







最近拿到一台n卡4090ti的机器,lora-sdxl训练跑的动,好兴奋啊
还没碰到机器,被告知是ubuntu的,以前windows的经验供参考了,还好模型和工程都是相通,果断折腾起来。经过大概一周的时间(上周开始的),将环境啥啥都跑通了。xformers==0.0.26.post1 torch==2.3.0+cu121,这个accelerate要安装一下,剩下的就是pip install -r requrements.txt,当然跟前文windows一样,需要改一些内容以避免每次启动的时候反复安装卸载等等,总之就是跑通了。这次也是GitHub - bmaltais/kohya_ss 加 GitHub - LarryJane491/Lora-Training-in-Comfy: This custom node lets you train LoRA directly in ComfyUI!
安装没太大问题,先开测一下SD1.5的训练,很丝滑,几秒几完成了。等等,lora-training-in-comfyui在哪里选sdxl模型的?呃,没找到,使用sdxl的checkpoints,类似sd1.5,好像也能跑,就是怎么跑都出错而已。原来它没开启sdxl模式,还是调用train_netword.py(正常的应该会切换到sdxl_train_network.py的),好吧,这个问题应该不难解决,直接改一下train.py让它只支持sdxl也可以解决的,先放一边吧。
回过头来玩玩kohya-ss-gui吧,在调用的时候需要注意一下
./gui.sh --listen={ip} --server_port 7860 --headless
