







Attention U-Net:Learning Where to Look for the Pancreas

Unet网络可以称得上是医学图像分割领域的开山之作,Attention U-Net是在Unet网络结构的基础上增加了attention 的机制,可以自动学习并聚焦到不同形状和大小的目标结构。这篇文章是发表在CVPR2018的一篇文章。
方法
作者提出了一种Attention Gate(AG)结构,Attention的意思是注意力机制,就是在复杂场景文字识别中,使用Attention把注意力集中在需要识别的数字上。
在医疗图像中,就是把注意力集中到对特定任务有用的显著特征(比如说相关组织或者是器官),抑制输入图像中的不相关区域。
在级联神经网络中,需要明确的外部组织/器官定位模块,而使用Attention就不需要了。把注意力放到目标区域上,简单来说就是让目标区域的值变大。
AG接在每个skip connection的末端,对提取的feature实现attention机制。结构如图:
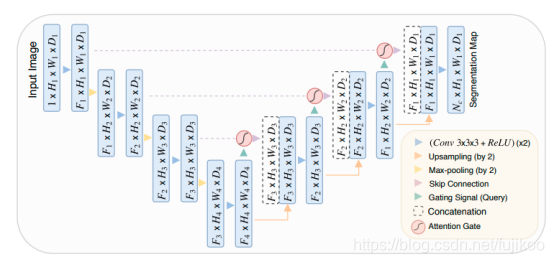
可以从上图看出:Attention-Unet和U-net的区别就在于decoder时,从encoder提取的部分进行了Attention Gate再进行decoder。
AG的原理如下图:
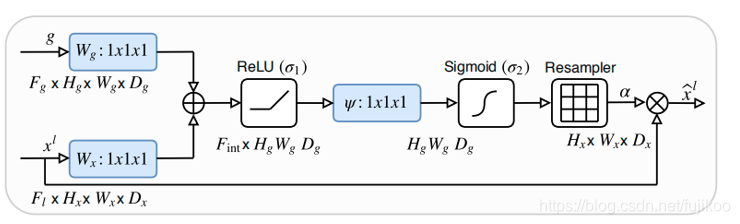
其中g为门控信号,xl为encoder对应的feature map,g来自于decoder的下一层,所以g尺寸大小是这一层的1/2。x完成Attention之后和g一起concat再进入下一层decoder。
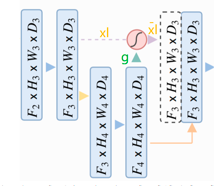
在上面这个图中,黄色的xl如果在unet中是要直接通过跳跃连接和绿色的g上采样的结果进行concat,但是在attention unet中先对xl和g转成一样的size,然后相加经过relu、sigmoid得到attention coefficients。
论文中作者说要结合上下文的信息,上文指的是encoder中的xl,下文指的是xl对应的decoder中的下一层,由于g更深,学到的东西更多,信息更准确。g里面含有的信息,可以当做注意力要去学习的方向。最后让xl与attention coefficients相乘,相乘就是把g里的信息叠加到xl,就能把注意力放到目标区域上了,再通过训练使得attention coefficients的让注意力更集中,让target区域的值趋近1,不相关的区域趋近0。
可以理解成如果直接将g上采样一次得到g’,g’和xl的size一样。那么同样是target的区域的像素值,g’里的像素值会比xl里的像素值大,和xl叠加,就相当于告诉了xl应该去学习的重点。
其他经典图像分割网络
FCN:
深度学习应用到图像分割始于FCN,与CNN相比,这个网络没有全链接层,全部都是卷积层。首先5层下采样,将原图缩小到原来的1/32,再上采样,放大到原来的大小得到分割结果。
Unet:
Unet总共5次下采样,每次下采样包括(两次卷积核为3* 3的卷积,ReLU激活和一次2* 2的max pooling),每次下采样会将feature map的通道数变为原来的两倍。
在上采样过程中,通过反卷积,将特征通道减少为原来的一半,长宽翻倍,并且这个上采样过程中对应的下采样也会被连接,(也就是图中的灰色箭头),连接操作必须保证图像的大小一致,所以要进行裁剪。网络最后用了1*1的卷积,作用:将特征通道数降至特定的数量,如:像素点的类别数.
效果

a-e和f-j分别是三维腹部CT扫描的轴位和矢状位视图在经过门前和经过门后的跳跃连接的特征激活图,可以明显看到经过ag之后的效果更好。

这是和unet网络的对比图,b为groundtruth,c是用unet分割的,可以单靠有些区域缺失了部分,d是用attention unet分割的,误差较小。
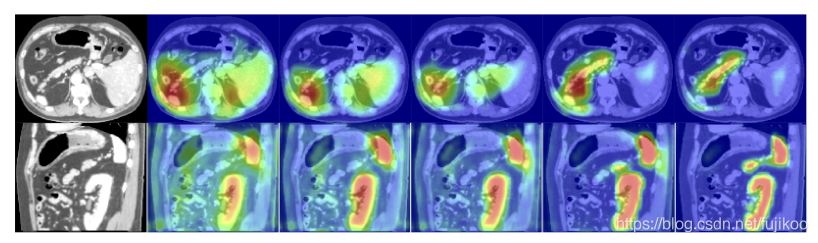
图中显示了不同训练epoch中(分别是3,6,10,60,150)的attention coefficients。图像是从测试数据集的三维腹部CT扫描的矢状面和轴向面提取的。该模型逐渐学会关注胰腺、肾脏和脾脏。
结论
这篇文章提出了一种新的用于医学图像分割的注意门模型。实验结果表明,这篇文章所提出的AGs是高度有益的组织/器官鉴定和定位。对于像胰腺这样大小不一的小器官来说,情况尤其如此,在分类任务中也会出现类似的情况。迁移学习和多阶段训练方案有利于AGs的训练行为。例如,预先训练的U-Net权值可以用来初始化注意力网络,在微调阶段可以相应地训练gates。Attention U-Net的性能可以通过使用精细分辨率输入批次而进一步提高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









