







定义模型
from django.db import models
class User(models.Model):
# 类属性是表示表的字段
username = models.CharField(max_length=50,unique=True)
password = models.CharField(max_length=200)
create_time = models.DateTimeField(auto_now_add=True) # auto_now_add新增数据时间为系统当前时间,且后续操作该条数据时,此字段值不会更新
update_time = models.DateTimeField(auto_now=True) #auto_now新增数据时间为系统当前时间,且后续操作该条数据时,此字段值会更新为系统当前时间
money=models.DecimalField(max_digits=16,decimal_places=2,null=True)
flag = models.BooleanField(False)
class Meta:
db_table="tb_users" # 定义表明
ordering=["-create_time"] # 排序
激活模型
# 生成迁移文件
python manage.py makemigrations
# 迁移
python manage.py migrate
# 已经建好数据库,需要将数据库反向到项目中的models.py模块中生成模型类
python manage.py inspectdb > app/models.py
使用模型
增加数据
user = User(username="fds",password=MD5(b"1213").hexdigest())
user.save()
# 使用create增加删除,不需要save()方法
uses={"username":"ff","password":"123456"}
User.objects.create(**uses)
# 一次创建多条数据
User.objects.bulk_create([User(username="fdfd"),User(username="dfs")])
修改数据
user = User.objects.get(pk=1)
user.username="测试人员"
user.save()
删除数据
# 删除一条数据
user = User.objects.get(pk=1)
if user:
user.delete()
# 根据条件过滤删除多条数据
user = User.objects.filter(pk__gte=3)
if user:
user.delete()
# 逻辑删除,将表中某个字段的值置为false
user = User.objects.get(pk=1)
if user:
user.flag=True # 将该状态设置为true,表示无效
user.save()
查询数据
从数据库查询数据,首先会获取到一个查询集queryset
| 管理器的方法 | 返回类型 | 说明 |
|---|---|---|
| 模型类.objects.all() | QuerySet | 返回列表中所有的数据 |
| 模型类.objects.filter() | QuerySet | 返回列表中符合条件的数据 |
| 模型类.objects.exclude() | QuerySet | 返回不符合条件的数据 |
| 模型类.objects.order_by() | QuerySet | 对查询结果集进行排序 |
| 模型类.objects.values() | QuerySet | 返回的每一个对象为一个字典 |
| 模型类.objects.get() | 模型对象 | 如果找不到数据会报错,找到多条也会报错 |
| 模型类.objects.first() | 模型对象 | 返回第一条数据 |
| 模型类.objects.last() | 模型对象 | 返回最后数据 |
| 模型类.objects.exist() | bool | 判断查询到数据是否存在 |
| 模型类.objects.last() | int | 返回查询集中对象的数目 |
查询结果返回查询集
查询结果集可以再次进行链式过滤,再查询结果集的基础上进行filter等操作
- all()
user = User.objects.all()
# 返回结果,返回所有的数据
<QuerySet [<User: User object (4)>, <User: User object (3)>, <User: User object (2)>]>
- filter()
user = User.objects.filter(pk__gte=1) # filter对应sql中的where语句
