






从网上拷贝了前辈的代码,然后执行如下:
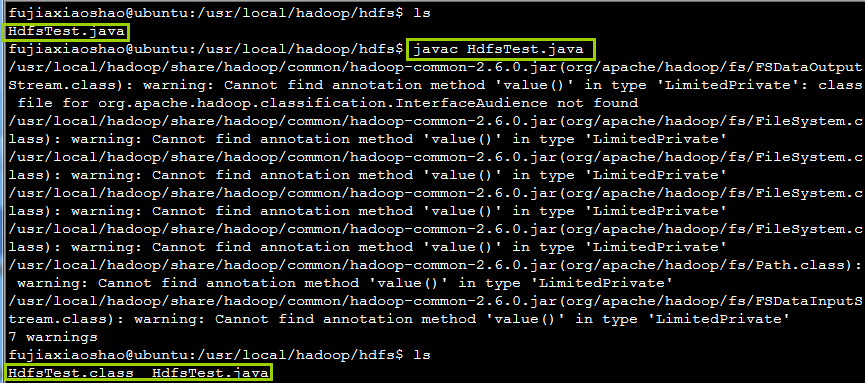
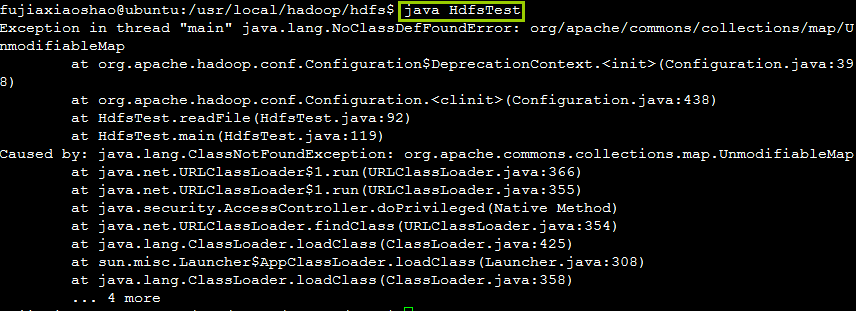
思路是在Hadoop的API包含在classpath中时边可以编译成功,然后使用java命令进行运行,结果总提示缺少jar包,于是从网上下载了缺失的jar包结果还会出现缺失另一个包如此往复。
经过学长的知道应该讲.class文件打包然后使用hadoop命令进行运行,和运行MR程序一样。则如下:


分析:可能的原因是只有hadoop命令可以调用Hadoop的某些jar
下边是代码,复制的网上前辈的,加了点注释:
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HdfsTest {
//创建新文件
public static void createFile(String dst , byte[] contents) throws IOException{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path dstPath = new Path(dst); //目标路径
//打开一个输出流
FSDataOutputStream outputStream = fs.create(dstPath);//创建文件的方法
outputStream.write(contents);//参数,二进制数组
outputStream.close();
fs.close();
System.out.println("文件创建成功!");
}
//上传本地文件
public static void uploadFile(String src,String dst) throws IOException{//一个参数是本地文件路径,另一个是fs路径
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path srcPath = new Path(src); //原路径,FileSystem也可以用读本机文件,因为本来Hadoop就支持很多文件系统
Path dstPath = new Path(dst); //目标路径
//调用文件系统的文件复制函数,前面参数是指是否删除原文件,true为删除,默认为false
fs.copyFromLocalFile(false,srcPath, dstPath);
//打印文件路径
System.out.println("Upload to "+conf.get("fs.default.name"));
System.out.println("------------list files------------"+"\n");
FileStatus [] fileStatus = fs.listStatus(dstPath);
for (FileStatus file : fileStatus)
{
System.out.println(file.getPath());
}
fs.close();
}
//文件重命名
public static void rename(String oldName,String newName) throws IOException{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path oldPath = new Path(oldName);//文件在Hadoop文件系统中视为Hadoop Path对象
Path newPath = new Path(newName);
boolean isok = fs.rename(oldPath, newPath);//重命名的方法
if(isok){
System.out.println("rename ok!");
}else{
System.out.println("rename failure");
}
fs.close();
}
//删除文件
public static void delete(String filePath) throws IOException{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path(filePath);
boolean isok = fs.deleteOnExit(path);//删除的方法
if(isok){
System.out.println("delete ok!");
}else{
System.out.println("delete failure");
}
fs.close();
}
//创建目录
public static void mkdir(String path) throws IOException{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path srcPath = new Path(path);
boolean isok = fs.mkdirs(srcPath);//在HDFS中直接是用mkdirs方法创建了一个文件夹,这个防范应该是org.apache.hadoop.fs.FileSystem对象有的方法
if(isok){
System.out.println("create dir ok!");
}else{
System.out.println("create dir failure");
}
fs.close();
}
//读取文件的内容
public static void readFile(String filePath) throws IOException{
Configuration conf = new Configuration();//封装了客户端或服务器配置,配置从conf/core-site.xml中读取
FileSystem fs = FileSystem.get(conf);//取得FileSystem实例即HDFS
Path srcPath = new Path(filePath);//这里的filePath是输入的文件路径。文件在Hadoop文件系统中视为Hadoop Path对象。
InputStream in = null;//文件输入流
try {
in = fs.open(srcPath);//open方法得到文件输入流,使用了默认的4kb缓冲器
IOUtils.copyBytes(in, System.out, 4096, false); //复制到标准输出流
} finally {
IOUtils.closeStream(in);//用来关闭数据流
}
}
public static void main(String[] args) throws IOException {
//测试上传文件
//uploadFile("D:\\c.txt", "/user/hadoop/test/");
//测试创建文件
/*byte[] contents = "hello world 世界你好\n".getBytes();
createFile("/user/hadoop/test1/d.txt",contents);*/
//测试重命名
//rename("/user/hadoop/test/d.txt", "/user/hadoop/test/dd.txt");
//测试删除文件
//delete("test/dd.txt"); //使用相对路径
//delete("test1"); //删除目录
//测试新建目录
//mkdir("test1");
//测试读取文件
readFile("test1/d.txt");
}
}FileSystem中的open方法返回的是一个FSDataInputStream。支持随机访问,即可以从流的任意位置读取
public class FSDataInputStream extends DataInputStream implements Seekable, PositionedReadable{
}
public FS DataoOutputStream append (Path f) throws IOException 这个方法用于追加数据但是不是所有的Hadoop文件系统都支持这个方法
只能从文件末尾写入。FileSystem中的creat()方法返回FSDataOutputStream,它也有一个查询文件当前位置的方法public long getPos() throws IOException{}
HDFS distcp命令,用于在Hadoop文件系统中并行地复制大数据量文件,这个复制过程会以MR程序执行
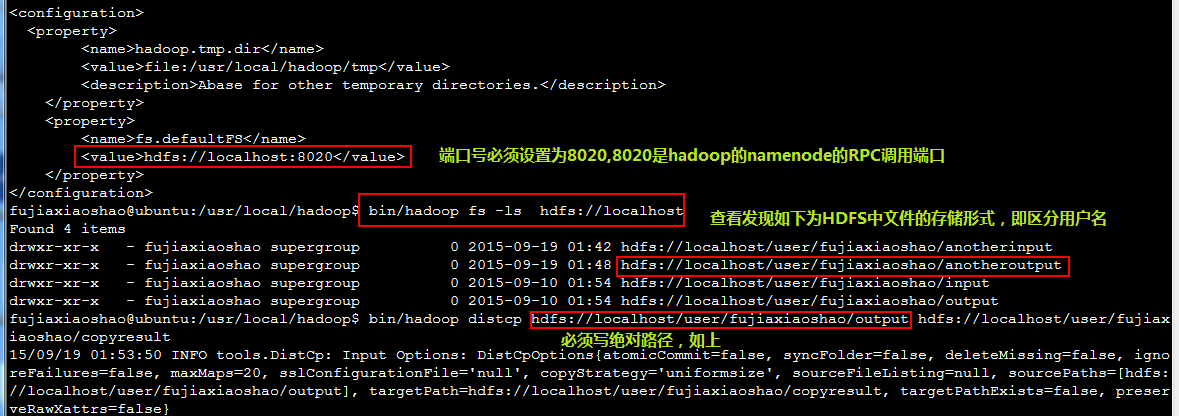
如上hdfs://后边是localhost而不是主机名,当改为主机名的时候,会出错,原因可能是,在fs.default的value值为localhost而不是主机名,然后在这个过程中也学到了/etc/hosts是ip和主机名对应的文件。而netstat –apn可以查看进程和端口使用情况。
点击打开链接这里是一个apache的帮助文档,看起来并不难。
点击打开链接这里是一个前辈对应hadoop的配置文件的一些梳理。
点击打开链接这里是对hadoop已经遗弃的属性名的总结。















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









