






2024年4日24日,微软重磅发布Phi3,从基准测试上刻意与Llama3做了对比。感觉7b又吊打了Llama3的8b,甚至3.8b都比Llama3 8b好。这几天开源模型扎堆发布,业界卷的飞起。Meta开源Llama3,微软开源Phi3,阿里在Llama3之后开源Qwen 110B,也只能弱弱的说声"Not confident to say anything like competitive to Llama 3 70B but I hope you will find it at least not too bad. "。
Benchmark介绍
从微软的论文看来,基准测试一大堆,这些基准测试都是什么意思,今天简单给大家科普一下。
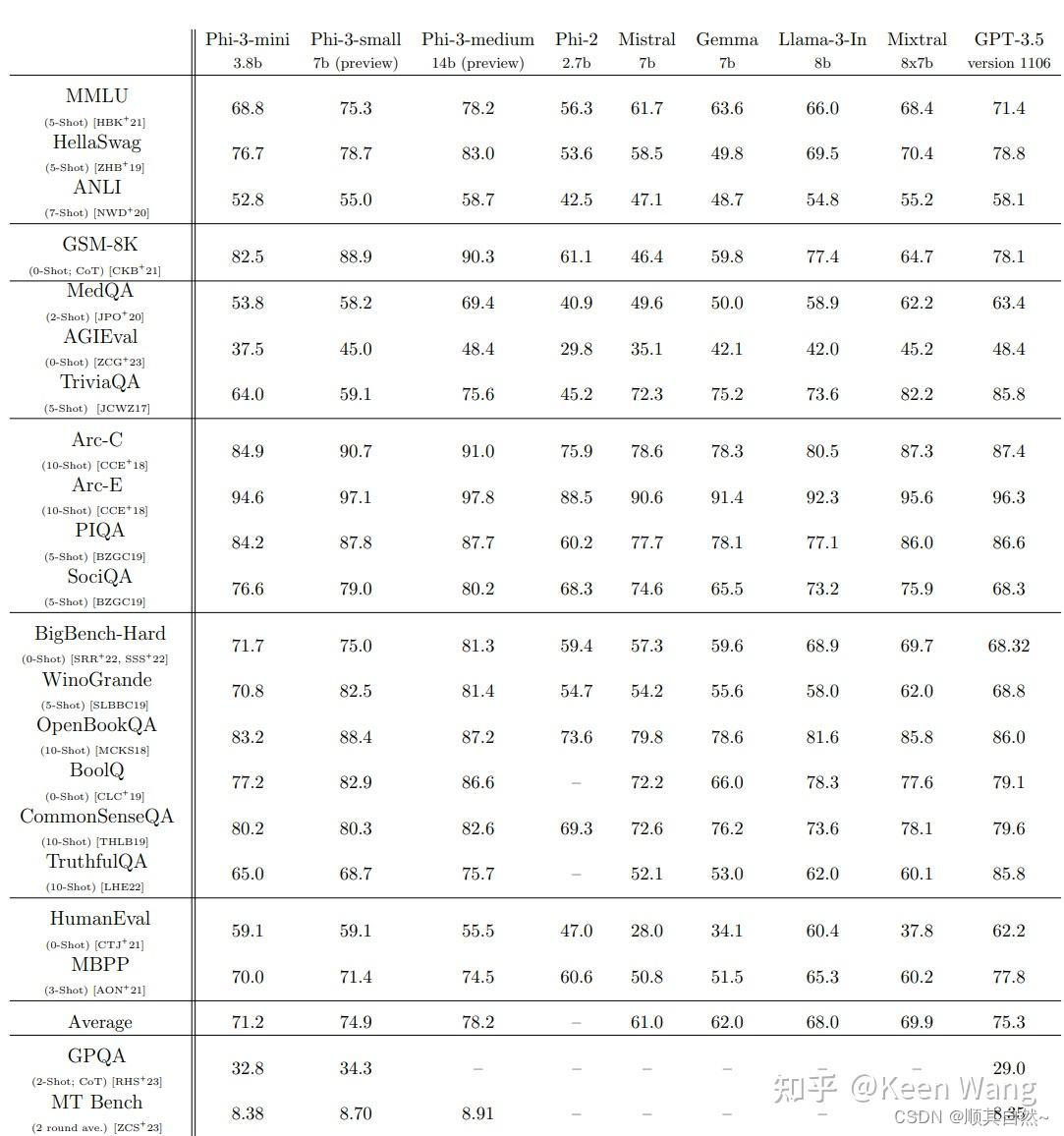
以上图从上往下的顺序介绍基准。
注:信息来源于以下几个网站
paperwithcode.com
huggingface.co
arXiv
mistral
http://qwenlm.github.io
Meta
Anthropic
MMLU
以类似评估人类的方式,通过零样本和少样本评估模型预训练期间获得的知识。涵盖了STEM、人文科学、社会科学等57个学科,同时测试世界知识和解决问题的能力。主题涵盖如数学和历史等传统领域,到如法律和伦理等更专业的领域。MMLU测试的目的是全面评估一个语言模型在处理多种类型语言理解问题时的能力。
- 提出时间:2020
- 论文链接:Measuring Massive Multitask Language Understanding
- 数据集链接:cais/mmlu
- 当前最高分(仅通用模型):90
- 最高分模型:Gemini Ultra(CoT + SC)
HellaSwag
HellaSwag是一个用于评估具有挑战的常识性自然语言推理(NLI)数据集,这些问题对人类来说非常简单(>95%的准确率),但对大语言模型来说很有挑战。这个数据集提出了一个场景描述,然后提供几个可能的结局,被测模型需选择最合适的结局。
- 提出时间:2019
- 论文链接:HellaSwag: Can a Machine Really Finish Your Sentence?
- 数据集链接:Rowan/hellaswag
- 当前最高分(仅通用模型):95.3
- 最高分模型:GPT-4 初始版本(10-shot)
ANLI
对抗性自然语言推理(ANLI)是一个新的大规模自然语言推理(NLI)基准数据集,旨在评估语言模型在对抗性环境下进行文本理解和推理的能力。
- 提出时间:2020
- 论文链接:Adversarial NLI: A New Benchmark for Natural Language Understanding
- 数据集链接:facebook/anli
- 当前最高分(仅通用模型):74.8
- 最高分模型:T5-3B
GSM-8K
GSM-8K(Grade School Math 8K)是一个用于评估和训练人工智能模型在解决基础数学问题方面能力的数据集。这个数据集包括约8000个来自小学和中学级别的数学问题,覆盖了算术、代数、几何、统计等多种数学领域。这些问题旨在模拟学生在实际学习环境中可能遇到的数学题目,其复杂度和类型能够全面测试模型的数学理解和解题能力。