# 返回结果,返回pk大于等于1 的数据
<QuerySet [<User: User object (4)>, <User: User object (3)>, <User: User object (2)>]>
# 链式查询
user = User.objects.filter(pk__gte=1).filter(username="fff")
# 返回结果
<QuerySet [<User: User object (4)>]>
- order_by()
# 根据创建时间倒序排序
user = User.objects.order_by("-create_time")
# 按照create_time升序排列
user = User.objects.order_by("create_time")
- values()
# 不指定字段查询
user = User.objects.values()
# 返回结果
<QuerySet [{'id': 4, 'create_time': datetime.datetime(2023, 8, 20, 2, 2, 59, 302973, tzinfo=datetime.timezone.utc), 'update_time': datetime.datetime(202
3, 8, 20, 2, 2, 59, 302973, tzinfo=datetime.timezone.utc), 'username': 'shasha', 'password': '123456', 'money': None, 'flag': False}, {'id': 3, 'create_
time': datetime.datetime(2023, 8, 20, 2, 2, 50, 699239, tzinfo=datetime.timezone.utc), 'update_time': datetime.datetime(2023, 8, 20, 2, 2, 50, 699239, t
zinfo=datetime.timezone.utc), 'username': 'ff', 'password': '123456', 'money': None, 'flag': False}, {'id': 2, 'create_time': datetime.datetime(2023, 8,
20, 1, 51, 8, 322158, tzinfo=datetime.timezone.utc), 'update_time': datetime.datetime(2023, 8, 20, 1, 56, 20, 989425, tzinfo=datetime.timezone.utc), 'u
sername': 'fsdf', 'password': '1111111', 'money': None, 'flag': False}]>
# 指定字段查询
user = User.objects.values("username")
# 返回结果
<QuerySet [{'username': 'shasha'}, {'username': 'ff'}, {'username': 'fsdf'}]>
查询结果返回对象
查询结果后面不能跟all()、filter()等字段进行过滤
- first()
user = User.objects.first()
# 返回结果
User object (4)
去重
# 使用distinct关键字去重
User.objects.all().values("password").distinct()
查询条数
查询记录数,查询结果集必须是queryset才能调用count()
User.objects.all().count()
判断结果是否为空
# 查询所有数据
User.objects.all().exists()
# 根据条件筛选出数据后判断数据是否为空
User.objects.filter(pk__lt=1).exists()
字段查询&运算符
属性名称__关系运算符=值
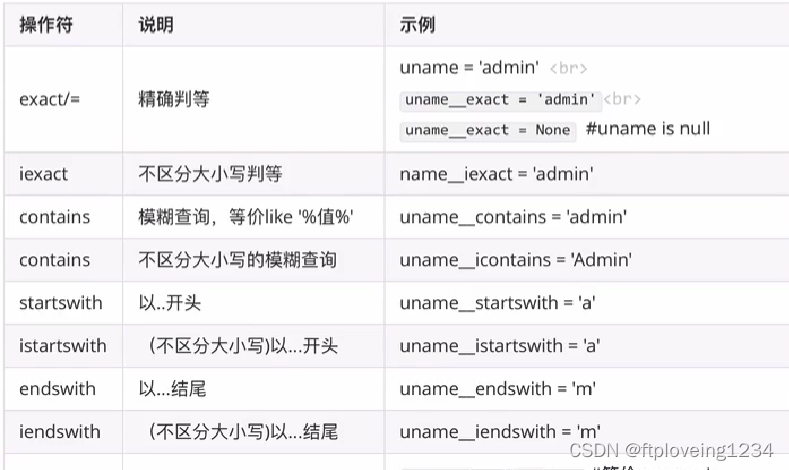
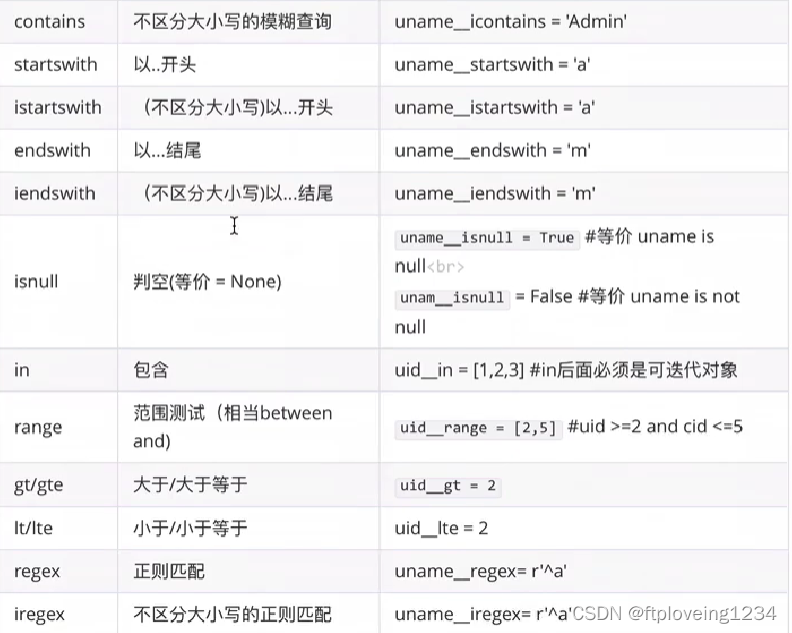
判断某个字段的值是否为空
# 查询money为空的结果
User.objects.filter(money__isnull=True)
# 返回结果
<QuerySet [<User: User object (4)>]>
精确判等
User.objects.filter(money__exact="100")
模糊查询
User.objects.filter(username__contains="h")
查询在区间范围内的数据
User.objects.filter(money_range=[90,200])
日期查询
# 查询年份
User.objects.filter(create_time__year=2023)
统计查询
使用aggregate方法进行聚合查询,不分组统计查询数据
- Max
