





http://www.quartz-scheduler.org/documentation/quartz-2.2.2/tutorials/tutorial-lesson-01.html
1.使用Quartz
- Quartz Scheduler一旦关闭,无法重启
- 需要重新实例化
- 提供了暂停状态
SchedulerFactory schedFact = new org.quartz.impl.StdSchedulerFactory();
Scheduler sched = schedFact.getScheduler();
sched.start();
// define the job and tie it to our HelloJob class
JobDetail job = newJob(HelloJob.class)
.withIdentity("myJob", "group1")
.build();
// Trigger the job to run now, and then every 40 seconds
Trigger trigger = newTrigger()
.withIdentity("myTrigger", "group1")
.startNow()
.withSchedule(simpleSchedule()
.withIntervalInSeconds(40)
.repeatForever())
.build();
// Tell quartz to schedule the job using our trigger
sched.scheduleJob(job, trigger);
2.Quartz API,JOB和Trigger
http://www.quartz-scheduler.org/documentation/quartz-2.2.2/tutorials/tutorial-lesson-02.html
-
JobBuilder-用于定义/构建JobDetail实例,该实例定义Jobs实例。
-
JobDetail-用于定义Job的实例。
-
Job-由您希望由调度程序执行的组件实现的接口。
-
TriggerBuilder-用于定义/构建触发器实例。
-
Trigger-定义将在其上执行给定作业的时间表的组件。
Scheduler
一个Scheduler的生命周期是由它的创作范围,通过SchedulerFactory来调用他的创建和关闭。
创建Scheduler后,就可以使用它
- 添加
- 删除
- 列出Job和Trigger
以及执行其他与计划相关的操作(例如暂停触发器)。但是,调度程序在使用starter之前实际上不会对任何trigger执行任务起作用
Builder的演示
// define the job and tie it to our HelloJob class
JobDetail job = newJob(HelloJob.class)
.withIdentity("myJob", "group1") // name "myJob", group "group1"
.build();
// Trigger the job to run now, and then every 40 seconds
Trigger trigger = newTrigger()
.withIdentity("myTrigger", "group1")
.startNow()
.withSchedule(simpleSchedule()
.withIntervalInSeconds(40)
.repeatForever())
.build();
// Tell quartz to schedule the job using our trigger
sched.scheduleJob(job, trigger);
Jobs and Triggers
Job是一个接口
public interface Job {
public void execute(JobExecutionContext context)
throws JobExecutionException;
}
当一个Jobs被触发执行的时候,会调用execute,在一个Scheduler的worker的线程里面。
JobExecutionContext提供了运行的时候需要的一些变量
JobDetail在Job加到Scheduler的时候,他能包含一些属性用来设置给job的,比如说JobDataMap,他能让我们存储一些状态信息给我们Job
Trigger用来触发执行任务,也包含了JobDataMap,他能告诉我们什么时候执行任务。默认有SimpleTrigger和CronTrigger
SimpleTriggere
如果您需要一次性执行(在给定时刻只执行一个作业),或者如果您需要在给定时间触发一个作业,并让它重复N次,两次执行之间的延迟为T,那么SimpleTrigger非常方便。
如果您希望基于类似日历的日程安排(如每个周五中午或每个月的第10天的10:15)进行触发,那么CronTrigger非常有用。
Identifies
JobKey and TriggerKey
groups
3.Job和JobDetail的详情
// define the job and tie it to our HelloJob class
JobDetail job = newJob(HelloJob.class)
.withIdentity("myJob", "group1") // name "myJob", group "group1"
.build();
// Trigger the job to run now, and then every 40 seconds
Trigger trigger = newTrigger()
.withIdentity("myTrigger", "group1")
.startNow()
.withSchedule(simpleSchedule()
.withIntervalInSeconds(40)
.repeatForever())
.build();
// Tell quartz to schedule the job using our trigger
sched.scheduleJob(job, trigger);
public class HelloJob implements Job {
public HelloJob() {
}
public void execute(JobExecutionContext context)
throws JobExecutionException
{
System.err.println("Hello! HelloJob is executing.");
}
}
每次执行的时候,都会在调用execute前创建其实例,执行完成后会删除和垃圾回收。
- 要求Job实现类必须有无参构造
- Job上面定义的状态数据字段没有什么用,因为每次都是新的,而且会被清除
- 这种存储信息最好使用
JobDataMap
- 这种存储信息最好使用
JobDataMap
// define the job and tie it to our DumbJob class
JobDetail job = newJob(DumbJob.class)
.withIdentity("myJob", "group1") // name "myJob", group "group1"
.usingJobData("jobSays", "Hello World!")
