






言出法随,你想要的图片ChatGPT都有

有哪些更新
先看OpenAI的CEO山姆·奥特曼怎么说
今天我们发布一项新功能——ChatGPT支持图片生成!
这是一项令人惊叹的技术/产品。还记得第一次看到这个模型生成的图片时,我甚至难以相信它们真的由AI创作。我们相信用户会喜欢它,也期待见证由此激发的创造力。
这标志着我们在支持创作自由方面的新高度。人们将用它创作出惊艳的作品,也可能生成一些冒犯性内容;我们的目标是确保工具默认不产生冒犯性内容,但若用户明确需求(在合理范围内),它也能实现。如《模型规范》所述,我们认为将这种智力自由与控制权交给用户是正确的选择,同时会持续观察社会反馈···
那么更新后的ChatGPT到底可以做什么,我们一起围观一下
恶搞山姆·奥特曼-参考合成


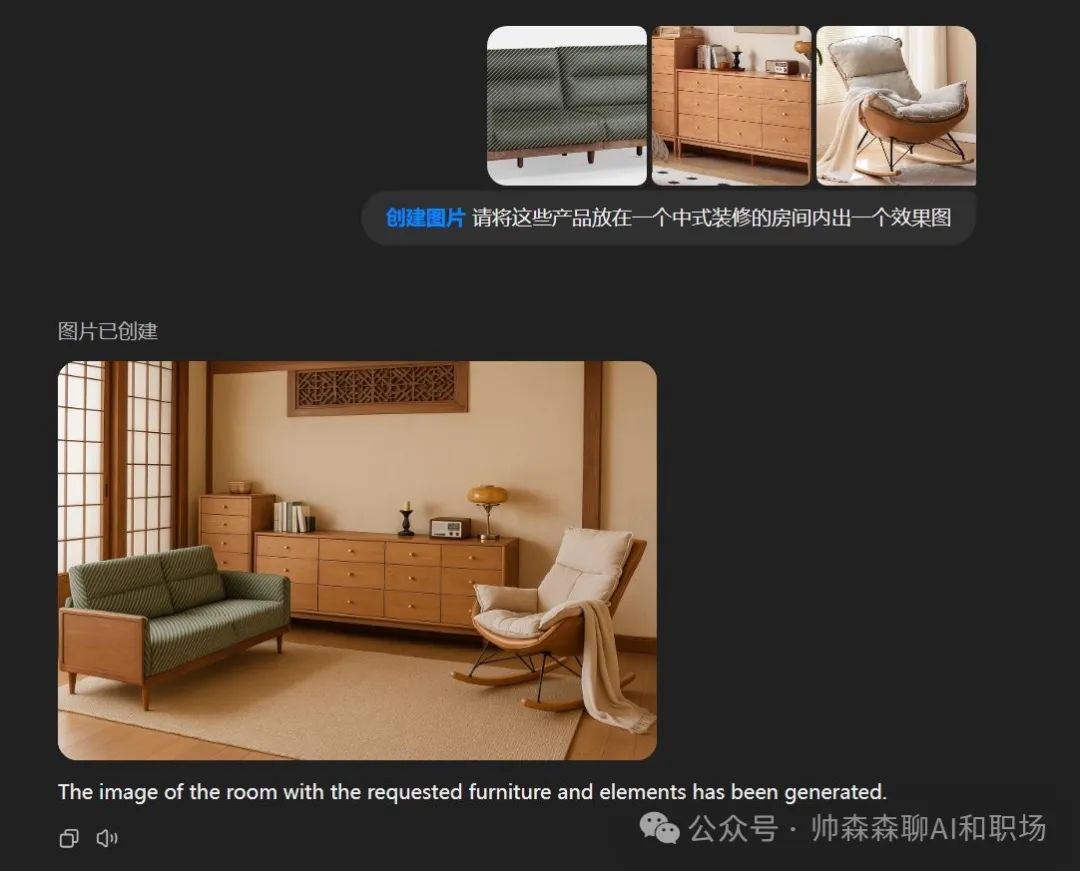
电商人的福音
从商家端: 只需要拍实物图, 一句话打造各种场景的效果图;
从用户端: 可以选个各种家具让他组合搭配看效果图

像素艺术


吉卜力风格
川普名场面

原图

街拍

原图

参考生成系列
参考图

大脑宕机:脸上写着“404”,头顶冒烟

吃瓜群众:角色戴着墨镜,捧着一大碗瓜子

抓狂模式:头发炸毛、眼神暴走、旁边飘着“我裂开了!

在线emo:坐在角落,头顶小雨云

加班爆肝:黑眼圈+咖啡+电脑,旁边有“我还能肝!

哈哈哈哈哈哈哈
好的产品果然自带流量,官方已经限流啦

上面的图片,更喜欢哪个?
🔍:ai_service,持续分享一线的AI情报


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









