






昇腾 910 与 310 基础芯片族,自下而上搭建庞大生态体系
1.1、昇腾 910AI 训练处理器+昇腾 310AI 推理处理器
华为从 2004 年开始投资研发第一颗嵌入式处理芯片,历经 15 年,投入超过 2 万 名工程师,形成了以“鲲鹏+昇腾”为核心的基础芯片族。此外,还有较为边缘的 SSD 控制芯片、智能网卡芯片、智能管理芯片等产品。 为适应 AI 运算的高性能要求,一般认为基础硬件具备至少 64 核、8 个内存通道、 PCIe 4.0、多合一 SoC、xPU 高速互联、100GE 高速 I/O 等六个特征。而支持 64 个核 心的鲲鹏 920 及芯片组能够满足以上要求。
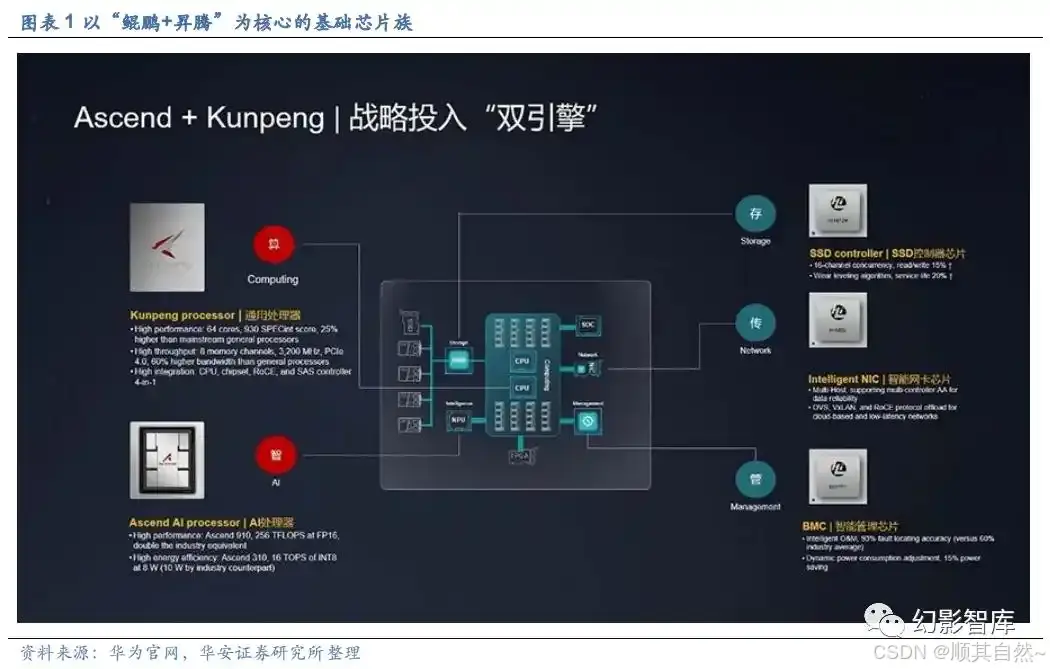
昇腾 310,高能效比推理型 AI 处理器,基于达芬奇架构,本质上是一块 SoC,集成了多个运算单元,包括 CPU(8 个 a55)、AI Core、数字视觉预处理子系统等。除了 CPU 之外,该芯片真正的算力担当是采用了达芬奇架构的 AI Core。这些 AI Core 通过特别设计的架构和电路实现了高通量、大算力和低功耗,特别适合处理深度学习中神经网络必须的常用计算。目前该芯片能对整型数(INT8、INT4) 或对浮点数(FP16)提 供强大的算力。根据海思官网披露,该芯片 FP16 算力为 8TOPS,INT8 算力 16TOPS, 采用 12nm 工艺制造。
昇腾 910,高性能训练 AI 处理器,性能接近英伟达 A100(40GB),半精度(FP16) 算力达到 320 TFLOPS,整数精度(INT8)算力达到 640 TOPS,功耗 310W,采用 7nm 先进工艺。此外,昇腾 910 集成了 HCCS、PCIe 4.0 和 RoCE v2 接口,为构建横向扩展 (Scale Out)和纵向扩展(Scale Up)系统提供了灵活高效的方法。HCCS 是华为自研的高速互联接口,片内 RoCE 可用于节点间直接互联。

1.2 开发者套件、加速卡、加速模块,完备的硬件生态
基于昇腾芯片族,华为开发了一系列加速卡产品: Atlas 300T 训练卡,基于昇腾 910 AI 芯片,芯片集成 32 个华为达芬奇 AI Core + 16 个 TaiShan 核,能够提供业界领先的 280 TFLOPS FP16 算力,并集成了一枚 100GE RoCE v2 网卡,支持 PCIe 4.0 和 1*100G RoCE 高速接口,出口总带宽 56.5 Gb/s,无需外置网卡,训练数据和梯度同步效率提升 10%-70%。内存规格方面,包括 32GB 的 HBM 和 16GB 的 DDR4。