为啥加--listen呢,主要是为了局域网也能玩,不同的机器嘛(默认只能是本机调用的)。
好了。这时候的GPU显存只用了19M,没错,Ubuntu这些linux系列的占用资源很少,不扯了,开动。浏览器打开http://{ip}:7860,可以看到一个这样的界面
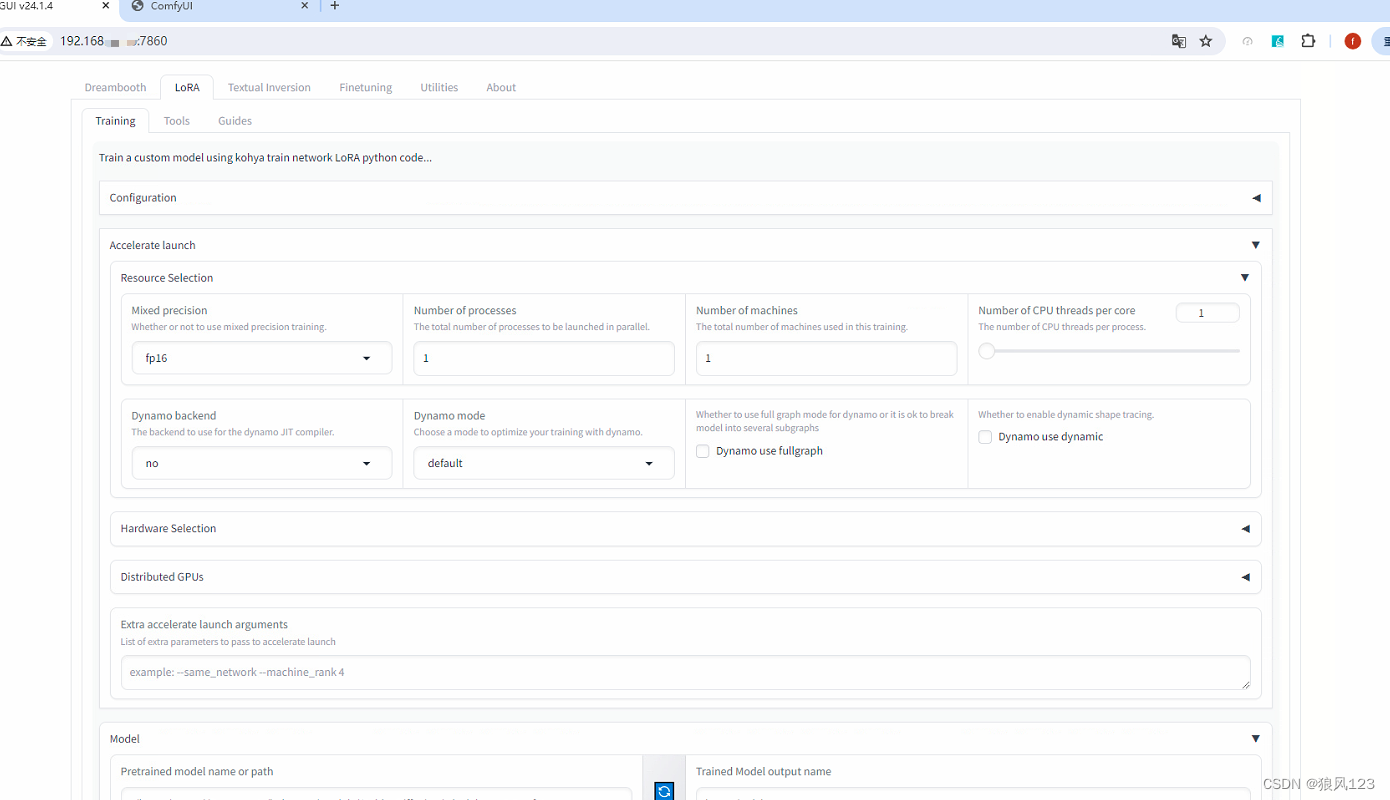
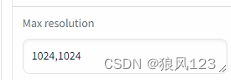
首先我尝试了默认的参数,只修改model路径,图片路径和输出路径,resolution="1024,1024"(听说是标准配置),点了“start training”,果断给我报错了,还是那句话“...CUDA out of memory...”,这24G的显存都搞不定???好吧,我改,将resolution改到"768,768",通了!这很明显就是吃显存的大坑啊。
经过两三天的资料整理和尝试,今天总算能跑标准SDXL的训练流程了。下面就是几张图,然后我会啰嗦一下关联的东东。
1.配置混合视觉(这个听说是优化过的,听说显卡占用是full float>bp16>fp16这样的关系,我没法验证,只知道使用no就瞬间破24G,训练GG)
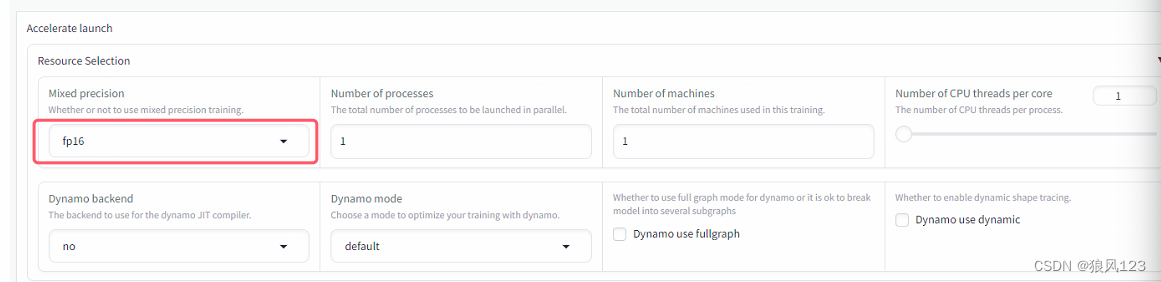
上回说了,将mixed percision改成no,其实这个是一个坑,虽然在低端显卡环境下保证能进入cache latent,但是没啥用啊,在4090面前就不要选择no了,它也扛不住啊,我也是经过了无数次(大概30次吧)的失败后,才将这个改成fp16的。为什么要改成fp16?大概因为它占用显存最少吧!
