







系统负载命令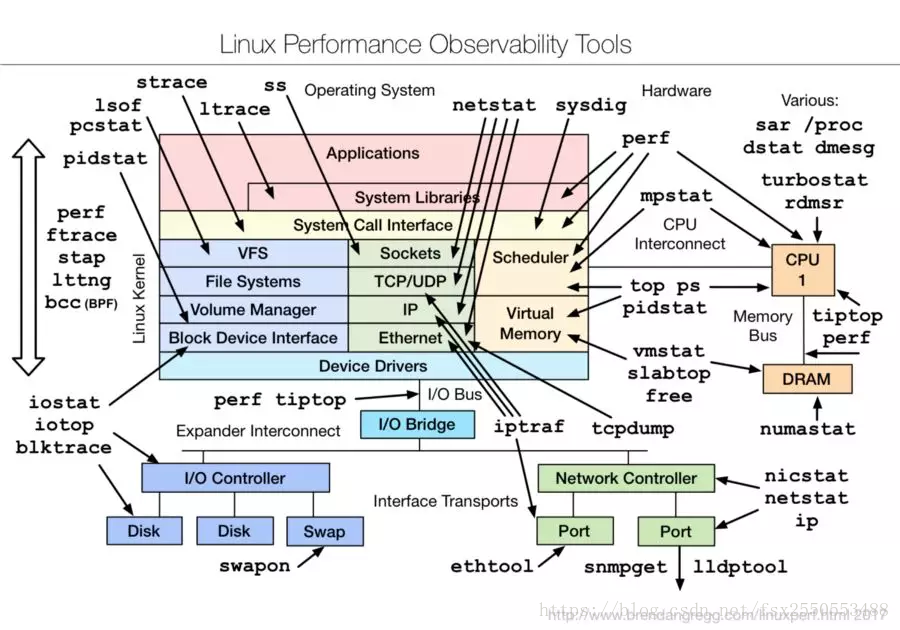
关于查看系统负载,首先得明白什么是系统,自上而下系统层次是什么样子的?查询的时候才能有的放矢。
查看系统负载都要看什么?下面仅仅是部分介绍
-
load averages:系统平均负载
-
cpu usage:cpu利用率
-
kernnel errors:内核错误
-
cpu balance:cpu均摊情况
-
precess usage:进程使用情况
-
disk I/O:磁盘IP
-
memory usage:内存使用情况
-
network I/O:网络IO情况
系统性能查看的常用命令
uptime
正常情况:
[root@localhost ~]# uptime
15:56:38 up 4:48, 3 users, load average: 0.27, 0.35, 0.46有压力情况:
[root@wordpress ~]# uptime
15:58:40 up 3:28, 1 user, load average: 4.04, 0.96, 0.36该命令可以大致看出计算机的整体负载情况,load average后的数字分别表示计算机在1min、5min、10min内的平均负载。
什么是cpu负责?什么是cpu使用率?两者的区别?
