







前言
由谷歌团队提出的预训练语言模型BERT近年来正在各大自然语言处理任务中屠榜(话说学者们也挺有意思的,模型名都强行凑个芝麻街的人物名,哈哈哈)。 BERT算法的最重要的部分便是Transformer的概念,它本质上是Transformer的编码器部分。 而Transformer是什么呢?transformer是永远的神,自从transformer使用了抛弃rnncnn的纯attention机制之后,各种基于transformer结构的预训练模型都如雨后春笋般雄起,而transformer中最重要就是使用了Self-Attention机制,所以本文会从Attention机制说起。
RNN模型解决seq2seq问题
首先我们举例子,讨论RNN模型如何解决机器翻译问题
我们以机器翻译问题作为基础,逐步讲解注意力机制及它的优缺点。首先,我们来看RNN模型是如何解决机器翻译问题的。这是一个Many to Many(Tx!=Ty)的Seq2Seq序列标注问题。

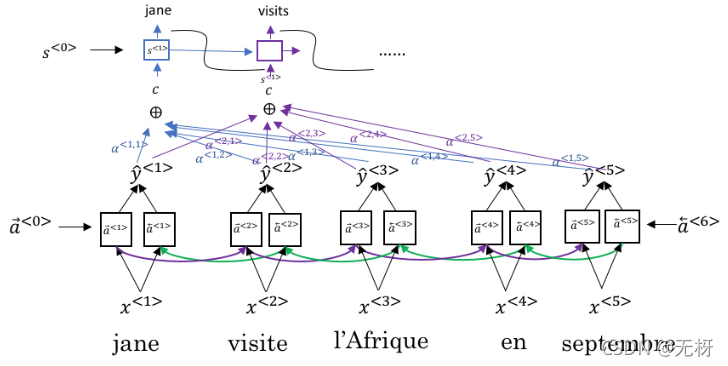
下图为RNN解决这一类输入序列和输出序列长度不等的序列标注问题的常用模型结构:

左边的encoder对输入序列建模,然后在网络的出口处提取最后一个时间步的激活值输出,得到输入序列的表示。编码器最后一个时间步的激活值输出因为走过了整个源文本序列,**所以可以认为它蕴含了需要翻译的整个句子的信息。**它的维度与RNN单元的隐藏层神经元数目一致。当然了,这里的RNN可以是深层的,但我们只以单隐藏层的RNN进行讲解。
右边的decoder部分可以看作是一个条件语言模型(Language Model,例如我们常见的AI写诗模型)。它的作用是通过编码器的表示作为输入,生成当前条件下最大概率的目标语言句子。它与常规的语言模型有两点不同:
- 语言模型零时刻的激活值为零向量,而机器翻译模型解码器的零时刻的激活值为编码器结尾的时间步激活输出。
- 语言模型为了保证生成句子的多样性,所以每个时间步的输出都是按照概率分布随机生成的。而机器翻译模型很明显需要翻译出最准确的结果,所以输出的序列应是全局最大概率的序列。
- 右边的decoder通过使用encode得到的表示和已经预测到的词作为输入,自回归的不断预测下一个词,但是rnn在预测当前词仅仅只用到了前一个cell的hidden state和前一个词作为输入。因此会有长依赖的序列问题。
顺便提一下,机器翻译问题中的全局最优解问题和CRF、HMM等常规机器学习的序列标注模型中类似吗,即解码策略,可以使用维特比算法来解,在对应的博客中都可以找到相应的说明。如果我们使用贪心算法,也就是greedy search,将可能陷入局部最优解中。
因此,特别地,我们发现,当词汇表规模很大时,即使是动态规划的维特比算法,其时空复杂度也会很高(时间复杂度: O ( M N 2 ) O(MN^2) O(MN2),M为时序数,N为词汇表大小)。为了降低计算量,科学家们提出了集束搜索(Beam Search)的方法,即第一次输出时选取概率最高的B个单词,并将它们作为输入投入第二个时间步,第二次输出时仍然只选概率最高的B个单词……以此类推,到最后只会产生B条预测序列,我们选取概率最大的的作为最终的结果。这样做,其实就是在贪心搜索和维特比算法之间进行平衡,当B=1时,集束搜索退化成贪心算法,当B=N时,集束搜索演变成维特比算法。
RNN+Attention
上述RNN架构解决机器翻译会存在一些问题:
因为利用RNN解决机器翻译的时候,我们是将最后一个时间步的输出当做encode后的结果,所以可以认为它蕴含了需要翻译的整个句子的信息。 但是这样的理论在短序列中是有效的,在长序列中则会出现序列过长而无法catch到相对较远的特征,即产生信息瓶颈。
因此科学家在探索的过程中,引入了attention机制,对rnn的每一个时间步的输出学到一个注意力参数,从而对这些特征进行attention加权和,然后也作为decoder阶段的输入。
如下图所示,我们利用双向RNN对输入序列(x1,x2,x3)进行编码,然后对decoder端,我们在解码visits这个词的时候,这个时间步的输入有,
- 上一时刻的激活输出向量,
- 上一时刻的预测结果向量(即上一时刻的输出jane这个词),
- 还有与encode端的每一时间步的输出对应的attention的output(对x1,x2,x3的attention加权和,即对于每一个词的生成去学一个参数,因为不同的x对于不同的y生成的贡献是不一样的,因此需要attention)
引入了attention之后的rnn为基础的机器翻译模型优点有:
Attention机制的优点如下:
- 解决了传统RNN架构的“信息“瓶颈问题。
- 让解码器有选择性地注意与当前翻译相关的源句子中的词。
- 通过使编码器的各时序隐藏层和解码器各时序隐藏层直接相连,使梯度可以更加直接地进行反向传播,缓解了梯度消失问题。
- 增加了机器翻译模型的可解释性。
Transformer: yyds
尽管RNN+Attention的模型非常有效,但它同时也存在着一些缺陷。RNN最主要的缺陷在于:它的计算是有时序依赖的,需要用到前一个时间步或者后一个时间步的信息,这导致它难以并行计算,只能串行计算。而当今时代,GPU的并行化能够大大加速计算过程,如果不能够并行计算,会导致运算速度很低。
为了能够进行并行计算,又不需要多层迭代,科学家们提出了Transformer模型。它的论文题目很霸气《Attention is All You Need》。正如题目所说,Transformer模型通过采用Self-Attention自注意力机制,完全抛弃了传统RNN在水平方向的传播,只在垂直方向上传播,只需要不断叠加Self-Attention层即可。这样,每一层的计算都可以并行进行,可以使用GPU进行加速。
你可以使用Self-Attention层来完成任何RNN层可以做到的事情:
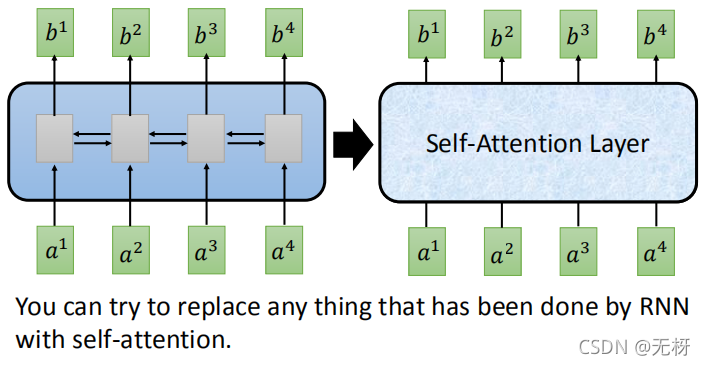
因为transformer用到了self-attention机制,我们首先对这个机制进行介绍:
Self-Attention
Self-Attention层的基本结构如下图所示:
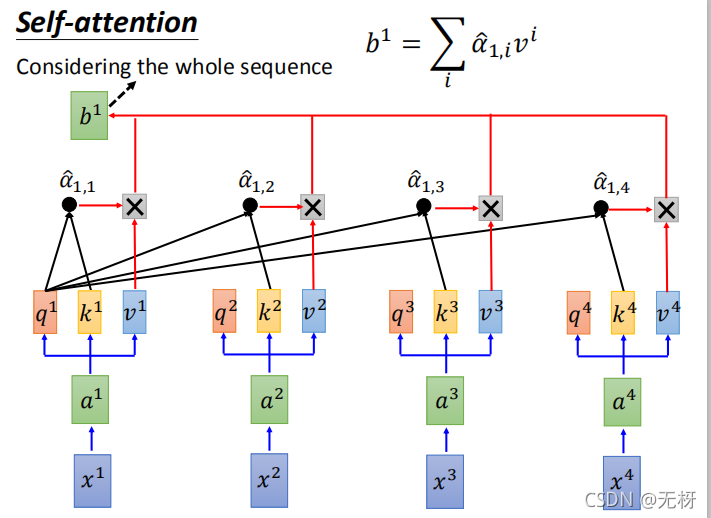
我们以计算 x 1 x_1 x1在输入到self-attention model之后的输出b1为例。
- 首先,我们以第一个单词的Word2Vec等预训练好的词向量作为输入 x 1 x_1 x1,我们可以对其过一个全连接层或者MLP得到 a 1 a_1 a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