2.配置模块和图片位置(ssh将图片送过去)
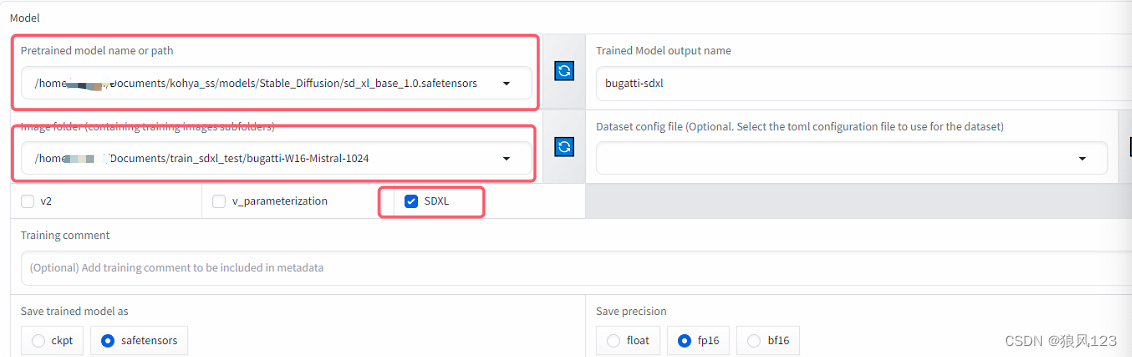
3.配置meta(我随便写的)

4.输出路径,这里会输出过渡文件类似xxx_0000001.safetensors之类的,这些文件的个数跟epoch和图片个数、最大训练梯度累计(max train epoch),最大训练步数(max train steps)相关。一般来说,将"最大训练梯度累计"和“最大训练步数”都配置为0,则得到训练步数=epoch*图片张数*文件夹设定的数值(例如文件夹名是20_title,表示当前的文件夹每个图片都训练20次),举例说明一下。我的训练图片路径下就只有一个子文件夹“20_girls”,里面放了100张美女照片,epoch设置为10,那么训练步数=20*100*10,即2万次。假设填上了"最大训练梯度累计"和“最大训练步数”,就会先比较填写的epoch和"最大训练梯度累计"的值,拿到最大值epoch_max,这里我假设"最大训练梯度累计"=10,那么tmp_train_steps=epoch_max*100*10=10000; 训练步数大于最大训练步数时,好像没啥用,还是按sum_a=sum(文件名前缀数值*张数);epoch_max=max(epoch,最大训练梯度累计),然后sum_a*epoch_max得到总训练步数,啊啊啊啊啊啊~~尴尬...最大训练步数==0时,不起作用,当最大训练步数>0时,就要比较计算出来的训练总步数,然后max(最大训练步数,训练总步数)? 有点混乱啊。好吧,说一个真实的案例,训练目录下有两个文件夹,150_aa有4张图,150_bb有8张,epoch=10,max epoch=20 计算的步数=(150*4+150*8)*20=36000!

5.配置批次(train batch size)和梯度累计(epoch),cache latents和cache latents to disk,可以自行选择,建议点上cache latents,不建议开cache latents to disk。这里重点是批次和梯度累计!
经过反复试验,网上说的显卡8G选择1,16G+可以选择6等等,这个版本都行不通,只有1才能过,估摸是这个版本的显存没优化好,占用特别多,后面我会贴一个显存使用的情况图。其次就是epoch,网上一堆说这个增加了就可以减少显存占用,但是在这里行不通!
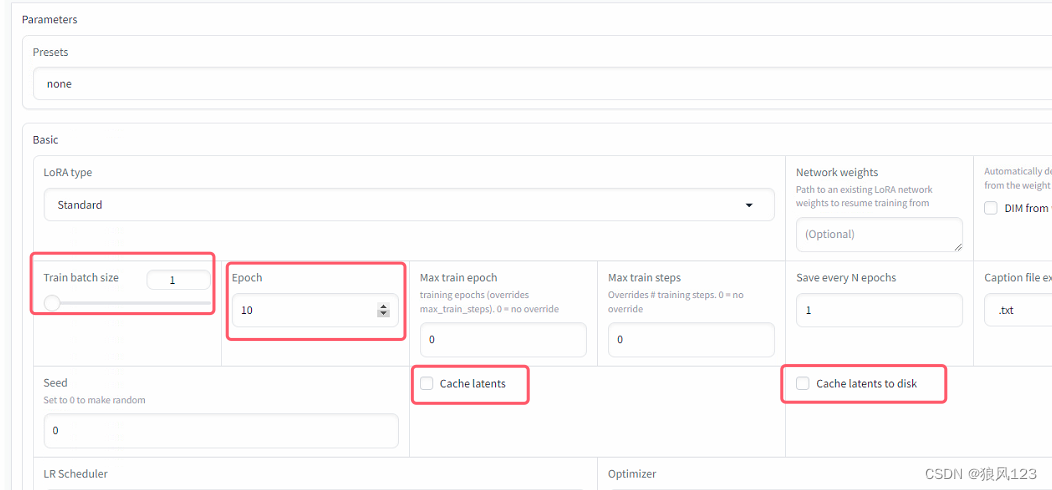
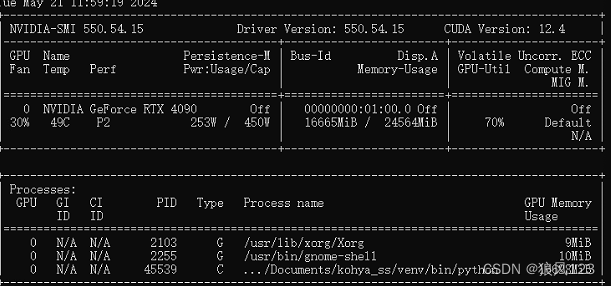
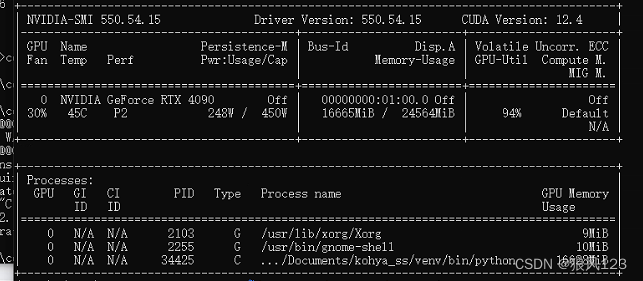
这个设置了不同的epoch数值的,但是显存占用一直都是16.6G附近,很明显这个版本是不太可能通过调梯度累计实现的。我这里有几张图片,训练都是1-2次的,得到一个简单表格
| Epoch | 显存占用 | 训练时间 |
| 10 | 16.6G | 1:43 |
| 20 | 16.6G | 3:27 |
| 40 | 16.6G | 6:57 |
| 80 | 16.6G | 13:51 |
很明显吧,这个版本的显存占用是固定的,训练时间和epoch就线性关系。
6.优化器这里选择PageAdamW8bit,默认是AdamW8bit,我开始以为是一样的,结果不一样。选择AdamW8bit死活就过去,估计显存还要很多吧。。。

7.配置分辨率
8.选上no half VAE,看小字说明吹得挺好的。

9.终于可以开始训练了。

先写到这里,后续魔改好Comfyui版本再补充。
20240523 魔改版的Lora-Training-in-Comfy for ComfyUI来了。
首先进入{Comfyui_install_path}/ComfyUI/custom_nodes/Lora-Training-in-Comfy目录,找到train.py
1.修改“class LoraTraininginComfy”下的“INPUT_TYPES”和“loratraining”,我也懒得截图,直接上程序