dmesg
[root@localhost c]# dmesg | tail
[17409.594158] CPU2: Package temperature above threshold, cpu clock throttled (total events = 92577)
[17409.594162] CPU3: Package temperature above threshold, cpu clock throttled (total events = 92577)
[17409.594170] CPU0: Package temperature above threshold, cpu clock throttled (total events = 92577)
[17409.594171] CPU1: Package temperature above threshold, cpu clock throttled (total events = 92577)
[17409.596154] CPU3: Core temperature/speed normal
[17409.596155] CPU2: Core temperature/speed normal
[17409.596157] CPU2: Package temperature/speed normal
[17409.596169] CPU3: Package temperature/speed normal
[17409.596180] CPU0: Package temperature/speed normal
[17409.596181] CPU1: Package temperature/speed normal打印内核环形缓存区的内容,通过dmesg可以快速判断是否有导致系统性能异常的问题。
vmstat
[root@localhost c]# vmstat 1 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 22280 174936 24676 1211468 0 0 54 10 370 79 6 3 90 1 0
0 0 22280 174420 24776 1211860 0 0 100 328 1404 1958 1 1 98 1 0
1 0 22280 181736 24776 1203704 0 0 0 0 1778 2744 1 1 98 0 0vmstat打印进程、内存、交换分区、IO和CPU等统计信息。1表示间隔1秒打印一次,3表示总公打印三次。
具体:
进程:
r:表示正在运行或者等待CPU调度的进程数,可以查看CPU是否处于饱和状态,如果数字大于CPU核数,则表示已经饱和。
b:表示等待IO的进程数量
内存:
swpd:表示虚拟内存使用大小
si:每秒从交换分区写入内存的大小,由磁盘调入内存
so:每秒写入交换分区的内存大小,由内存调入磁盘
这里:如果swpd不为0,但是si和so为0,则不影响系统性能
free:表示空闲物理内存大小
buff:buffer cache使用大小
cache:page cache使用大小
bi:每秒读取的块数
bo:每秒写入的块数
如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
系统:
in:每秒中断数,包括时钟中断
cs: 每秒上下文切换数
CPU:
us:用户进程执行时间百分比
sy: 内核系统进程执行时间百分比
wa: IO等待时间百分比
id: 空闲时间百分比
mpstat
[root@localhost c]# mpstat
Linux 3.10.0-862.el7.x86_64 (localhost.localdomain) 08/25/2018 _x86_64_ (4 CPU)
04:29:27 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
04:29:27 PM all 6.15 0.04 2.53 0.74 0.00 0.00 0.00 0.11 0.00 90.43
[root@localhost c]# mpstat -P ALL
Linux 3.10.0-862.el7.x86_64 (localhost.localdomain) 08/25/2018 _x86_64_ (4 CPU)
04:30:04 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
04:30:04 PM all 6.15 0.04 2.53 0.74 0.00 0.00 0.00 0.11 0.00 90.44
04:30:04 PM 0 6.18 0.06 2.91 1.48 0.00 0.02 0.00 0.07 0.00 89.29
04:30:04 PM 1 6.23 0.02 2.24 0.48 0.00 0.00 0.00 0.04 0.00 90.99
04:30:04 PM 2 5.99 0.05 2.71 0.60 0.00 0.00 0.00 0.07 0.00 90.59
04:30:04 PM 3 6.19 0.02 2.28 0.40 0.00 0.00 0.00 0.24 0.00 90.88
每秒打印一次每个CPU的统计信息,用来查看CPU调度是否均匀。
pidstat
[root@localhost c]# pidstat 1 1
Linux 3.10.0-862.el7.x86_64 (localhost.localdomain) 08/25/2018 _x86_64_ (4 CPU)
04:31:12 PM UID PID %usr %system %guest %CPU CPU Command
04:31:13 PM 0 9 0.00 0.98 0.00 0.98 2 rcu_sched
04:31:13 PM 0 2599 0.98 0.00 0.00 0.98 3 gnome-shell
04:31:13 PM 0 3998 0.98 0.00 0.00 0.98 0 firefox