- 提出时间:2021
- 论文链接:Training Verifiers to Solve Math Word Problems
- 数据集链接:gsm8k
- 当前最高分(仅通用模型):97
- 最高分模型:GPT-4 Code Interpreter(0-shot)
MedQA
基于美国医学执照考试(USMLE)的医学问答数据集。数据集是从专业医学委员会考试中收集的。涵盖了三种语言:英语、简体中文和繁体中文,分别包含了12723、34251和14123个问题。用于评估模型在理解医学领域知识和处理医学相关问题的能力。
- 提出时间:2023
- 论文链接:What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams
- 数据集链接:bigbio/med_qa
- 当前最高分(仅通用模型):90.2
- 最高分模型:GPT-4(Medprompt)
AGIEval
AGIEval是一个以人为中心的基准,专门用于评估模型在与人类认知和解决问题相关的任务中的能力。该基准来自20个官方、公共和高标准的入学和资格考试,例如普通大学入学考试(例如高考和美国SAT)、法学院入学考试、数学竞赛、律师资格考试和公务员考试。
- 提出时间:2023
- 论文链接:AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models
- 数据集链接:AGIEval
- 当前最高分(仅通用模型):49.93
- 最高分模型:Orca 2-13B
TriviaQA
TriviaQA是一个真实基于文本的问答数据集,包括从维基百科和网络上收集的662K文档中的95万问题-答案对。此数据集主要测试模型对广泛知识的掌握程度。
- 提出时间:2017
- 论文链接:TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
- 数据集链接:mandarjoshi/trivia_qa
- 当前最高分(仅通用模型):87.5
- 最高分模型:Claude 2(few-shot, k=5)
Arc-C/Arc-E
AI2的推理挑战(ARC)数据集是一个多项选择题回答数据集,包含了三年级到九年级的科学考试问题。数据集分为两个部分:简单部分(Arc-E)和难点部分(Arc-C),用于测试模型在科学推理方面能力的问题。ARC包含1430万KB的非结构化文本段落。
- 提出时间:2018
- 论文链接:Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
- 数据集链接:allenai/ai2_arc
- 当前最高分(Arc-C)(仅通用模型):96.4
- 最高分模型(Arc-C):GPT-4 初始版本(few-shot, k=25)
- 当前最高分(Arc-E)(仅通用模型):95.2
- 最高分模型(Arc-E):ST-MoE-32B 269B(fine-tuned)
PIQA
PIQA(Physical Interaction QA)是一个物理互动问答数据集,用于测试模型在预测物理世界中物体如何互动的能力。问题通常基于日常物理情境。
- 提出时间:2019
- 论文链接:PIQA: Reasoning about Physical Commonsense in Natural Language