.usingJobData("myFloatValue", 3.141f)
.build();
public class DumbJob implements Job {
public DumbJob() {
}
public void execute(JobExecutionContext context)
throws JobExecutionException
{
JobKey key = context.getJobDetail().getKey();
JobDataMap dataMap = context.getJobDetail().getJobDataMap();
String jobSays = dataMap.getString("jobSays");
float myFloatValue = dataMap.getFloat("myFloatValue");
System.err.println("Instance " + key + " of DumbJob says: " + jobSays + ", and val is: " + myFloatValue);
}
}
- 存储的对象会被序列化,需要注意版本问题
- 如果keyName对应对应的
set+Keyname那么会调用对应的Job的setter方法
JobExecutionContext能够帮我们合并Trigger和JobDetail上的JobDataMap里面的值,Trigger上的key会覆盖JobDetail上的
public class DumbJob implements Job {
public DumbJob() {
}
public void execute(JobExecutionContext context)
throws JobExecutionException
{
JobKey key = context.getJobDetail().getKey();
JobDataMap dataMap = context.getMergedJobDataMap(); // Note the difference from the previous example
String jobSays = dataMap.getString("jobSays");
float myFloatValue = dataMap.getFloat("myFloatValue");
ArrayList state = (ArrayList)dataMap.get("myStateData");
state.add(new Date());
System.err.println("Instance " + key + " of DumbJob says: " + jobSays + ", and val is: " + myFloatValue);
}
}
Job 实例
触发器触发,会加载对应的JobDetail,并且通过配置的Jobfactory来实例化对应的Job
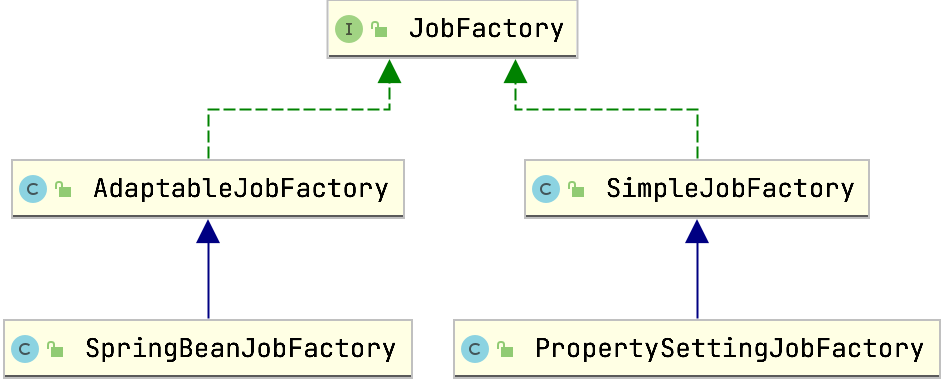
并且尝试在对应的JobFactory上调用与JobDataMap中的键名匹配的setter方法。
工作状态和并发执行
@DisallowConcurrentExecution
这个用来加到Job类上面,用来告诉Quartz不要同时执行同一个Job
@PersistJobDataAfterExecution
也是加到Job类上面,告诉Quartz执行完成后(没有出现异常),更新JobDataMap的存储,用来告诉下次执行的时候能够获取当前设置的值。
其他
- 持久性
- 如果Job不会再使用了,会自动从
Scheduler删除,这个和Trigger相关
- 如果Job不会再使用了,会自动从
RequestsRecovery - if a job “requests recovery”, and it is executing during the time of a ‘hard shutdown’ of the scheduler (i.e. the process it is running within crashes, or the machine is shut off), then it is re-executed when the scheduler is started again. In this case, the JobExecutionContext.isRecovering() method will return true.
