










1.背景
最近在阅读论文的时候接触到了古德-图灵估计法,感觉比较模糊不清,进一步查阅了一些资料,希望有一个自己的直观理解。
…本论文采用的是古德-图灵估计法,其基本思想是对于任意出现r次的n元语法对,都假设它出现了r*次,即降低高概率的n元语法对,提高低概率的n元语法对…
1.1 为什么要用平滑技术?
通常来讲,我们认为N-gram模型是一个无监督模型,具有非常大的语料库。
然而,语料库再大,也会出现未知的N元对。
以bigram为例,p(鼠标|弃飞),语料库再大这个p(鼠标|弃飞)也该等于0吧?天王老子来了也是0(手动狗头
等于0有什么后果呢?
请做一道速算题,1秒出答案:
847/129333.333838*(109-23)/(33+100)*0=?
以我南山幼儿园珠心算冠军的名义,这显然等于0。
所以,以马尔科夫假设为基础的N-gram模型也会等于0。
当然,这只是举一个简单的例子,实际应用中可能不会受到影响,可能会受到更大的影响。
2. 什么是Good-Turning 平滑技术?
这一小节转载自:https://www.cnblogs.com/yhzhou/p/13308734.html

一般情况下,发生次数为r的词个数大于发生次数为r+1的词个数,r越大,词的数量Nr越小。通过Good-turning smooth可以让数据稀疏度有效的降低,所有词的概率估计会看起来很平滑。
通俗来说,有
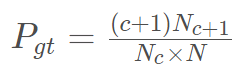
(公式里的c就是前文中的dr)
3. 具体实例
这里参考前辈的例子,并加以补充:https://blog.csdn.net/lt326030434/article/details/87893601
假设你在钓鱼,已经抓到了18只鱼:
10条鲤鱼,3条黑鱼,2条刀鱼,1条鲨鱼,1条草鱼,1条鳗鱼…
Q1:下一个钓到的鱼是鲨鱼的概率是多少?
Q2:下一条鱼是娃娃鱼的概率是多少?
当我没学过Good-Turning的时候,
Q1:天王老子来了也是 1/18
Q2: 天王老子来了也是0
学了Good-Turning之后:
我们先看Q2,
Q2:Good-Turning方法论中,我们会假设未出现过的鱼种的概率与出现一次的鱼种的概率相同,即N_0 = N_1 (N_k表示出现k次的元素的总数),在上面的例子中N_10=1,N_3=1,N_2=1,N_1=3。
此时Q2的结果也为3/18,即1/6。
回过头看Q1,
Q1:参考第二节的公式,出现一次的东西要使用到出现2次的东西,陶金公式得
p(shayu)= (1+1)*1/3/18= 1/27















 1331
1331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