04:31:13 PM 107 6487 0.98 0.00 0.00 0.98 0 qemu-kvm
04:31:13 PM 0 9914 0.98 0.98 0.00 1.96 2 plugin-containe
04:31:13 PM 0 11492 0.00 0.98 0.00 0.98 0 kworker/u16:4
04:31:13 PM 0 11532 0.00 0.98 0.00 0.98 0 pidstat
Average: UID PID %usr %system %guest %CPU CPU Command
Average: 0 9 0.00 0.98 0.00 0.98 - rcu_sched
Average: 0 2599 0.98 0.00 0.00 0.98 - gnome-shell
Average: 0 3998 0.98 0.00 0.00 0.98 - firefox
Average: 107 6487 0.98 0.00 0.00 0.98 - qemu-kvm
Average: 0 9914 0.98 0.98 0.00 1.96 - plugin-containe
Average: 0 11492 0.00 0.98 0.00 0.98 - kworker/u16:4
Average: 0 11532 0.00 0.98 0.00 0.98 - pidstat
[root@localhost c]# id 107
uid=107(qemu) gid=107(qemu) groups=107(qemu),36(kvm)
[root@localhost c]# id 0
uid=0(root) gid=0(root) groups=0(root)
打印各个进程对CPU的占用情况,可以滚动打印。
iostat
类似以vmstat
[root@localhost conf]# iostat
Linux 3.10.0-862.el7.x86_64 (localhost.localdomain) 08/25/2018 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
6.25 0.04 2.51 0.78 0.00 90.43
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sdb 0.03 0.84 0.00 16603 40
sda 5.59 228.10 36.99 4494250 728872
dm-0 7.22 226.40 35.55 4460909 700372
dm-1 0.39 0.25 1.45 4836 28476
dm-2 0.01 0.13 0.00 2540 4
[root@localhost conf]# iostat -xz 1 1
Linux 3.10.0-862.el7.x86_64 (localhost.localdomain) 08/25/2018 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
6.22 0.04 2.49 0.78 0.00 90.47
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdb 0.04 0.00 0.03 0.00 0.84 0.00 51.85 0.00 100.48 90.66 1141.83 40.76 0.13
sda 1.08 0.89 3.37 2.23 227.18 37.04 94.26 0.50 88.75 44.82 155.16 6.74 3.78
dm-0 0.00 0.00 4.49 2.77 225.50 35.60 71.94 0.65 89.20 43.34 163.56 5.18 3.76
dm-1 0.00 0.00 0.03 0.36 0.24 1.44 8.71 0.03 71.90 62.60 72.60 1.76 0.07
dm-2 0.00 0.00 0.01 0.00 0.13 0.00 26.09 0.00 49.24 49.47 3.00 25.06 0.02r/s、w/s、rkB/s、wkB/s分别表示每秒向IO设备发出的read、write、read Kbytes、write Kbytes的数量。
avgqu-sz表示请求被发送给IO设备的平均时间,如果大于1,可能IO设备已经饱和。
%util,每秒设备的利用率,超过百分之六十,则表示设备出现异常。
free
[root@localhost conf]# free -w -m
total used free shared buffers cache available
Mem: 3676 2500 214 312 10 952 572
Swap: 3815 28 3787重点理解buffer和cache的区别。
Page cache主要用来作为文件系统上的文件数据的缓存来用,尤其是针对当进程对文件有read/write操作的时候。如果可以影射文件到内存的系统调用,mmap也可以用到page cache
Buffer cache主要设计用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用。这就意味着某些对块的操作会使用buffer cache进行缓存。
sar
sar是System Activity Reporter的缩写。系统活动状态报告。
df
[root@localhost conf]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/rhel-root 262G 26G 223G 11% /
devtmpfs 1.8G 0 1.8G 0% /dev
tmpfs 1.8G 86M 1.8G 5% /dev/shm
tmpfs 1.8G 9.8M 1.8G 1% /run
tmpfs 1.8G 0 1.8G 0% /sys/fs/cgroup
/dev/sdb5 193G 126G 57G 69% /mnt/mount1