4.关于Trigger
像Job一样,Trigger也很容易使用,但是确实包含各种自定义选项,在充分利用Quartz之前,您需要了解它们并了解它们。同样,如前所述,您可以选择不同类型的Trigger来满足不同的调度需求。
通用的Trigger属性
JobKey:- 触发器执行的时候执行的job标识
startTime:标识触发器生效时间endTime:触发器结束时间
优先级
当我们触发器很多,Quartz线程池的工作线程很少的时候,可能没有足够的资源同事启动所有要触发的触发器,如果没有指定优先级,会使用默认优先级5
优先级配置支持任何整数值正数或者负数
**注意:**只有触发时间相同的时候才会比较优先级,计划在10:59触发的触发器将始终在计划在11:00触发的触发器之前触发。
**注意:**当检测到触发器的作业需要恢复时,其恢复的排定的优先级与原始触发器相同。
CronTrigger trigger = TriggerBuilder.newTrigger().
withIdentity(getTriggerKey(scheduleJobEntity.getId())).
withSchedule(cronScheduleBuilder).
startAt(scheduleJobEntity.getStartTime()).
endAt(scheduleJobEntity.getEndTime()).
withPriority(10).
build();
日历
日历对于从触发器的触发计划中排除时间段很有用。例如,您可以创建一个触发器,该触发器在每个工作日的上午9:30触发一个工作,然后添加一个排除所有企业假期的日历。
public interface Calendar {
public boolean isTimeIncluded(long timeStamp);
public long getNextIncludedTime(long timeStamp);
}
上述接口都是毫秒,为了方便Quartz还提供了HolidayCalendar来提供整天的排除
HolidayCalendar cal = new HolidayCalendar();
cal.addExcludedDate( someDate );
cal.addExcludedDate( someOtherDate );
sched.addCalendar("myHolidays", cal, false);
Trigger t = newTrigger()
.withIdentity("myTrigger")
.forJob("myJob")
.withSchedule(dailyAtHourAndMinute(9, 30)) // execute job daily at 9:30
.modifiedByCalendar("myHolidays") // but not on holidays
.build();
// .. schedule job with trigger
Trigger t2 = newTrigger()
.withIdentity("myTrigger2")
.forJob("myJob2")
.withSchedule(dailyAtHourAndMinute(11, 30)) // execute job daily at 11:30
.modifiedByCalendar("myHolidays") // but not on holidays
.build();
// .. schedule job with trigger2
5.SimpleTrigger
如果您需要在特定的时间或特定的时间准确执行一次作业,然后在特定的时间间隔重复执行一次, SimpleTrigger应该可以满足您的调度需求。例如,如果您想让触发器在2015年1月13日上午11:23:54触发,或者您想在那时触发,然后每十秒钟再触发五次。
- 属性
- 开始时间和结束时间
- 重复计数
- 可以为零,正整数,常量值
SimpleTrigger.REPEAT_INDEFINITELY
- 可以为零,正整数,常量值
- 重复间隔
- 必须为零或者正值,代表为毫秒数
- 间隔为0
DateBuilder类有助于计算触发器的触发时间,取决于我们的开始和结束时间
开始和结束时间优先级大于重复计数
为特定时间建立触发器,不要重复
import static org.quartz.TriggerBuilder.*;
import static org.quartz.SimpleScheduleBuilder.*;
import static org.quartz.DateBuilder.*:
SimpleTrigger trigger = (SimpleTrigger) newTrigger()
.withIdentity("trigger1", "group1")
.startAt(myStartTime) // some Date
.forJob("job1", "group1") // identify job with name, group strings
.build();
为特定时间建立触发器,每十秒重复十次
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.startAt(myTimeToStartFiring) // if a start time is not given (if this line were omitted), "now" is implied
.withSchedule(simpleSchedule()
.withIntervalInSeconds(10)
.withRepeatCount(10)) // note that 10 repeats will give a total of 11 firings
.forJob(myJob) // identify job with handle to its JobDetail itself
.build();
建立一个触发器,该触发器将在未来五分钟触发一次
trigger = (SimpleTrigger) newTrigger()
.withIdentity("trigger5", "group1")
.startAt(futureDate(5, IntervalUnit.MINUTE)) // use DateBuilder to create a date in the future
.forJob(myJobKey) // identify job with its JobKey
.build();
建立一个现在将触发的触发器,然后每五分钟重复一次,直到22:00
