










kosaraju算法,三大强连通分量算法之一,最简单、最好理解的求解有向图强连通分量的方法,单纯的两次深搜,就可以划分我们的图。
算法流程:
1、从任意一个点开始深搜,得到图的一个最晚完成时间的排序;
2、求图的反图;
3、根据第1步得到的排序,从最晚完成的一个点开始搜索并染色;
4、第三步每一次深搜完成就是一个强连通分量。
我们先给出代码,大家先看看(代码来自NOCOW):
#include <iostream>
using namespace std;
const int MAXV = 1024;
int g[MAXV][MAXV], dfn[MAXV], num[MAXV], n, m, scc, cnt;
void dfs(int k)
{
num[k] = 1;
for(int i=1; i<=n; i++)
if(g[k][i] && !num[i])
dfs(i);
dfn[++cnt] = k; //记录第cnt个出栈的顶点为k
}
void ndfs(int k)
{
num[k] = scc; //本次DFS染色的点,都属于同一个scc,用num数组做记录
for(int i=1; i<=n; i++)
if(g[i][k] && !num[i]) //注意我们访问的原矩阵的对称矩阵
ndfs(i);
}
void kosaraju()
{
int i, j;
for(i=1; i<=n; i++) //DFS求得拓扑排序
if(!num[i])
dfs(i);
memset(num, 0, sizeof num);
/* 我们本需对原图的边反向,但由于我们使用邻接矩阵储存图,所以反向的图的邻接矩阵
即原图邻接矩阵的对角线对称矩阵,所以我们什么都不用做,只需访问对称矩阵即可*/
for(i=n; i>=1; i--)
if(!num[dfn[i]]){ //按照拓扑序进行第二次DFS
scc++;
ndfs(dfn[i]);
}
cout<<"Found: "<<scc<<endl;
}
int main()
{
int i, j;
cin>>n>>m;
for(i=1; i<=m; i++){
int x, y, z;
cin>>x>>y>>z;
g[x][y] = z;
}
kosaraju();
return 0;
}下面进行算法的具体分析。
算法思想:
其实这个算法是由两次搜索来完成的,一次搜索原图图,一次搜索反图(反图的意思就是把所有的边反过来,即graph[i][j] = graph[j][i])下面给个图:
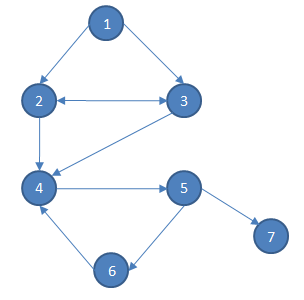
上图的反图为:
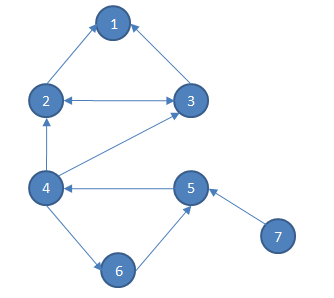
有了这两个图我们要干什么呢?答案是做两次深搜。
第一次深搜:
首先说明我们第一次深搜的目的——得到一个伪拓扑排序,这个拓扑排序是第二次深搜的准备,可以保证我们在第二次深搜的无条件染色过后轻易对原图进行分解。
这次搜索是对原图进行的,其实就是一个后序遍历。我们需要了解两个时间戳的概念——最早发现时间和最晚完成时间,我们可以参照算法导论给出几个符号表示:
对于U集合,有:
d_min{U}:最早发现时间;d_max{U}:最晚发现时间;
f_min{U}:最早完成时间;f_max{U}:最早完成时间 。
发现时间,指的是搜索开始的时间;完成时间,指的是搜索结束的时间。对于U集合,发现时间和完成时间的最值有四个(上面四个),指的是所有的点都符合的一个最值。
这几个时间有什么用呢?算法导论给出了一个引理:
引理22.14:设C和D为有向图G={ V , E }的两个不同的强连通分量。假如存在一条边( u , v )∈E,这里u∈C,v∈D,则f_max{C} > f_max{D} 。
这个引理的证明就不给出了,这里强调一下它说明了一件事——用任意的访问顺序搜索一个弱连通图,图里的强连通分量的最晚完成时间顺序一定。
我们就用上面的图来举例,很明显上图分为三个强连通分量——①{1,2,3}、②{4,5,6}和③{7}。假设分别1和4开始搜索:
于是有搜索顺序:
从1开始搜索:6,7,5,4,3,2,1
先搜5再搜1:4,6,7,5,3,2,1
我们可以发现,第一种的最晚完成时间排序是 ‘③ < ② < ①’,第二种也是 ‘③ < ② < ①’,符合引理的描述。这个搜索顺序的神奇之处即将揭晓。
第二次深搜:
第二次深搜,按排序进行无条件染色,即一次搜索找到的点属于一个强连通分量。这一次的搜索是在原图的反图上进行。
引理22.15:设C和D为有向图G={ V , E }的两个不同的强连通分量。假如存在一条边( v , u )∈E,这里u∈C,v∈D,则f_max{C} < f_max{D} 。
这个引理告诉我们,我们从排序的最后一个点开始搜索,一定不会找到别的连通分量的点。其实这个引理就是22.14的一种变形,它保证了kosaraju算法的正确运行!于是,我们知道了第一次深搜得到的排序的作用!
我们的算法完成了。
曾经的疑问:
1、为什么要用深度优先搜索树的后序遍历?前序遍历不可以吗?
答:当然不可以。如果是前序遍历,那么就是依据最早发现时间的排序,那么根据引理22.14,我们可以知道,前序遍历并不能保证不同连通分量之间有一个特定的排序。(看看算法导论的证明就懂了!)
2、为什么要搜索从最后一个点搜反图?从第一个点搜正图不行吗?
答:也是不可以。从第一个点开始就不是用的最晚完成时间的排序了,而是最早完成时间的排序了,可以有反例。比如,用上面那个图,搜到了一个排序‘6,7,5,4,3,2,1’,那么从第一个点开始搜正图——分量②和③将被染成一种颜色!
总结:
1、伪拓扑排序里面其实包含着一个缩点后的拓扑排序。
2、深搜果然是最神奇的算法!















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









