本思路
堆排序
堆的题在python中可以用heapq库
默认是最小堆
堆排序的话
最大堆:也叫大顶堆,堆顶最大,每个结点的值都大于或等于其左右孩子结点的值
最小堆:也叫小顶堆,堆顶最小,每个结点的值都小于或等于其左右孩子结点的值
适合类型的堆来进行排序
升序----使用大顶堆
降序----使用小顶堆
(假设我们想要升序的排列)
- 第一步:先n个元素的无序序列,构建成大顶堆
- 第二步:将根节点与最后一个元素交换位置,(将最大元素"沉"到数组末端)
- 第三步:交换过后可能不再满足大顶堆的条件,所以需要将剩下的n-1个元素重新构建成大顶堆
- 第四步:重复第二步、第三步直到整个数组排序完成
找最大K个数的时候
这个时候应该要用小顶堆,为什么?因为我们要保存最大的K个数,在建立堆的时候加一个限制条件,当前元素比堆顶要大,我们才加进去,当然要先把最小的pop出来再加,这样的话我们的小顶堆可以保存最大的K个数
同理找最小的K个数亦然,建立堆的时候,判断是否比堆顶小,小的话才push进去,并且将大的pop出来
下面开始做题
1.数组中的第K个最大元素
找出数组中第K个最大的元素

可以理解成以K为上限从数据流中建立最小堆,最终最大的K个数都能找到,每次pop出去都是在最大的K个数中找最小
找数组的第K个最大元素,只需要拿在最后的K最小堆的堆顶即可
有一种比较low的做法是,直接建立一个n大小的大顶堆,然后popK次,但是空间复杂度高,并且时间复杂度是Klogn
import heapq as h
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
heap = []
for num in nums:
# 如果堆长度没到k,无脑塞
if len(heap) < k:
h.heappush(heap, num)
else:
# 如果长度到k了,且当前元素比堆顶要大,我们才加进去,当然要先把最小的pop出来再加!
if num > heap[0]:
h.heappop(heap)
h.heappush(heap, num)
return h.heappop(heap)
2.数据中的最小K个数
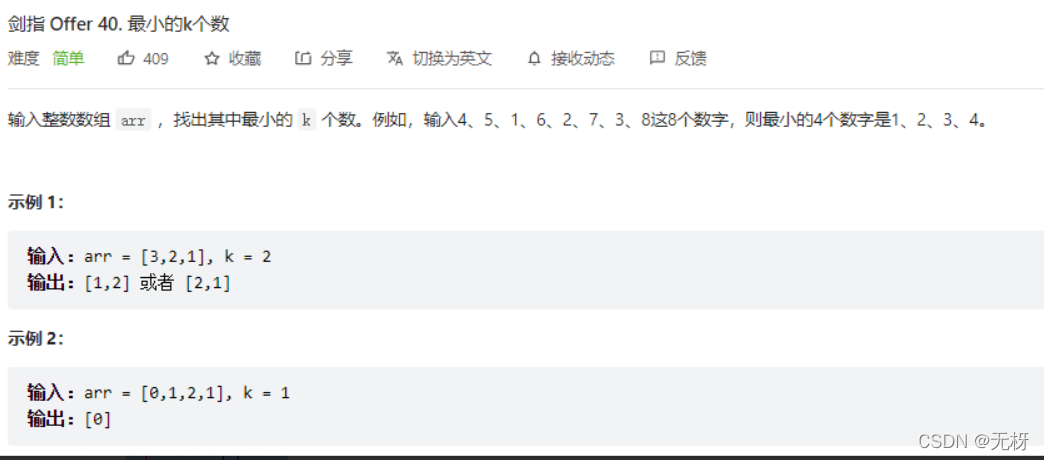