trigger = newTrigger()
.withIdentity("trigger7", "group1")
.withSchedule(simpleSchedule()
.withIntervalInMinutes(5)
.repeatForever())
.endAt(dateOf(22, 0, 0))
.build();
建立一个触发器,该触发器将在下一个小时的顶部触发,然后永远每2小时重复一次:
trigger = newTrigger()
.withIdentity("trigger8") // because group is not specified, "trigger8" will be in the default group
.startAt(evenHourDate(null)) // get the next even-hour (minutes and seconds zero ("00:00"))
.withSchedule(simpleSchedule()
.withIntervalInHours(2)
.repeatForever())
// note that in this example, 'forJob(..)' is not called
// - which is valid if the trigger is passed to the scheduler along with the job
.build();
scheduler.scheduleJob(trigger, job);
SimpleTrigger MisFire
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
MISFIRE_INSTRUCTION_FIRE_NOW
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT
6.CronTrigger
如果您需要一个基于类似于日历的概念而不是根据SimpleTrigger的确切间隔重复发生的工作解雇时间表,则CronTrigger通常比SimpleTrigger有用。
使用CronTrigger,您可以指定触发计划,例如“每个星期五中午”,“每个工作日至9:30”,甚至“每个星期一,星期三的上午9:00至10:00之间的每5分钟”和一月的星期五”。
即便如此,与SimpleTrigger一样,CronTrigger具有一个startTime,用于指定计划何时生效;以及一个(可选的)endTime,用于指定计划何时终止。
Cron表达式
http://www.quartz-scheduler.org/documentation/quartz-2.2.2/tutorials/tutorial-lesson-06.html
表达式用于配置CronTrigger的实例。Cron-Expression是实际上由七个子表达式组成的字符串,它们描述了日程表的各个细节。这些子表达式用空格分隔,代表:
- 秒
- 分钟
- 小时
- 月的某一天
- 月
- 星期几
- 年(可选字段)
- 完整的cron表达式的示例是字符串
0 0 12 ?* WED- 代表每个星期三的12:00:00 pm”。
各个子表达式可以包含范围和/或列表。
- 例如,上一个
WED字段可以替换为“ MON-FRI”,“ MON,WED,FRI”,甚至“ MON-WED,SAT”。
通配符''可以用于表示字段的所有可能值
*代表每一周的每一天
/代表指定值的增量。
- 例如在分钟字段
0/15,表示每个小时的15分钟,从0 分钟开始, - 如果用
3/20表示每小时的第20分钟,从地三分钟开始 - 注意:
/35并不代表每35分钟,而是每小时的每35分钟,从零分钟开始即0/35
?:星期几和星期几字段允许使用字符。用于指定“无特定值”。当您需要在两个字段之一中指定某项而不是另一个字段时,这很有用
L:用于月和周,表示最后一个,月表示月的最后一天1月31日,2月28日。用于星期的话表示7或者sat(周六),如果6L表示该月的最后一个最后一个星期五,可以用来指定该月最后一天的偏移量L-3,表示日历月的倒数第三天
W用来指定给定日期的工作日(周一到星期五),15W指的是离每月15日最近的工作日
#用于指定每月的第“ n”个XXX工作日。例如,星期几字段中的6#3或FRI#3的值表示每月的第三个星期五。
Cron表达式示例
CronTrigger示例1-用于创建仅每5分钟触发一次的触发器的表达式
0 0/5 * * *?
CronTrigger示例2-创建一个触发器的表达式,该触发器每5分钟触发一次,每分钟后10秒(例如10:00:10 am,10:05:10 am等)触发。
10 0/5 * * * ?
CronTrigger示例3-创建一个触发器的表达式,该触发器在每个星期三和星期五的10:30、11:30、12:30和13:30触发。
0 30 10-13 ?* WED,FRI
CronTrigger示例4-创建一个触发器的表达式,该触发器在每月的5号和20号的上午8点到10点之间每半小时触发一次。请注意,触发器不会在上午10:00,仅在8:00、8:30、9:00和9:30触发
0 0/30 8-9 5,20 * ?
请注意,某些计划要求太过复杂而无法用一次触发来表达,例如“上午9:00至上午10:00之间每5分钟一次,下午1:00至10:00下午每20分钟一次”。这种情况下的解决方案是简单地创建两个触发器,并注册两个触发器以运行相同的作业。
构建CronTriggers
import static org.quartz.TriggerBuilder.*;
import static org.quartz.CronScheduleBuilder.*;
import static org.quartz.DateBuilder.*:
建立一个触发器,该触发器每天每天从早上8点到下午5点之间每隔一分钟触发一次:
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(cronSchedule("0 0/2 8-17 * * ?"))
.forJob("myJob", "group1")
.build();
建立触发器,每天10:42 am触发
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(dailyAtHourAndMinute(10, 42))
.forJob(myJobKey)
.build();
或者
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(cronSchedule("0 42 10 * * ?"))