这里增加了optimizerType和is_sdxml两个参数,旧版的默认优化器是AdamW8bit,这个优化器我在训练Lora的时候吃尽苦头,4090Ti 24G的显卡一下子撑爆,所以还是将那些优化器全部移过来吧。这个参数是在https://github.com/bmaltais/kohya_ss.git里面找到的,不保证全部能用,选择好自己适合的来用,例如“PagedAdamW8bit”😄函数loratraining就增加参数和INPUT_TYPES一一对应,将优化器传递过去“optimizer_type = optimizerType”,还做了is_sdxl的判断,因为sdxl训练跑的是sdxl_train_network.py,┗|`O′|┛ 嗷~~,忘记了,这个只支持network.lora,其他模式可能出问题,没测试过,所以不确定哦。
嗯,先上图需要修改哪里,后面再抄作业
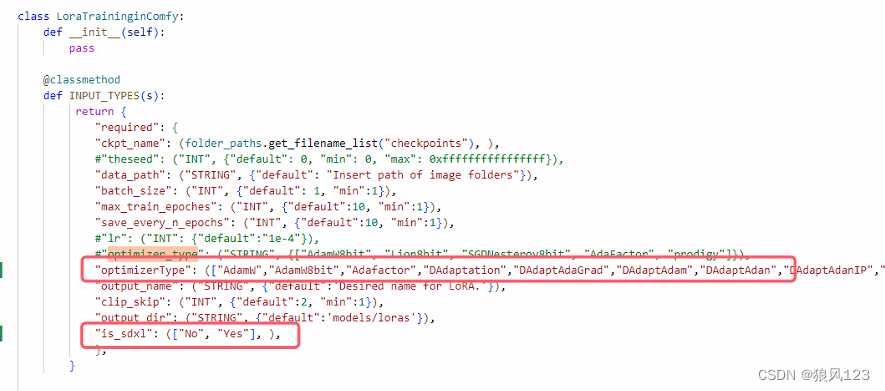
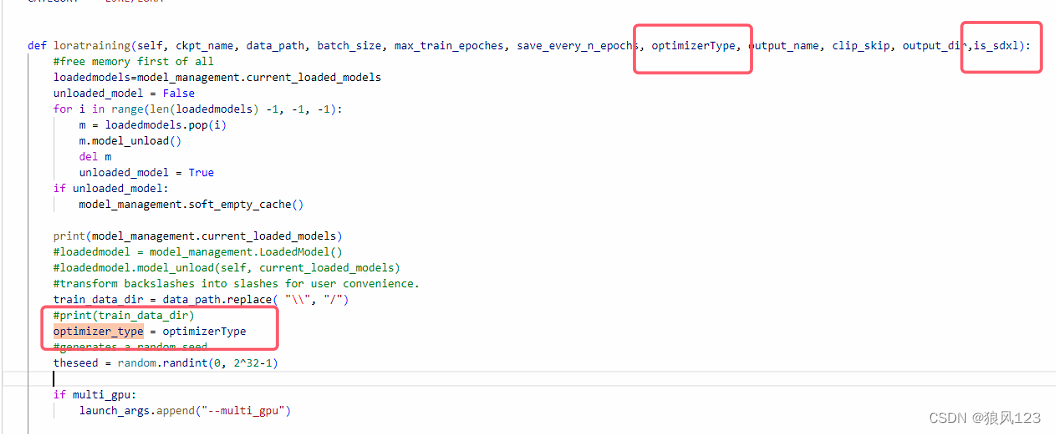

def INPUT_TYPES(s):
return {
"required": {
"ckpt_name": (folder_paths.get_filename_list("checkpoints"), ),
#"theseed": ("INT", {"default": 0, "min": 0, "max": 0xffffffffffffffff}),
"data_path": ("STRING", {"default": "Insert path of image folders"}),
"batch_size": ("INT", {"default": 1, "min":1}),
"max_train_epoches": ("INT", {"default":10, "min":1}),
"save_every_n_epochs": ("INT", {"default":10, "min":1}),
#"lr": ("INT": {"default":"1e-4"}),
#"optimizer_type": ("STRING", {["AdamW8bit", "Lion8bit", "SGDNesterov8bit", "AdaFactor", "prodigy"]}),
"optimizerType": (["AdamW","AdamW8bit","Adafactor","DAdaptation","DAdaptAdaGrad","DAdaptAdam","DAdaptAdan","DAdaptAdanIP","DAdaptAdamPreprint","DAdaptLion","DAdaptSGD","Lion","Lion8bit","PagedAdamW8bit","PagedAdamW32bit","PagedLion8bit","Prodigy","SGDNesterov","SGDNesterov8bit",], ),
"output_name": ("STRING", {"default":'Desired name for LoRA.'}),
"clip_skip": ("INT", {"default":2, "min":1}),
"output_dir": ("STRING", {"default":'models/loras'}),
"is_sdxl": (["No", "Yes"], ),
},
}
def loratraining(self, ckpt_name, data_path, batch_size, max_train_epoches, save_every_n_epochs,optimizerType, output_name, clip_skip, output_dir,is_sdxl):
#free memory first of all
loadedmodels=model_management.current_loaded_models
unloaded_model = False
for i in range(len(loadedmodels) -1, -1, -1):
m = loadedmodels.pop(i)
m.model_unload()
del m
unloaded_model = True
if unloaded_model:
model_management.soft_empty_cache()
print(model_management.current_loaded_models)
#loadedmodel = model_management.LoadedModel()
#loadedmodel.model_unload(self, current_loaded_models)
