







快速搞定Kafka术语
Kafka 服务端
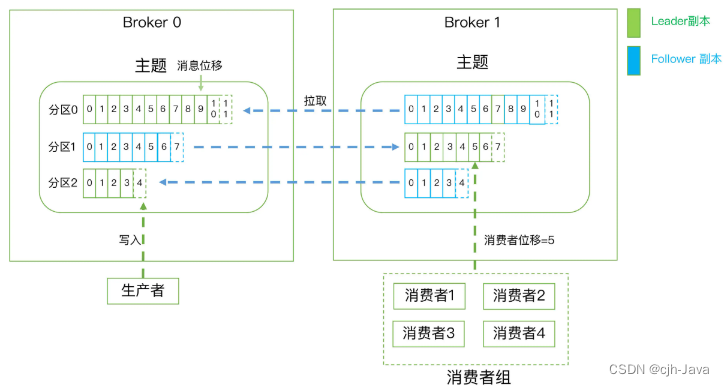
3层消息架构
- 第 1 层是主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。
- 第 2 层是分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
- 第 3 层是消息层,分区中包含若干条消息,消息位移:在分区中每条消息都有自己的位移,从 0 开始,依次递增。
客户端程序只能与分区的领导者副本进行交互。
Kafka 客户端
- 消费者组,指的是多个消费者实例共同组成一个组来消费一组主题。这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它。为什么要引入消费者组呢?主要是为了提升消费者端的吞吐量。多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)。
- 消费者位移,每个消费者在消费消息的过程中必然需要有个字段记录它当前消费到了分区的哪个位置上,这个字段就是消费者位移(Consumer Offset)。
要注意的是,消费者位移和上面的消息位移不是一个概念:
消息位移是不变的,表征的是分区内的消息位置,即一旦消息被成功写入到一个分区上,它的位移值就是固定的了。
消费者位是变化的,表征的是消费者消费进度,即消费者消费到了哪个分区的哪个位置上。每个消费者有着自己的消费者位移。 - 重平衡,消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance是Kafka消费者端实现高可用的重要手段。
Broker 如何持久化数据
- 保存:Kafka使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。
- 删除:通过日志段(Log Segment)机制。在Kafka底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
小结
代理:Broker。Broker 指 Kafka 的进程实例,多个 Broker 组成一个 Kafka 集群。目的是提高可用性
消息:Record。Kafka是消息引擎,这里的消息就是指Kafka处理的主要对象。
主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区,分区编号从0开始。可理解是:为了提高服务端扩展性,将 1 个主题拆成多个分区。
消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
副本:Replica。Kafka中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。可理解是:为了提高可用性,对每条消息进行冗余备份。
生产者:Producer。向主题发布新消息的应用程序。
消费者:Consumer。从主题订阅新消息的应用程序。
消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。可理解是:为了实现共同订阅,所以实现了多组。
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
图例:















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