很直观,大顶堆,注意大顶堆我们依然用heapq,但是用负数存储
import heapq as h
class Solution:
def getLeastNumbers(self, arr: List[int], k: int) -> List[int]:
#大顶堆
#python实现大顶堆需要用负数
if k==0:
return []
max_heap=[]
for num in arr:
if len(max_heap)<k:
h.heappush(max_heap,-num)
else:
if num<-max_heap[0]:
h.heappop(max_heap)
h.heappush(max_heap,-num)
res=[]
for i in max_heap:
res.append(-i)
return res
3.数据流的最大K个元素
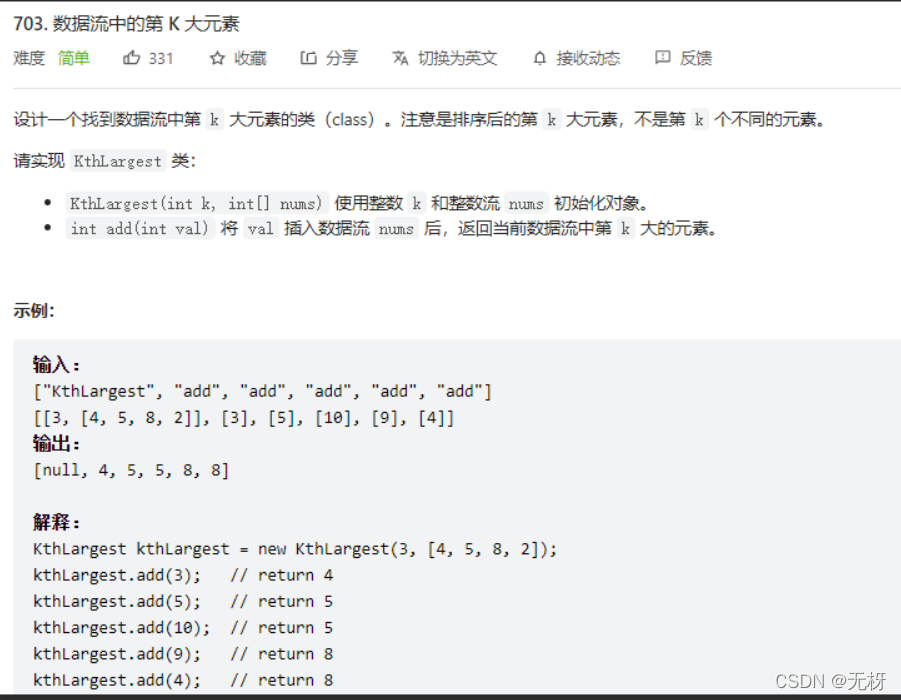
和上面一题思路一样,唯一需要注意的点就是,init的时候可以建堆,然后add里面只需要判断是继续加还是pop后再加,最后返回堆顶即可
import heapq as h
class KthLargest:
def __init__(self, k: int, nums: List[int]):
self.min_heap=[]
self.k=k
self.nums=nums
for num in self.nums:
if len(self.min_heap) < self.k:
h.heappush(self.min_heap, num)
else:
if num > self.min_heap[0]:
h.heappop(self.min_heap)
h.heappush(self.min_heap, num)
def add(self, val: int) -> int:
if len(self.min_heap) < self.k:
h.heappush(self.min_heap, val)
else:
if val > self.min_heap[0]:
h.heappop(self.min_heap)