/dev/loop0 4.4G 4.4G 0 100% /var/www/html/fsx7.5
/dev/sda1 938M 141M 750M 16% /boot
/dev/mapper/rhel-home 28G 45M 27G 1% /home
tmpfs 368M 68K 368M 1% /run/user/0
查看磁盘负载的命令
top
很重要很重要
top命令用于显示系统运行的进程信息,作用类似于windows中的任务管理器,只不过top不是图形化的,而是显示实时文本信息。top是Linux操作系统的一个强大的统计系统信息的命令。
top命令分为三大部分:
-
系统信息:显示系统相关信息
-
top交互命令行:这是位与系统信息和进程列表之间的一行空白,用户可以在此进行操作。
-
进程列表:显示进程信息
在命令行执行top命令得到如下的终端显示:
top - 17:12:14 up 14 min, 2 users, load average: 0.59, 0.94, 0.81
Tasks: 231 total, 1 running, 230 sleeping, 0 stopped, 0 zombie
%Cpu(s): 5.6 us, 1.5 sy, 0.0 ni, 92.3 id, 0.7 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 3767516 total, 3499504 used, 268012 free, 16272 buffers
KiB Swap: 4079612 total, 0 used, 4079612 free. 2019368 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3065 root 20 0 1613128 120864 34784 S 8.3 3.2 1:16.10 gnome-shell
4000 root 20 0 1245344 155180 35832 S 8.0 4.1 1:26.69 plugin-con+
3523 root 20 0 1474148 361260 57888 S 6.0 9.6 2:02.69 firefox
955 root 20 0 170756 21684 10120 S 3.3 0.6 0:36.29 Xorg
3009 root 9 -11 557020 8080 5144 S 2.7 0.2 0:10.24 pulseaudio
3314 root 20 0 798828 19632 12908 S 2.0 0.5 0:01.40 gnome-term+
3728 qemu 20 0 1140272 226188 8000 S 1.7 6.0 0:40.31 qemu-kvm
3093 root 20 0 462008 6536 3380 S 0.3 0.2 0:04.25 ibus-daemon
5613 root 20 0 0 0 0 S 0.3 0.0 0:00.36 kworker/u1+
5678 root 20 0 1242092 92536 37452 S 0.3 2.5 0:08.61 Typora
9556 root 20 0 0 0 0 S 0.3 0.0 0:00.15 kworker/u1+
10127 root 20 0 123660 1708 1156 R 0.3 0.0 0:00.12 top
1 root 20 0 50580 4392 2324 S 0.0 0.1 0:00.97 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.03 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:+ top命令本身可以带选项参数:
-b:以批处理模式操作; -c:显示完整的治命令; -d:屏幕刷新间隔时间; -I:忽略失效过程; -s:保密模式; -S:累积模式; -i<时间>:设置间隔时间; -u<用户名>:指定用户名; -p<进程号>:指定进程; -n<次数>:循环显示的次数。
系统信息内容详解
top - 17:12:14 当前系统时间
up 14 min 当前系统已经运行时间
2 users 当前登陆用户数
load average: 0.59, 0.94, 0.81 系统负载,即任务队列的平均长度
Tasks: 231 total 总进程数
1 running 当前运行的进程数
230 sleeping 当前睡眠的进程数
0 stopped 当前停止的进程数
0 zombie 当前僵尸进程数
%Cpu(s): 5.6 us 用户空间占用cpu百分比
1.5 sy 内核空间占用cpu百分比
0.0 ni 用户进程空间内改变过优先级的进程占用cpu百分比
92.3 id 空闲cpu百分比
0.7 wa 等待输入输出的cpu时间百分比
0.0 hi
0.0 si
0.0 st
KiB Mem 以KIB为单为输出内存相关信息
3767516 total 总物理内存量
3499504 used 已经使用的物理内存量
268012 free 空闲的内存总量
16272 buffers 用作内核缓存的内存量
KiB Swap swap(交换分区)分区相关信息,以KIB为单为表示
4079612 total 交换分区分区总量
0 used 已经使用的交换分区量
4079612 free 剩余交换分区量
2019368 cached Mem 缓冲区交换分区总量
提示:
MB的单位以10为底数的指数,MiB是以2为底数的指数,如:1KB=10^3=1000, 1MB=10^6=1000000=1000KB,1GB=10^9=1000000000=1000MB,而1KiB=2^10=1024,1MiB=2^20=1048576=1024KiB。
top交互命令行
在top命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了-s选项, 其中一些命令可能会被屏蔽。