#transform backslashes into slashes for user convenience.
train_data_dir = data_path.replace( "\\", "/")
#print(train_data_dir)
optimizer_type = optimizerType #get optimizer
#generates a random seed
theseed = random.randint(0, 2^32-1)
if multi_gpu:
launch_args.append("--multi_gpu")
if lowram:
ext_args.append("--lowram")
if is_v2_model:
ext_args.append("--v2")
else:
ext_args.append(f"--clip_skip={clip_skip}")
if parameterization:
ext_args.append("--v_parameterization")
if train_unet_only:
ext_args.append("--network_train_unet_only")
if train_text_encoder_only:
ext_args.append("--network_train_text_encoder_only")
if network_weights:
ext_args.append(f"--network_weights={network_weights}")
if reg_data_dir:
ext_args.append(f"--reg_data_dir={reg_data_dir}")
if optimizer_type:
ext_args.append(f"--optimizer_type={optimizer_type}")
if optimizer_type == "DAdaptation":
ext_args.append("--optimizer_args")
ext_args.append("decouple=True")
if network_module == "lycoris.kohya":
ext_args.extend([
f"--network_args",
f"conv_dim={conv_dim}",
f"conv_alpha={conv_alpha}",
f"algo={algo}",
f"dropout={dropout}"
])
if noise_offset != 0:
ext_args.append(f"--noise_offset={noise_offset}")
if stop_text_encoder_training != 0:
ext_args.append(f"--stop_text_encoder_training={stop_text_encoder_training}")
if save_state == 1:
ext_args.append("--save_state")
if resume:
ext_args.append(f"--resume={resume}")
if min_snr_gamma != 0:
ext_args.append(f"--min_snr_gamma={min_snr_gamma}")
if persistent_data_loader_workers:
ext_args.append("--persistent_data_loader_workers")
if use_wandb == 1:
ext_args.append("--log_with=all")
if wandb_api_key:
ext_args.append(f"--wandb_api_key={wandb_api_key}")
if log_tracker_name:
ext_args.append(f"--log_tracker_name={log_tracker_name}")
else:
ext_args.append("--log_with=tensorboard")
launchargs=' '.join(launch_args)
extargs=' '.join(ext_args)
pretrained_model = folder_paths.get_full_path("checkpoints", ckpt_name)
#Looking for the training script.