.forJob(myJobKey)
.build();
构建一个触发器,该触发器将在星期三上午10:42,使用系统默认值以外的TimeZone触发
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(weeklyOnDayAndHourAndMinute(DateBuilder.WEDNESDAY, 10, 42))
.forJob(myJobKey)
.inTimeZone(TimeZone.getTimeZone("America/Los_Angeles"))
.build();
或者
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(cronSchedule("0 42 10 ? * WED"))
.inTimeZone(TimeZone.getTimeZone("America/Los_Angeles"))
.forJob(myJobKey)
.build();
CronTrigger MisFire说明
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
MISFIRE_INSTRUCTION_DO_NOTHING
MISFIRE_INSTRUCTION_FIRE_NOW
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(cronSchedule("0 0/2 8-17 * * ?")
..withMisfireHandlingInstructionFireAndProceed())
.forJob("myJob", "group1")
.build();
7.TriggerListeners和JobListeners
侦听器是您创建的对象,用于根据调度程序中发生的事件执行操作。您可能会猜到,**TriggerListeners*接收与触发器相关的事件,而JobListeners* 接收与作业相关的事件。
public interface TriggerListener {
public String getName();
public void triggerFired(Trigger trigger, JobExecutionContext context);
public boolean vetoJobExecution(Trigger trigger, JobExecutionContext context);
public void triggerMisfired(Trigger trigger);
public void triggerComplete(Trigger trigger, JobExecutionContext context,
int triggerInstructionCode);
}
与作业相关的事件包括:即将执行作业的通知,以及作业完成执行时的通知。
public interface JobListener {
public String getName();
public void jobToBeExecuted(JobExecutionContext context);
public void jobExecutionVetoed(JobExecutionContext context);
public void jobWasExecuted(JobExecutionContext context,
JobExecutionException jobException);
}
使用自己的监听器
要创建侦听器,只需创建一个实现org.quartz.TriggerListener或org.quartz.JobListener接口的对象。然后,在运行时将侦听器注册到调度程序,并且必须给其指定名称(或者说,它们必须通过其getName()方法发布自己的名称)。
侦听器与调度程序的ListenerManager一起注册,该Matcher描述了侦听器要为其接收事件的作业/触发器。
侦听器在运行时会向调度程序注册,并且不会与作业和触发器一起存储在JobStore中。这是因为侦听器通常是您的应用程序的集成点。因此,每次您的应用程序运行时,都需要在调度程序中重新注册侦听器。
scheduler.getListenerManager().addJobListener(myJobListener, jobKeyEquals(jobKey("myJobName", "myJobGroup")));
添加对特定组的所有作业感兴趣的JobListener
scheduler.getListenerManager().addJobListener(myJobListener, jobGroupEquals("myJobGroup"));
添加对两个特定组的所有作业感兴趣的JobListener
scheduler.getListenerManager().addJobListener(myJobListener, or(jobGroupEquals("myJobGroup"), jobGroupEquals("yourGroup")));
添加对所有作业感兴趣的JobListener
scheduler.getListenerManager().addJobListener(myJobListener, allJobs());
Quartz的大多数用户都不使用侦听器,但是当应用程序需求创建事件通知的需求时,侦听器非常方便,而Job本身不必显式通知应用程序。
8.SchedulerListeners
***SchedulerListener***与TriggerListeners和JobListeners非常相似,除了它们在Scheduler自身内接收事件的通知-不一定与特定触发器或作业有关的事件。
与调度程序相关的事件包括:添加作业/触发器,移除作业/触发器,调度程序内的严重错误,通知调度程序正在关闭等。
public interface SchedulerListener {
public void jobScheduled(Trigger trigger);
public void jobUnscheduled(String triggerName, String triggerGroup);