h:显示帮助画面,给出一些简短的命令总结说明; k:终止一个进程; i:忽略闲置和僵死进程,这是一个开关式命令; q:退出程序; r:重新安排一个进程的优先级别; S:切换到累计模式; s:改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成ms。输入0值则系统将不断刷新,默认值是5s;即每次top动态刷新一次的时间差 f或者F:从当前显示中添加或者删除项目; o或者O:改变显示项目的顺序; l:切换显示平均负载和启动时间信息; m:切换显示内存信息; //是否显示内存信息的开关 t:切换显示进程和CPU状态信息; //是否显示cpu信息的开关 c:切换显示命令名称和完整命令行; M:根据驻留内存大小进行排序; P:根据CPU使用百分比大小进行排序; T:根据时间/累计时间进行排序; w:将当前设置写入~/.toprc文件中。
示例:
在top交互模式下,输入 1 参数,切换显示平均负载和启动时间信息。(就是多核cpu的每一个cpu信息)
top - 17:56:29 up 59 min, 3 users, load average: 0.30, 0.34, 0.43
Tasks: 228 total, 1 running, 227 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.4 us, 0.0 sy, 0.0 ni, 99.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 s
%Cpu1 : 3.7 us, 0.4 sy, 0.0 ni, 95.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 s
%Cpu2 : 0.4 us, 0.4 sy, 0.0 ni, 99.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 s
%Cpu3 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 s
KiB Mem: 3767516 total, 3330080 used, 437436 free, 15932 buffers
//这是系统信息的详细内容,可以看出cpu栏,被详细显示进程列表
这是进程列表的一部分内容:第一行内容是每一列的进程项,表明是什么含义。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3065 root 20 0 1613128 120864 34784 S 8.3 3.2 1:16.10 gnome-shell
4000 root 20 0 1245344 155180 35832 S 8.0 4.1 1:26.69 plugin-con+ 对每个进程项进行解释:
PID 进程ID号
UESR 进程所属用户
PR 优先级
NI nice值,负值表示高优先级,正值表示低优先级
VIRT 进程使用的虚拟内存总量,单为KB。VIRT=SWAP+RES
RES 进程使用的,未被换出的物理内存大小,单为KB。RES=code+data
SHR 共享内存大小,单为KB
S 进程状态:
%CPU 上次更新到现在使用的cpu比
%MEM 上次更新到现在使用的内存比
TIME+ 进程使用的cpu总时间,单为1/100秒
COMMAND 命令
其中S表示进程状态,进程状态有:
-
D=不可中断的睡眠状态
-
R=运行
-
S=睡眠
-
T=跟踪/停止
-
Z=僵尸进程
感受一下top可以显示的所有进程列表项:
PID = Process Id PGRP = Process Group vMj = Major Faults
* USER = Effective Use TTY = Controlling T vMn = Minor Faults
* PR = Priority TPGID = Tty Process G USED = Res+Swap Size
* NI = Nice Value SID = Session Id nsIPC = IPC namespace
* VIRT = Virtual Image nTH = Number of Thr nsMNT = MNT namespace
* RES = Resident Size P = Last Used Cpu nsNET = NET namespace
* SHR = Shared Memory TIME = CPU Time nsPID = PID namespace
* S = Process Statu SWAP = Swapped Size nsUSER = USER namespac
* %CPU = CPU Usage CODE = Code Size (Ki nsUTS = UTS namespace
* %MEM = Memory Usage DATA = Data+Stack (K
* TIME+ = CPU Time, hun nMaj = Major Page Fa
* COMMAND = Command Name/ nMin = Minor Page Fa
PPID = Parent Proces nDRT = Dirty Pages C
UID = Effective Use WCHAN = Sleeping in F
RUID = Real User Id Flags = Task Flags <s
RUSER = Real User Nam CGROUPS = Control Group
SUID = Saved User Id SUPGIDS = Supp Groups I
SUSER = Saved User Na SUPGRPS = Supp Groups N
GID = Group Id TGID = Thread Group
GROUP = Group Name ENVIRON = Environment v















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