h.heappush(self.min_heap, val)
return self.min_heap[0]
# Your KthLargest object will be instantiated and called as such:
# obj = KthLargest(k, nums)
# param_1 = obj.add(val)
4.数组中两元素的最大乘积
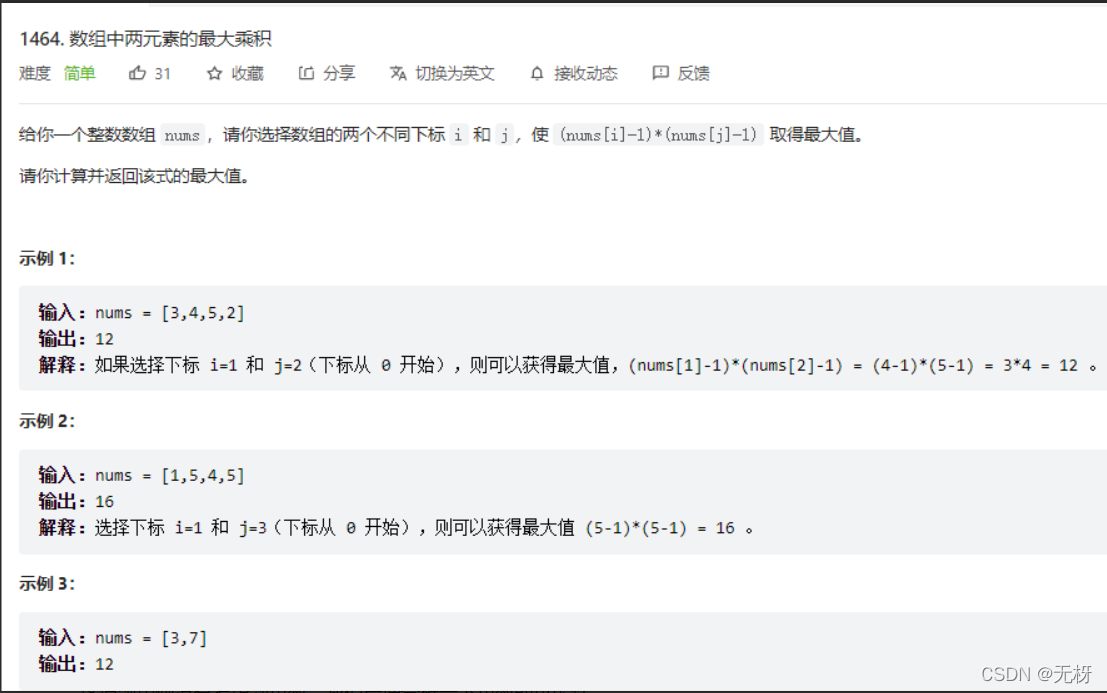
这道题用例没有考虑到负数,我们严谨分析一下负数的可能性
用最大堆和最小堆
import heapq as h
class Solution:
def maxProduct(self, nums: List[int]) -> int:
#选择一个最大值和次大值,但是要考虑两个正整数和两个负整数
#分别维护一个长度为2的最大堆和最小堆
maxheap=[]
minheap=[]
for num in nums:
if len(maxheap)<2 and len(minheap)<2:
h.heappush(maxheap,-num)
h.heappush(minheap,num)
else:
if num>minheap[0]:
h.heappop(minheap)
h.heappush(minheap,num)
if num<-maxheap[0]:
h.heappop(maxheap)
h.heappush(maxheap,-num)
#maxheap里面存的是负数,但是已经变成正数了。按原本的是-n-1和-m-1,那其实我们的已经变成正数了,为n+1和m+1的乘积
maxres=max((maxheap[0]+1)*(maxheap[1]+1),(minheap[0]-1)*(minheap[1]-1))
return maxres
5.找到最大K个子序列
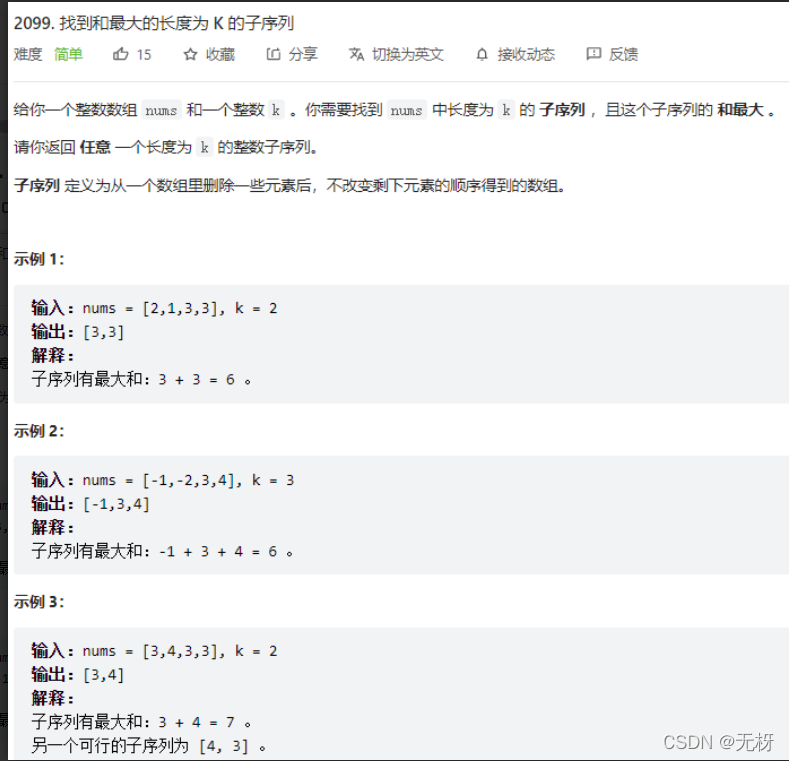
用堆来做
为了不改变原始数组顺序,用一个答案保存当前heap的数据
此处不能用index数组保存下标,因为会有重复元素出现在不同的位置
import heapq as h
class Solution:
def maxSubsequence(self, nums: List[int], k: int) -> List[int]:
#用堆来做
#为了不改变原始数组顺序,用一个答案保存当前heap的数据
minheap=[]
res=[]
for i in range(len(nums)):
if len(minheap)<k:
h.heappush(minheap,nums[i])
res.append(nums[i])
else:
if nums[i]>minheap[0]:
tmp=h.heappop(minheap)
res.remove(tmp)
#此处删除以最左边的为准
h.heappush(minheap,nums[i])
res.append(nums[i])
return res
6.最后一块石头的重量
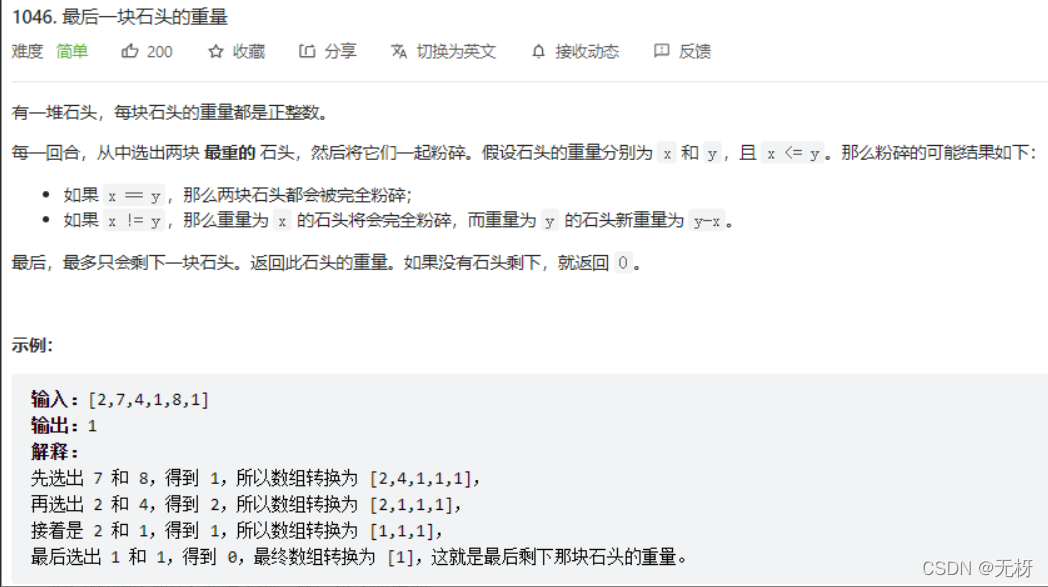
很自然的想到用大顶堆去做,然后每次取堆顶
import heapq as h
class Solution:
def lastStoneWeight(self, stones: List[int]) -> int:
res=[]
for stone in stones:
h.heappush(res,-stone)
while len(res)>1:
a=-h.heappop(res)
b=-h.heappop(res)
if a!=b:
h.heappush(res,b-a)
if len(res)==0:
return 0
else:
return -res[0]
7.最长快乐字符串
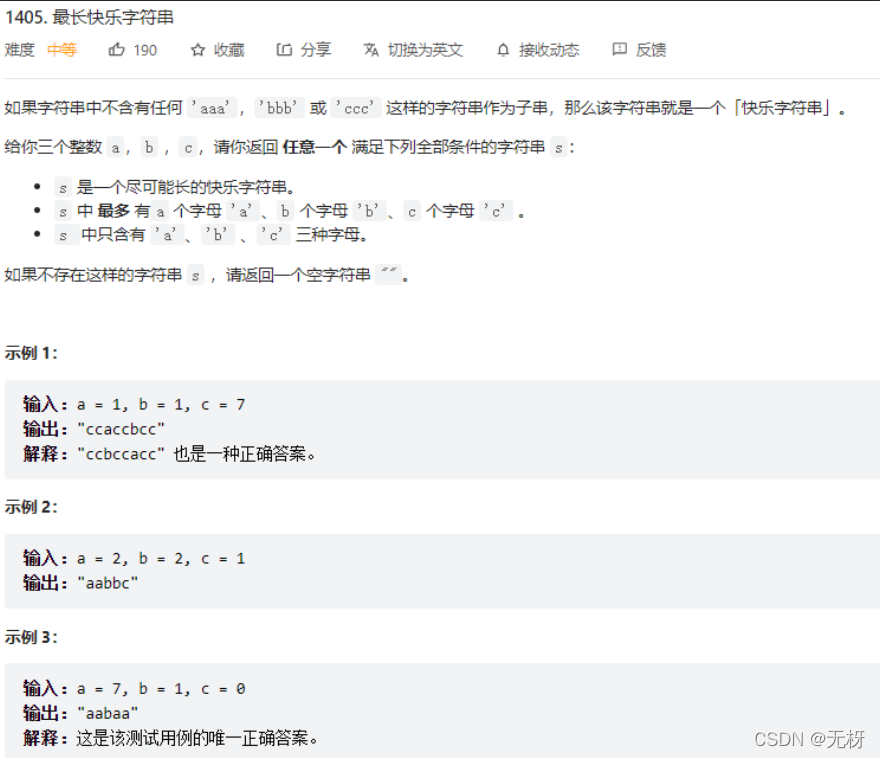
用一个heap保存当前abc的剩余次数,然后
容易想到:每次都取当前剩余次数最多的字符来进行构造(前提是满足「不出现形如 aaa 字符串」的要求)。
具体的,可以使用「优先队列(堆)」来实现上述过程,以 (字符编号, 字符剩余数量) 的二元组形式进行存储,构建以 字符剩余数量 排倒序的「大根堆」:
起始先将 (0, a)(0,a)、(1, b)(1,b) 和 (2, c)(2,c) 进行入堆(其中 123 为字符编号,代指 abc,同时规定只有剩余数量大于 0 才能入堆);