- 数据集链接:piqa
- 当前最高分(仅通用模型):90.1
- 最高分模型:Unicorn 11B(fine-tuned)
SociQA
社会互动问答(Social Interaction QA,SIQA)是测试社会常识智力的问答基准。SIQA专注于推理人的行动及其社会影响。SIQA中的行为跨越了广泛的社会情境,答案候选既包含人工策划的答案,也包含对抗性过滤的机器生成的候选答案。Social IQa包含超过37,000个QA对,用于评估模型对日常事件和情况的社会含义的推理能力。
- 提出时间:2019
- 论文链接:SOCIAL IQA: Commonsense Reasoning about Social Interactions
- 数据集链接:social_i_qa
- 当前最高分(仅通用模型):83.2
- 最高分模型:Unicorn 11B(fine-tuned)
BigBench-Hard
BIG-Bench Hard (BBH)是BIG-Bench的一个子集,BIG-Bench是语言模型的一个多样化评估套件。BBH专注于一套来自BIG-Bench的23项具有挑战性的任务,用于评估语言模型在处理特别困难或复杂任务时的能力的数据集。
- 提出时间:2022
- 论文链接:Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
- 数据集链接:maveriq/bigbenchhard
- 当前最高分(仅通用模型):78.4
- 最高分模型:Flan-PaLM 540B(3-shot, fine-tuned, CoT + SC)
WinoGrande
WinoGrande是一个包含44k个问题的大规模数据集。受WSC数据库设计的启发,但经过调整以提高数据集的规模和难度。用于评估AI模型在解决含糊或不明确的参考问题上的能力。
- 提出时间:2019
- 论文链接:WinoGrande: An Adversarial Winograd Schema Challenge at Scale
- 数据集链接:winogrande
- 当前最高分(仅通用模型):96.1
- 最高分模型:ST-MoE-32B 269B(fine-tuned)
OpenBookQA
OpenBookQA是一个开放式问答数据集,用于评估人类对主题的理解。与问题相关的公开资料是1329个初级科学事实信息。用于测试模型利用给定的科学事实来解答相关问题的能力。
- 提出时间:2018
- 论文链接:Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
- 数据集链接:allenai/openbookqa
- 当前最高分(仅通用模型):95.9
- 最高分模型:GPT-4 + knowledge base
BoolQ
BoolQ 是一个布尔(是/否)问答数据集,包含自然语言问题,答案为简单的“是”或“否”。问题和答案都基于真实世界发生过的内容。
- 提出时间:2019
- 论文链接:BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
- 数据集链接:google/boolq
- 当前最高分(仅通用模型):92.4
- 最高分模型:ST-MoE-32B 269B(fine-tuned)