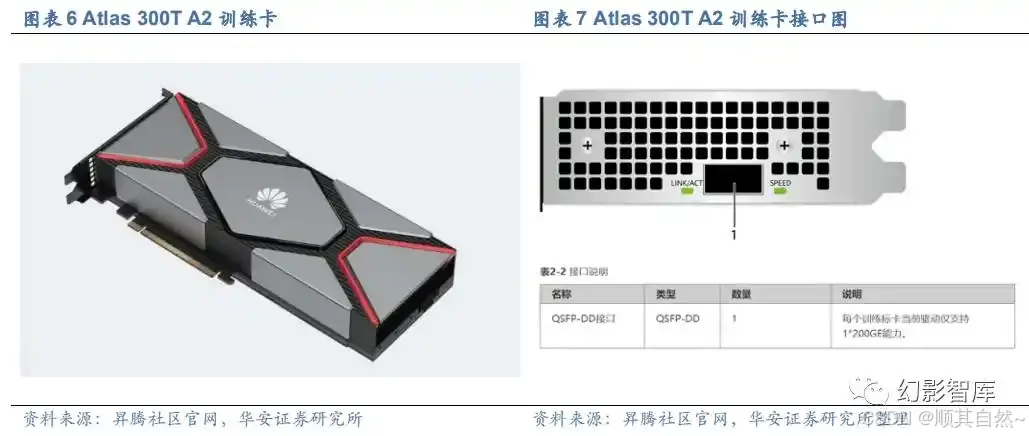
Atlas 300T A2 训练卡,强化了高速接口和对 PCIe5.0 的支持,集成 20 个 AI 核、8 个 CPU Core、1*200GE RoCE,提供 280 TFLOPS FP16 算力。
Atlas 300I Pro 推理卡,LPDDR4X 24 GB,总带宽 204.8 GB/s,融合“通用处理器、AI Core、编解码” 于一体,提供超强 AI 推理、目标检索等功能,具有超强算力、 超高能效、高性能特征检索、安全启动等优势,可广泛应用于 OCR 识别、语音分析、 搜索推荐、内容审核等诸多 AI 应用场景。单卡最大提供 140 TOPS INT8 算力,2 TOPS/W 超高能效比。

Atlas 300I Duo 推理卡,LPDDR4X 48GB,总带宽 408GB/s,从表观上看是两枚昇腾 310 的组合产品,从算力来看,单卡最大提供 280 TOPS INT8 算力,支持 16 core * 1.9 GHz CPU 计算能力,也约为单芯片的两倍。在此性能基础上,该产品支持 256 路高清视频实时分析。

Atlas 200I DK A2 开发者套件,是一款高性能的 AI 开发者套件,4 核 CPU,可提 供 8TOPS INT8 的计算能力,可以实现图像、视频等多种数据分析与推理计算,可广 泛用于教育、机器人、无人机等场景。以智能小车为例,Atlas 200I DK A2 借助图像处 理神经网络,实现图像识别,基于此实现自动驾驶控制。
Atlas 500 A2 智能小站是面向边缘应用的产品,具有环境适应性强、超强计算性 能、云边协同等特点,可以在边缘环境广泛部署,满足在交通、社区、园区、商场、超 市等复杂环境区域的应用需求。


1.3、服务器: arm 和 x86 兼容,风冷和液冷并用
Atlas 800 训练服务器(型号 9000)是基于华为鲲鹏 920+昇腾 910 处理器的 AI 训练服务器,实现完全自主可控,广泛应用于深度学习模型开发和 AI 训练服务场景。 该服务器面向公有云、互联网、运营商、政府、交通、金融、高校、电力等领域,具有高计算密度、高能效比、高网络带宽、易扩展、易管理等优点,支持单机和整机柜销售, 支持风冷和液冷应用,满足企业机房部署和大规模数据中心集群部署。 Atlas 800 训练服务器(型号 9010)则是基于华为昇腾 910+Intel V5 Cascade Lake 处理器的 AI 训练服务器,其基于更加成熟的 X86 结构。

Atlas 800 推理服务器 (型号:3000)最大可支持 8 个 Atlas 300I/V Pro,提供强 大的实时推理能力和视频分析能力,广泛应用于中心侧 AI 推理场景。Atlas 800 推理服 务器 (型号:3010)则是基于 Intel 处理器的推理服务器,最多可支持 7 个 Atlas 300I/V Pro,支持 896 路高清视频实时分析,广泛应用于中心侧 AI 推理场景。