# 查询到id的最大值
User.objects.aggregate(Max('pk'))
使用annotate方法进行分组统计查询数据
原生sql
User.objects.raw("select * from tb_users ")
# 返回结果
<RawQuerySet: select * from tb_users >
模型关系
一对一
外键设置在哪一方都可以,通过OneToOneField关键字设置关联关系
一对多
一般是将主表中的主键放到从表中做外键,外键一般是一对多中多的一方设置,通过ForeignKey关键字设置
class BookModel(models.Model):
# 主表
name =models.CharField(max_length=50,verbose_name="书名")
price=models.IntegerField(verbose_name="价格")
pub_date = models.DateField(verbose_name="时间")
# 从主表查询从表的名字是通过related_name取的
pub=models.ForeignKey('Publish',on_delete=models.CASCADE,related_name="books",null=True)
class Publish(models.Model):
# 从表
name=models.CharField(max_length=100)
从表操作主表,是通过在从表定义的外键进行操作的,对主表进行增删改查
# 修改从表中外键的值
book = BookModel.objects.get(pk=2)
pub1 = Publish.objects.get(pk=1)
book.pub=pub1 # 修改从表中外键的值,且外键的值pub1必须是一个对象
book.save()
通过主表操作从表,利用在从表中定义的related_name的值操作从表,对从表进行增删改查
# 通过主表操作从表,给从表新增数据
# 通过出版社操作图书
pub = Publish.objects.get(pk=2)
# 给pk=2增加几本书
pub.books.create(name="fds11",price=22,pub_date='2023-09-01')
# 通过主表操作从表,更新从表中的数据
# 通过出版社操作图书
pub = Publish.objects.get(pk=2)
# 给pk=2增加几本书
pub.books.update(name="娃哈哈",price=22,pub_date='2023-09-01')
book = BookModel.objects.get(pk=2)
print(book.pub) # Publish object (1)
# book.pub是Publish的对象
# 通过主表查询从表
pub = Publish.objects.get(pk=2)
# pub-books是一个查询管理器对象
book = pub.books.all()
# 以从表字段作为过滤条件,查询主表中的数据
pub = Publish.objects.filter(books__name="娃哈哈")
# 返回查询结果
<QuerySet [<Publish: Publish object (2)>, <Publish: Publish object (2)>]>
多对多
通过ManyToManyField关键字设置多对多关系(商品和客户间的关系是多对多的关系)
注:一般要手动创建第三张表用来关联多对多的两张表
class Buyer(models.Model):
name = models.CharField(max_length=50)
leve = models.IntegerField(default=1)
class Meta:
db_table = "tb_buyer"
class Goods():
name = models.CharField(max_length=50, verbose_name="名")
price = models.IntegerField(verbose_name="价格")
class Meta:
db_table = "tb_goods"
# 多对多的关联的第三张表
class Order():
buyer = models.ForeignKey("Buyer",on_delete=models.CASCADE)
goods = models.ForeignKey("Goods", on_delete=models.CASCADE)
num = models.IntegerField(default=1)
class Meta:
db_table="tb_order"














 1987
1987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