progpath = os.getcwd()
nodespath=''
#auto sdxl
if not is_sdxl:
for dirpath, dirnames, filenames in os.walk(progpath):
if 'sd-scripts' in dirnames:
nodespath= dirpath + '/sd-scripts/train_network.py'
print(nodespath)
else:
for dirpath, dirnames, filenames in os.walk(progpath):
if 'sd-scripts' in dirnames:
nodespath= dirpath + '/sd-scripts/sdxl_train_network.py'
print(nodespath)
nodespath = nodespath.replace( "\\", "/")
command = "python -m accelerate.commands.launch " + launchargs + f'--num_cpu_threads_per_process=2 "{nodespath}" --enable_bucket --pretrained_model_name_or_path={pretrained_model} --train_data_dir="{train_data_dir}" --output_dir="{output_dir}" --logging_dir="./logs" --log_prefix={output_name} --resolution={resolution} --network_module={network_module} --max_train_epochs={max_train_epoches} --learning_rate={lr} --unet_lr={unet_lr} --text_encoder_lr={text_encoder_lr} --lr_scheduler={lr_scheduler} --lr_warmup_steps={lr_warmup_steps} --lr_scheduler_num_cycles={lr_restart_cycles} --network_dim={network_dim} --network_alpha={network_alpha} --output_name={output_name} --train_batch_size={batch_size} --save_every_n_epochs={save_every_n_epochs} --mixed_precision="fp16" --save_precision="fp16" --seed={theseed} --cache_latents --prior_loss_weight=1 --max_token_length=225 --caption_extension=".txt" --save_model_as={save_model_as} --min_bucket_reso={min_bucket_reso} --max_bucket_reso={max_bucket_reso} --keep_tokens={keep_tokens} --xformers --shuffle_caption ' + extargs
#print(command)
subprocess.run(command, shell=True)
print("Train finished")
#input()
return ()
另外Advance版本也类似修改,还是直接上代码凑数吧
def INPUT_TYPES(s):
return {
"required": {
"ckpt_name": (folder_paths.get_filename_list("checkpoints"), ),
"v2": (["No", "Yes"], ),
"networkmodule": (["networks.lora", "lycoris.kohya"], ),
"networkdimension": ("INT", {"default": 32, "min":0}),
"networkalpha": ("INT", {"default":32, "min":0}),
"trainingresolution": ("INT", {"default":512, "step":8}),
"data_path": ("STRING", {"default": "Insert path of image folders"}),
"batch_size": ("INT", {"default": 1, "min":1}),
"max_train_epoches": ("INT", {"default":10, "min":1}),
"save_every_n_epochs": ("INT", {"default":10, "min":1}),
"keeptokens": ("INT", {"default":0, "min":0}),
"minSNRgamma": ("FLOAT", {"default":0, "min":0, "step":0.1}),
"learningrateText": ("FLOAT", {"default":0.0001, "min":0, "step":0.00001}),
"learningrateUnet": ("FLOAT", {"default":0.0001, "min":0, "step":0.00001}),
"learningRateScheduler": (["cosine_with_restarts", "linear", "cosine", "polynomial", "constant", "constant_with_warmup"], ),
"lrRestartCycles": ("INT", {"default":1, "min":1}),
"optimizerType": (["AdamW","AdamW8bit","Adafactor","DAdaptation","DAdaptAdaGrad","DAdaptAdam","DAdaptAdan","DAdaptAdanIP","DAdaptAdamPreprint","DAdaptLion","DAdaptSGD","Lion","Lion8bit","PagedAdamW8bit","PagedAdamW32bit","PagedLion8bit","Prodigy","SGDNesterov","SGDNesterov8bit",], ),
"output_name": ("STRING", {"default":'Desired name for LoRA.'}),
"algorithm": (["lora","loha","lokr","ia3","dylora", "locon"], ),
"networkDropout": ("FLOAT", {"default": 0, "step":0.1}),
"clip_skip": ("INT", {"default":2, "min":1}),
"output_dir": ("STRING", {"default":'models/loras'}),
"is_sdxl": (["No", "Yes"], ),
},
}
def loratraining(self, ckpt_name, v2, networkmodule, networkdimension, networkalpha, trainingresolution, data_path, batch_size, max_train_epoches, save_every_n_epochs, keeptokens, minSNRgamma, learningrateText, learningrateUnet, learningRateScheduler, lrRestartCycles, optimizerType, output_name, algorithm, networkDropout, clip_skip, output_dir,is_sdxl):