每次取出堆顶元素(剩余数量最多的字符),尝试参与答案的构造:
不违反连续三个字符相同:则说明当前字符能够追加到当前答案尾部,若追加后还有字符剩余,则更新剩余数量重新入堆;
违反连续三个字符相同:说明该字符无法追加到当前答案尾部,此时尝试从堆中取出剩余次数次大的字符(若当前堆为空,说明没有任何合法字符能够追加,直接 break),若次大字符追加后还有字符剩余,则更新剩余数量重新入堆,同时将此前取的最大字符元祖也重新入堆;
重复步骤 22,直到所有字符均被消耗,或循环提前结束。
该做法的正确性:a=b=c!=0时能够确保所有字符轮流参与构建,得到长度最大的快乐字符串,而该贪心策略(每次尽可能地进行大数消减)可以确保能够尽可能的凑成 a=b=c 的局面,并且凑成该局面过程中不会从有解变为无解。
class Solution:
def longestDiverseString(self, a: int, b: int, c: int) -> str:
def addChars(queue, strs):
val, char = heapq.heappop(queue)
if not val or (len(strs) >= 2 and strs[-2] == strs[-1] == char and (not queue or not addChars(queue, strs))):
return False
strs.append(char)
heapq.heappush(queue, (val + 1, char))
return True
pq = [(-a, 'a'), (-b, 'b'), (-c, 'c')]
heapq.heapify(pq)
ans = []
while pq and addChars(pq, ans):
pass
return "".join(ans)
8.前K个高频单词
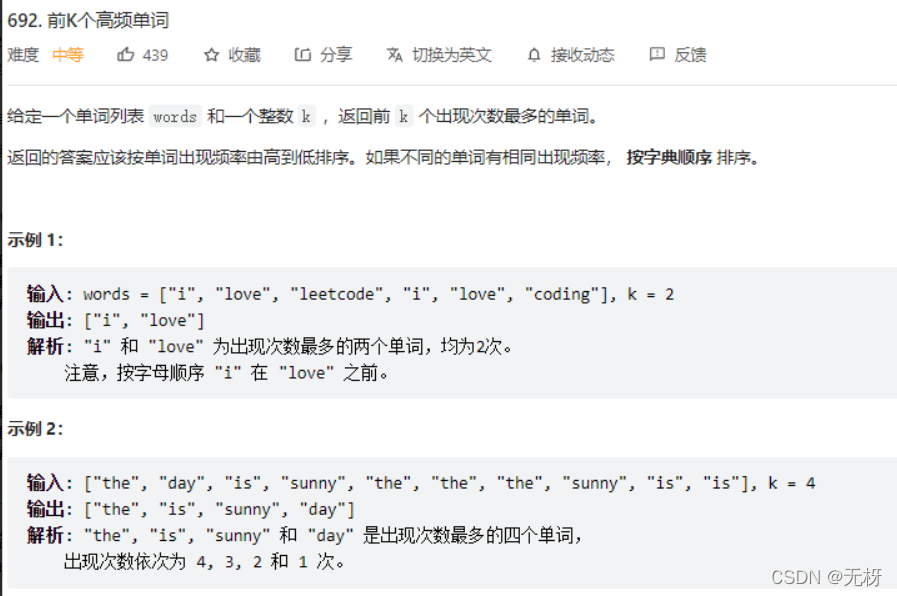
思路很简单,但是实现的时候比较难
首先用hash表得到每个单词的出现次数
然后构造长度为K的小顶堆
注意,可以构造一个word类,当出现次数不同,按照出现次数比大小
