







本节接触了,C语言中的三大蛋疼:符号优先级 ++i顺序点 贪心法 (其实这里面好多都是跟编译器有关的,而且有好多问题都是可以通过良好的编程习惯避免的)
本节知识点:
1.注释问题:
注释不能把关键字弄断,如:in/*注释*/t
注释不是简单的剔除,而是使用空格替换
编译器认为双引号括起来的内容都是字符串,双斜杠也不例外。如:char *p = "heh//jfeafe" //不起注释作用
2.接续符:
接续符\ ,常用于宏定义中
- #define SWAP(a,b) \
- { \
- int temp = a; \
- a = b; \
- b = temp; \
- }
反斜杠同时有接续符和转义符两个用途,当接续符使用的时候,可以直接在程序中出现。当转义符使用的时候,必须是出现在字符串中。
接续符,也用与接续一个关键字,代码如下, 注意: 但是直接连接\两边不能有空格。
- #include <stdio.h>
- #include <stdlib.h>
- int main()
- {
- cha\
- r a = 12;
- return 0;
- }
3.逻辑运算符:有一个短路规则
4.最容易忘记规则的两个运算符:
三目运算符:(a?b:c) 当a的值为真的时候 返回b的值,否则返回c的值
逗号表达式:a,b 表达式的值为b的值
5.位运算:
对于左移和右移<< >>问题 :无符号的,和有符号左移,都是补0 ,对于有符号的在右移动的时候,正数补零,负数补什么跟编译器有关系。并且左移和右移的大小不能大于数据的长度,也不能小于0。
交换两个数,有一种不借助中间变量的方法,就是异或,代码如下:
- #include <stdio.h>
- #define SWAP1(a,b) \
- { \
- int temp = a; \
- a = b; \
- b = temp; \
- }
- #define SWAP2(a,b) \
- { \
- a = a + b; \
- b = a - b; \
- a = a - b; \
- }
- #define SWAP3(a,b) \
- { \
- a = a ^ b; \
- b = a ^ b; \
- a = a ^ b; \
- }
- int main()
- {
- int a = 1;
- int b = 2;
- SWAP1(a,b);
- SWAP2(a,b);
- SWAP3(a,b);
- return 0;
- }
6.i++,i--顺序点:
只有 i++ i--才有顺序点 就是什么时候开始加,什么时候开始减。真心对于顺序点 是搞不懂啊~~~ (++i)+(++i)+(++i) ,在gcc中是5+5+6(DEV C++) ,在vc中是6+6+6(vc++6.0) ,不同编译器顺序点不一样。这个例子的顺序点 在; 前。
a=((++i),(++i),(++i)) 它的顺序点在每个逗号前面完成计算。我觉得特殊的顺序点 是可以通过合理的顺序布局来避免的。
7.贪心法:
每一个符号应该尽可能多的包含字符
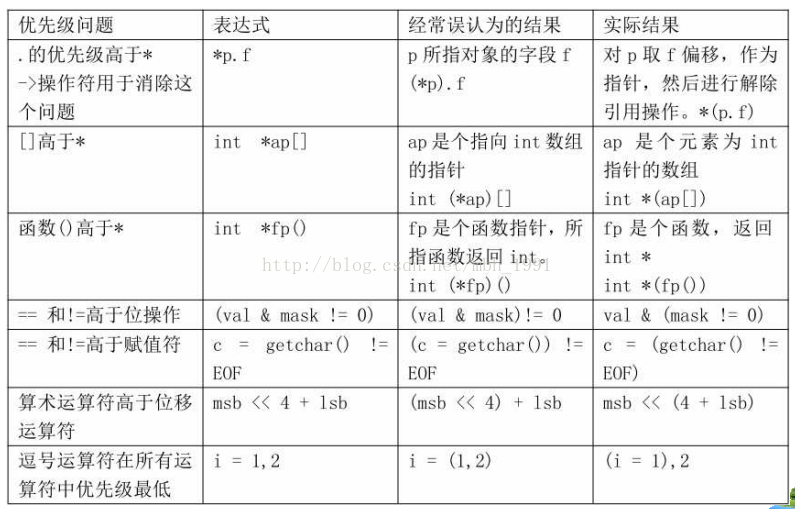
8.符号运算优先级问题:
个人觉得优先级不用记,好好的写括号吧~~~
给一个易错优先级表,如图:
9.c语言中的类型转换:
c语言中有两种转换类型,分别是:隐式转换和显示转换(强制类型转换)
隐式转换的规则:
a.算术运算中,低类型转换为高类型
b.赋值运算中,表达式的类型转换为左边变量的类型
c.函数调用时,实参转换成形参的类型
d.函数返回值,return表达式转换为返回值的类型

隐式转换的例子,代码如下:
- #include <stdio.h>
- int main()
- {
- int i = -2;
- unsigned int j = 1;
- if( (i + j) >= 0 )
- {
- printf("i+j>=0\n");
- }
- else
- {
- printf("i+j<0\n");
- }
- printf("i+j=%d\n", i + j);
- return 0;
- }
注意:在使用C语言的时候,应该特别注意数据的类型是否相同,尽量避免隐式转换带来的不必要的麻烦~~~















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