CommonSenseQA
CommonsenseQA是一个用于常识问答任务的数据集。数据集由12247个问题组成,每个问题有5个选择。用于评估模型在处理需要广泛常识的问题上的表现。
- 提出时间:2018
- 论文链接:CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
- 数据集链接:tau/commonsense_qa
- 当前最高分(仅通用模型):90.4
- 最高分模型:PaLM 2(few-shot, CoT + SC)
TruthfulQA
TruthfulQA是用于衡量语言模型在生成问题答案时是否真实的基准。有38个类别的817个问题,包括卫生、法律、金融和政治。作者精心设计了问题,如果有不真实的认知或误解则可能会回答错误。
- 提出时间:2022
- 论文链接:TruthfulQA: Measuring How Models Mimic Human Falsehoods
- 数据集链接:truthful_qa
- 当前最高分-True(仅通用模型):88.6
- 最高分模型-True:Vicuna 7B + Inference Time Intervention(ITI)
- 当前最高分-MC1 (Single-true)(仅通用模型):59
- 最高分模型-MC1 (Single-true):GPT-4 初始版本
HumanEval
HumanEval 是一个代码生成数据集,用于评估模型生成编程代码的能力,特别是在解决编程问题和实现特定功能方面。由164个原始编程问题组成,评估语言理解、算法和简单的数学,有一些可与简单的软件面试问题相媲美。
- 提出时间:2021
- 论文链接:Evaluating Large Language Models Trained on Code
- 数据集链接:openai_humaneval
- 当前最高分(仅通用模型):84.9
- 最高分模型:Claude 3 Opus(0-shot)注:排除掉Agent
MBPP
MBPP由大约1000个众包Python编程问题组成,可由入门级程序员解决,涵盖编程基础知识、标准库功能等。每个问题由一个任务描述、代码解决方案和3个自动化测试用例组成。用于测试模型的自动代码生成能力。
- 提出时间:2021
- 论文链接:Program Synthesis with Large Language Models
- 数据集链接:mbpp
- 当前最高分(仅通用模型):86.4
- 最高分模型:Claude 3 Opus 注:排除掉Agent
GPQA
GPQA是一个由448个多项选择题组成的具有挑战性的数据集,由生物、物理和化学领域专家撰写。确保问题高质量和高难度:在相应领域拥有或正在攻读博士学位的专家能达到65%的准确率(在考虑专家回顾发现的明确错误时,准确率为74%)。而高技能的非专家验证者,在平均花费30分钟,且不受限制地访问网络(即问题是“谷歌保证”),也仅能达到34%的准确率。
- 提出时间:2023
- 论文链接:GPQA: A Graduate-Level Google-Proof Q&A Benchmark
- 数据集链接:Idavidrein/gpqa
- 当前最高分:50.4? 注 仅查到 Claude 3的报告中这个数据最高
- 最高分模型:Claude 3 Opus