当出现次数相同,按照word的字典序排大小,此处可以重写类和对象比较逻辑
最后的K个元素的小顶堆,可以一个一个pop然后逆序,也可以直接reverse
时间复杂度nlogk
import heapq, collections
class Word:
def __init__(self, word, fre):
self.word = word
self.fre = fre
def __lt__(self, other):
if self.fre != other.fre:
return self.fre < other.fre
return self.word > other.word
class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
cnt = collections.Counter(words)
heap = []
for word, fre in cnt.items():
heapq.heappush(heap, Word(word, fre))
if len(heap) > k:
heapq.heappop(heap)
heap.sort(reverse=True)
return [x.word for x in heap]
9.数据流的中位数
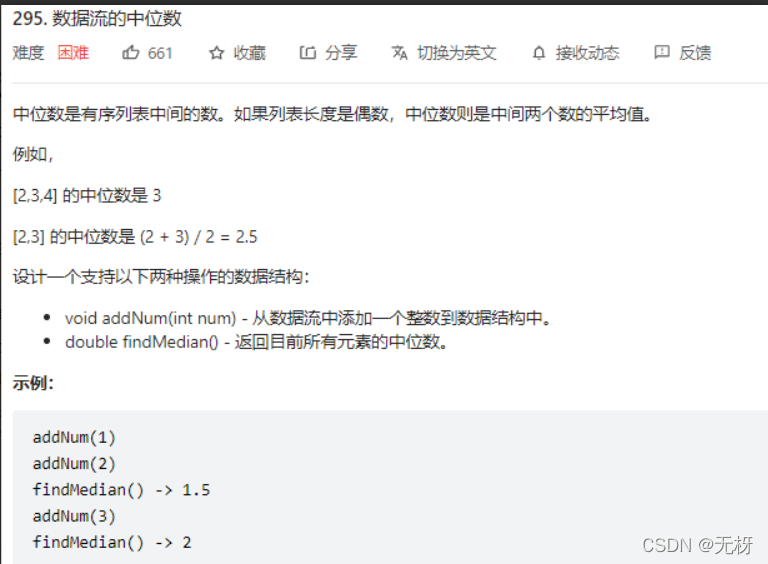
即动态返回一个数据的中位数
这道题很明显,保存在两个堆,最大的数保存在小顶堆,可以获取最大的数中离中间最近的一个,
最小的数保存在大顶堆,可以获取最小的数中离中间最近的一个,注意维护的是两个堆数据量相同,最多可以让大顶堆多一个数(因为奇数偶数)
那怎么保证新来一个数就可以维护两个堆的堆顶都是中间的两个数呢
当拿来一个数num,做出如下操作: 如果大顶堆中的元素数量等于小顶堆中的元素数量,则先将num插入到小顶堆,再将小顶堆的堆顶元素插入到大顶堆; 否则,先将num插入到大顶堆,再将大顶堆的堆顶元素插入到小顶堆。
● 因为两边数据量相同的时候,此时我们插入的数可能会放在小顶堆,也可能会放在大顶堆,我们先把他插入小顶堆,然后将小顶堆pop(得到小顶堆中最大的数),再将其push进大顶堆,此时数据量为奇数,保证不会出现小顶堆中的最大数没法进入大顶堆的现象(因为此时数据变成奇数我们只用大顶堆为答案,如果不先小再大,会漏解(比如小顶堆的原来的堆顶就是答案))
● 当大顶堆数据量更大时,此时我们先插入大顶堆,然后将大顶堆的堆顶插入小顶堆,这个是为了确保两个堆数据平衡
import heapq as h
class MedianFinder:
'''
当拿来一个数num,做出如下操作:
如果大顶堆中的元素数量等于小顶堆中的元素数量,则先将num插入到小顶堆,再将小顶堆的堆顶元素插入到大顶堆;
否则,先将num插入到大顶堆,再将大顶堆的堆顶元素插入到小顶堆。
'''
def __init__(self):
self.min_heap = []
self.max_heap = []
def addNum(self, num: int) -> None:
if len(self.max_heap)==len(self.min_heap):
h.heappush(self.min_heap,num)
val=h.heappop(self.min_heap)
h.heappush(self.max_heap,-val)
else:
h.heappush(self.max_heap,-num)
val=-h.heappop(self.max_heap)
h.heappush(self.min_heap,val)
def findMedian(self) -> float:
if len(self.max_heap)==len(self.min_heap):
return (-self.max_heap[0]+self.min_heap[0])/2
else:
return -self.max_heap[0]
# Your MedianFinder object will be instantiated and called as such:
# obj = MedianFinder()
# obj.addNum(num)
# param_2 = obj.findMedian()














 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