#free memory first of all
loadedmodels=model_management.current_loaded_models
unloaded_model = False
for i in range(len(loadedmodels) -1, -1, -1):
m = loadedmodels.pop(i)
m.model_unload()
del m
unloaded_model = True
if unloaded_model:
model_management.soft_empty_cache()
#print(model_management.current_loaded_models)
#loadedmodel = model_management.LoadedModel()
#loadedmodel.model_unload(self, current_loaded_models)
#transform backslashes into slashes for user convenience.
train_data_dir = data_path.replace( "\\", "/")
#ADVANCED parameters initialization
is_v2_model=0
network_moduke="networks.lora"
network_dim=32
network_alpha=32
resolution = "512,512"
keep_tokens = 0
min_snr_gamma = 0
unet_lr = "1e-4"
text_encoder_lr = "1e-5"
lr_scheduler = "cosine_with_restarts"
lr_restart_cycles = 0
#optimizer_type = "AdamW8bit"
algo= "lora"
dropout = 0.0
if v2 == "Yes":
is_v2_model = 1
network_module = networkmodule
network_dim = networkdimension
network_alpha = networkalpha
resolution = f"{trainingresolution},{trainingresolution}"
formatted_value = str(format(learningrateText, "e")).rstrip('0').rstrip()
text_encoder_lr = ''.join(c for c in formatted_value if not (c == '0'))
formatted_value2 = str(format(learningrateUnet, "e")).rstrip('0').rstrip()
unet_lr = ''.join(c for c in formatted_value2 if not (c == '0'))
keep_tokens = keeptokens
min_snr_gamma = minSNRgamma
lr_scheduler = learningRateScheduler
lr_restart_cycles = lrRestartCycles
optimizer_type = optimizerType
algo = algorithm
dropout = f"{networkDropout}"
#generates a random seed
theseed = random.randint(0, 2^32-1)
if multi_gpu:
launch_args.append("--multi_gpu")
if lowram:
ext_args.append("--lowram")
if is_v2_model:
ext_args.append("--v2")
else:
ext_args.append(f"--clip_skip={clip_skip}")
if parameterization:
ext_args.append("--v_parameterization")
if train_unet_only:
ext_args.append("--network_train_unet_only")
if train_text_encoder_only:
ext_args.append("--network_train_text_encoder_only")
if network_weights:
ext_args.append(f"--network_weights={network_weights}")
if reg_data_dir:
ext_args.append(f"--reg_data_dir={reg_data_dir}")
if optimizer_type:
ext_args.append(f"--optimizer_type={optimizer_type}")
if optimizer_type == "DAdaptation":
ext_args.append("--optimizer_args")
ext_args.append("decouple=True")
if network_module == "lycoris.kohya":
ext_args.extend([
f"--network_args",
f"conv_dim={conv_dim}",
f"conv_alpha={conv_alpha}",
f"algo={algo}",
f"dropout={dropout}"
])
if noise_offset != 0:
ext_args.append(f"--noise_offset={noise_offset}")
if stop_text_encoder_training != 0:
ext_args.append(f"--stop_text_encoder_training={stop_text_encoder_training}")
if save_state == 1:
ext_args.append("--save_state")
if resume:
ext_args.append(f"--resume={resume}")
if min_snr_gamma != 0:
ext_args.append(f"--min_snr_gamma={min_snr_gamma}")
if persistent_data_loader_workers:
ext_args.append("--persistent_data_loader_workers")
if use_wandb == 1:
ext_args.append("--log_with=all")
if wandb_api_key:
ext_args.append(f"--wandb_api_key={wandb_api_key}")
if log_tracker_name:
ext_args.append(f"--log_tracker_name={log_tracker_name}")
else:
ext_args.append("--log_with=tensorboard")
launchargs=' '.join(launch_args)
extargs=' '.join(ext_args)
pretrained_model = folder_paths.get_full_path("checkpoints", ckpt_name)
#Looking for the training script.