集群方面,Atlas 900 PoD 集群基础单元搭载超 32 颗超强算力的鲲鹏 920 处理器, 47U 高度可最大提供 20.4 PFLOPS FP16 AI 算力,采用液冷散热,最大功耗为 46kw。 Atlas 900 AI 集群由数千颗昇腾训练处理器构成,通过华为集群通信库和作业调度平台,整合 HCCS、 PCIe 和 RoCE 三种高速接口,充分释放昇腾训练处理器的强大 性能。其总算力最大可拓展至 3.2 EFLOPS,全节点 200G 网络互联。这可以让研究人 员更快的进行图像、语音、自然语言等 AI 模型训练,更高效的进行科研探索,加速自 动驾驶的商用进程。
AI 生态并非只有 CUDA,各地算力集群建设 快速推进
2.1、AI 算力生态并非只有 CUDA
异构计算架构(CANN)是对标英伟达的 CUDA + CuDNN 的核心软件层,包括引擎、编译器、执行器、算子库等,承载计算机的单元为 AI 芯片,异构计算架构主要负责调度分配计算到对应的硬件上。从层级来看,CANN 上承 AI 框架,下接 AI 处理器硬件,先进的异构架构使得神经网络执行过程的硬件交互时间有效缩短,从而实现对硬件 性能的进一步利用。
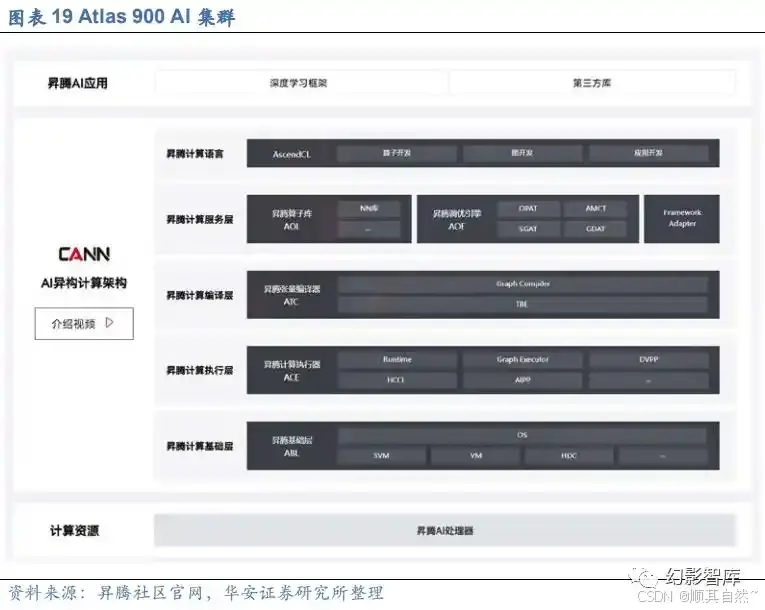
在 CANN 的基础之上,昇腾提供了昇思深度学习框架,旨在实现易开发、高效执 行、全场景覆盖三大目标。兼容性上,适配包括昇腾系列产品、英伟达 NVIDIA 系列产 品、Arm 系列的高通骁龙、华为麒麟的芯片等系列产品。其中,易开发表现为 API 友好、调试难度低;高效执行包括计算效率、数据预处 理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。

丰富的大模型库,目前已经收录「紫东.太初」、「武汉.Luojia」、「鹏程.盘古」、「鹏程.神农」、「空天·灵眸」等大模型,分别适用于多模态、遥感、中文自然语言、医学、 空天信息化等领域。
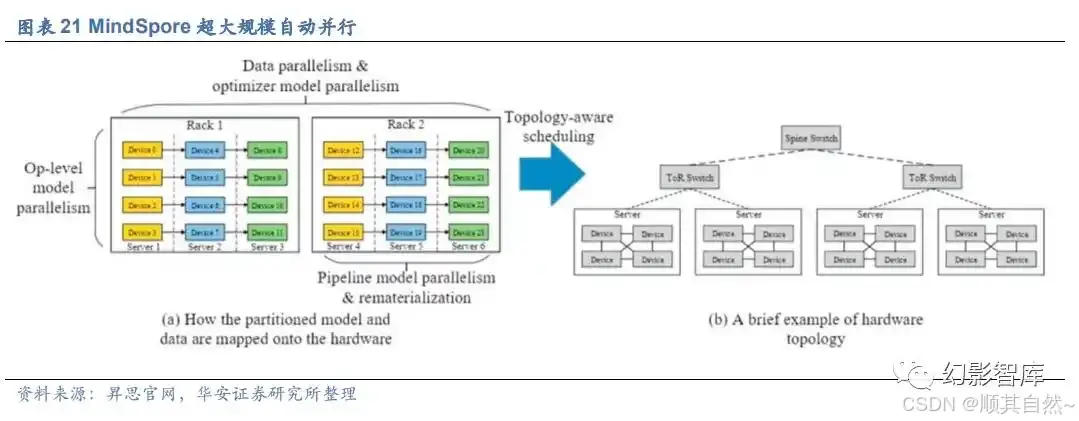
以「鹏程.盘古」为例,作为业界首个千亿级参数中文自然语言处理大模型,可支持知识问答、知识检索、知识推理、阅读理解等丰富的下游应用。该模型由鹏城实验室 为首的技术团队联合攻关,首次基于“鹏城云脑Ⅱ”和国产 MindSpore 框架的自动混 合并行模式实现在 2048 卡算力集群上的大规模分布式训练,训练出业界首个 2000 亿 参数以中文为核心的预训练生成语言模型。鹏程·盘古α预训练模型支持丰富的场景应 用,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出,具备很强 的小样本学习能力。
模型基于国产全栈式软硬件协同生态(MindSpore+CANN+昇腾 910+ModelArts)。
转自:百度安全验证

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