MT Bench
该数据集包含3.3K个专家级成对人类对6个模型在响应80个MT-bench问题时产生的模型响应的偏好。这6种模型是GPT-4、GPT-3.5、Claud-v1、 Vicuna-13B、 Alpaca-13B, 和LLaMa-13b。标注者大多是在每个问题的主题领域具有专业知识的研究生。
- 提出时间:2023
- 论文链接:Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
- 数据集链接:lm-sys/fastchat
- 当前最高分:9.32
- 最高分模型:GPT-4-1106-preview
汇总
常用Benchmark
主流LLM测试用Benchmark
- MMLU
- HellaSwag
- ARC
- WinoGrande
- HumanEval
- DROP
- GSM-8k
The Claude 3 Model Family: Opus, Sonnet, Haiku采用:
- MMLU
- MATH
- GSM-8K
- HumanEval
- GPQA(Diamond)
- MGSM
- DROP
- BigBench-Hard
- ARC-C
- HellaSwag
- WinoGrande
- RACE-H
- APPS
- MBPP
Introducing Meta Llama 3: The most capable openly available LLM to date采用:
- MMLU
- AGIEval English
- GPQA
- HumanEval
- GSM-8K
- MATH
- DROP
- ARC-C
- BigBench-Hard
- ARC
- HellaSwag
- MMLU
- TruthfulQA
- WinoGrande
- GSM-8K
Mixtral of experts - A high quality Sparse Mixture-of-Experts.采用:
- MMLU
- HellaSwag
- WinoGrande
- PIQA
- ARC
- NQ
- TriviaQA
- HumanEval
- MBPP
- MATH
- GSM8K
- MMLU
- C-Eval
- GSM-8K
- MATH
- HumanEval
- MBPP
- BBH
- CMMLU
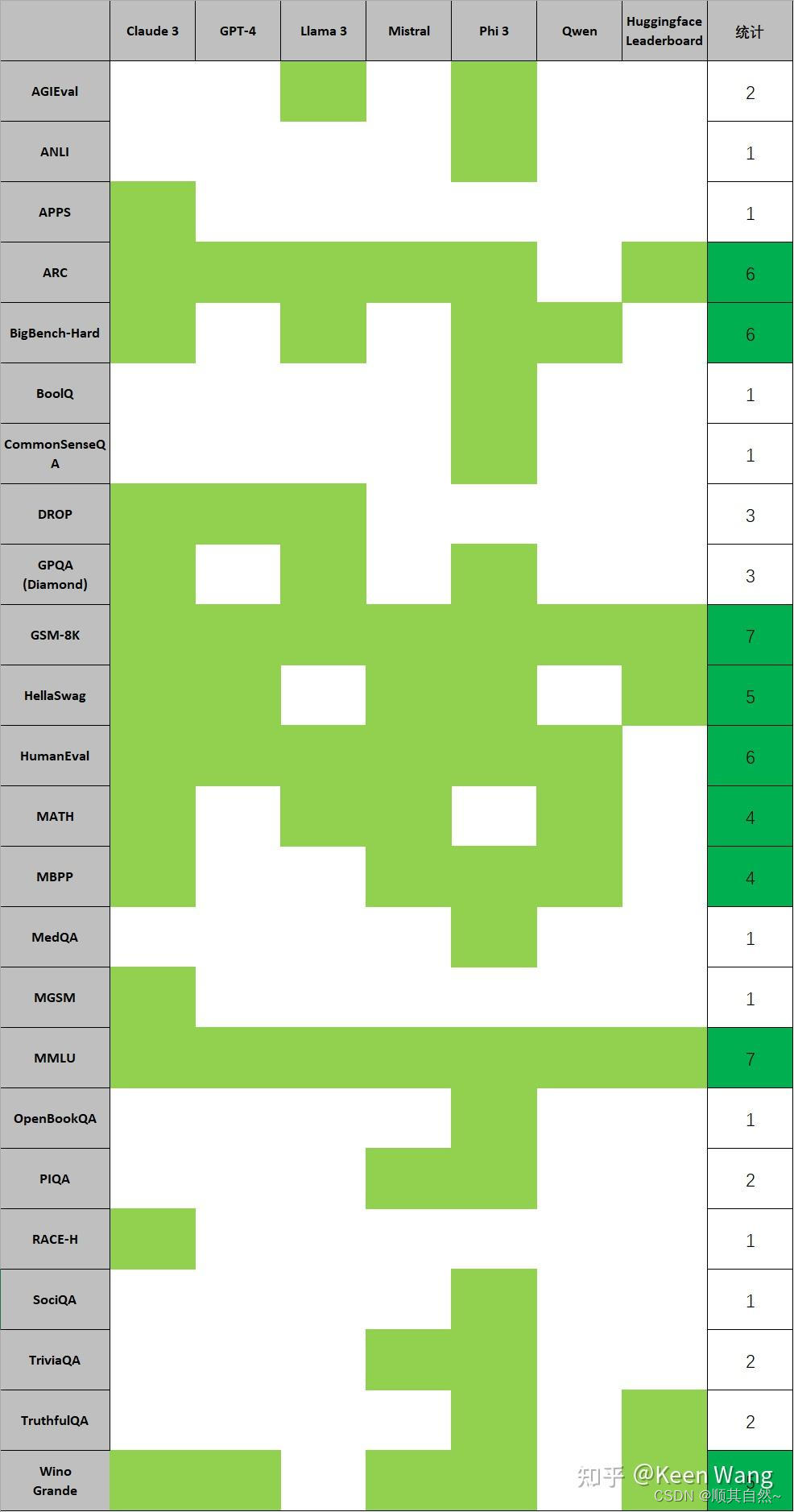
常用Benchmark统计
针对上面主流的一些LLM公开报告里的Benchmark统计,可得如下图,常用的Benchmark得票排名为如下。
| Benchmark | 得票 |
|---|---|
| GSM-8K | 7 |
| MMLU | 7 |
| ARC | 6 |
| BigBench-Hard | 6 |
| HumanEval | 6 |
| HellaSwag | 5 |
| WinoGrande | 5 |
| MATH | 4 |
| MBPP | 4 |
其中,GSM-8K和MMLU是必测项,ARC、BigBench-Hard、HumanEval基本都测。

















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