progpath = os.getcwd()
nodespath=''
#auto sdxl
if not is_sdxl:
for dirpath, dirnames, filenames in os.walk(progpath):
if 'sd-scripts' in dirnames:
nodespath= dirpath + '/sd-scripts/train_network.py'
print(nodespath)
else:
for dirpath, dirnames, filenames in os.walk(progpath):
if 'sd-scripts' in dirnames:
nodespath= dirpath + '/sd-scripts/sdxl_train_network.py'
print(nodespath)
nodespath = nodespath.replace( "\\", "/")
command = "python -m accelerate.commands.launch " + launchargs + f'--num_cpu_threads_per_process=8 "{nodespath}" --enable_bucket --pretrained_model_name_or_path={pretrained_model} --train_data_dir="{train_data_dir}" --output_dir="{output_dir}" --logging_dir="./logs" --log_prefix={output_name} --resolution={resolution} --network_module={network_module} --max_train_epochs={max_train_epoches} --learning_rate={lr} --unet_lr={unet_lr} --text_encoder_lr={text_encoder_lr} --lr_scheduler={lr_scheduler} --lr_warmup_steps={lr_warmup_steps} --lr_scheduler_num_cycles={lr_restart_cycles} --network_dim={network_dim} --network_alpha={network_alpha} --output_name={output_name} --train_batch_size={batch_size} --save_every_n_epochs={save_every_n_epochs} --mixed_precision="fp16" --save_precision="fp16" --seed={theseed} --cache_latents --prior_loss_weight=1 --max_token_length=225 --caption_extension=".txt" --save_model_as={save_model_as} --min_bucket_reso={min_bucket_reso} --max_bucket_reso={max_bucket_reso} --keep_tokens={keep_tokens} --xformers --shuffle_caption ' + extargs
#print(command)
subprocess.run(command, shell=True)
print("Train finished")
#input()
return ()
以上99%代码来自LarryJane491的Lora-Training-in-Comfy,我是抄作业的,Python不是我强项。
最后节点图凑一下
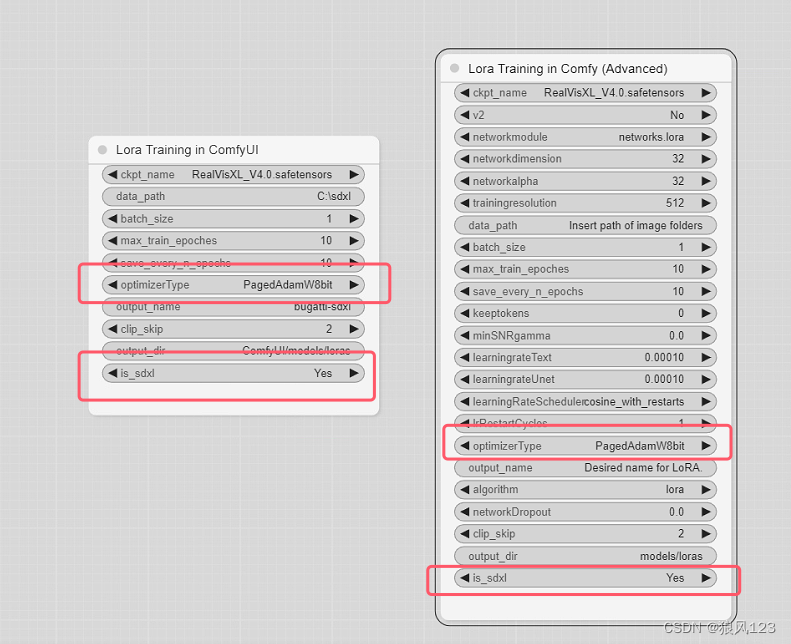
有些本来已经调用了Lora Rraining in ComfyUI这个节点的,需要删掉重新创建,不然就配置对不上。另外Lora Rraining in ComfyUI节点还要加一个resolution的参数,不然默认就是512,完全不属于lora-sdxl的菜,修改方式很简单,不想重复灌水了。
打完收工,呼~~
















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