public void triggerFinalized(Trigger trigger);
public void triggersPaused(String triggerName, String triggerGroup);
public void triggersResumed(String triggerName, String triggerGroup);
public void jobsPaused(String jobName, String jobGroup);
public void jobsResumed(String jobName, String jobGroup);
public void schedulerError(String msg, SchedulerException cause);
public void schedulerStarted();
public void schedulerInStandbyMode();
public void schedulerShutdown();
public void schedulingDataCleared();
}
添加一个SchedulerListener
scheduler.getListenerManager().addSchedulerListener(mySchedListener);
删除SchedulerListener
scheduler.getListenerManager().removeSchedulerListener(mySchedListener);
9.JobStore
JobStore负责跟踪您提供给调度程序的所有“JobData”:作业,触发器,日历等。为Quartz调度程序实例选择适当的JobStore是重要的一步。
幸运的是,一旦您了解了两者之间的差异,那么选择就非常容易。
您在提供给用于生成调度程序实例的SchedulerFactory的属性文件(或对象)中声明调度程序应使用哪个JobStore(及其配置设置)。
切勿在代码中直接使用JobStore实例。由于某些原因,许多人试图这样做。JobStore用于Quartz本身的幕后使用。您必须(通过配置)告诉Quartz使用哪个JobStore,但是您仅应在代码中使用Scheduler接口。
RAMJobStore
RAMJobStore是使用最简单的JobStore,也是性能最高的(就CPU时间而言)。RAMJobStore的名称很明显:
- 将所有数据保留在RAM中。这就是为什么它闪电般的快速,也是为什么它是如此简单的配置。
- 缺点是
- 当您的应用程序结束(或崩溃)时,所有调度信息都将丢失-
- 这意味着RAMJobStore无法接受
Job和Trigger上的duriable设置。 - 对于某些应用程序,这是可以接受的,甚至是所需的行为,但是对于其他应用程序,这可能是灾难性的。
要使用RAMJobStore(并假设您正在使用StdSchedulerFactory),只需将类名称org.quartz.simpl.RAMJobStore指定为用于配置石英的JobStore类属性:
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
JDBCJobStore
JDBCJobStore也被恰当地命名-它通过JDBC将其所有数据保存在数据库中。因此,它的配置要比RAMJobStore复杂一些,并且速度也没有那么快。
但是,性能下降并不是很糟糕,尤其是当您使用主键上的索引构建数据库表时。在具有适当LAN(在调度程序和数据库之间)的相当现代的一组计算机上,检索和更新触发触发器的时间通常少于10毫秒。
JDBCJobStore几乎可以与任何数据库一起使用,它已被Oracle,PostgreSQL,MySQL,MS SQLServer,HSQLDB和DB2广泛使用。要使用JDBCJobStore,必须首先创建一组数据库表供Quartz使用。您可以在Quartz发行版的docs / dbTables目录中找到表创建SQL脚本。如果没有针对您的数据库类型的脚本,只需查看现有脚本之一,然后以数据库所需的任何方式对其进行修改。需要注意的一件事是,在这些脚本中,所有表都以前缀“ QRTZ_”开头(例如表“ QRTZ_TRIGGERS”和“ QRTZ_JOB_DETAIL”)。只要您告知JDBCJobStore前缀是什么(在Quartz属性中),该前缀实际上就可以是您想要的任何前缀。使用不同的前缀对于创建多个表集,多个调度程序实例可能很有用,
创建表之后,在配置和启动JDBCJobStore之前,您需要做出另一个重要决定。您需要确定您的应用程序需要哪种事物来管理。如果您不需要将调度命令(例如添加和删除触发器)与其他事务绑定,则可以让Quartz通过将JobStoreTX用作JobStore来管理事务(这是最常见的选择)。
如果您需要Quartz与其他事务一起工作(即在J2EE应用程序服务器中),则应使用JobStoreCMT-在这种情况下,Quartz将允许应用程序服务器容器管理事务。
最后一个难题是设置一个数据源,JDBCJobStore可以从该数据源获得与您的数据库的连接。
数据源是使用几种不同方法之一在Quartz属性中定义的。
- 一种方法是让Quartz通过提供数据库的所有连接信息来创建和管理DataSource本身。
- 另一种方法是通过提供JDBCJobStore数据源的JNDI名称,使Quartz使用由Quartz在其中运行的应用程序服务器管理的数据源。有关属性的详细信息,请查阅
docs / config文件夹中的示例配置文件。
要使用JDBCJobStore(并假设您使用的是StdSchedulerFactory),首先需要将Quartz配置的JobStore类属性设置为org.quartz.impl.jdbcjobstore.JobStoreTX或org.quartz.impl.jdbcjobstore.JobStoreCMT根据以上几段中的说明进行的选择。
配置Quartz以使用JobStoreTx
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
接下来,您需要选择一个DriverDelegate供JobStore使用。DriverDelegate负责完成特定数据库可能需要的任何JDBC工作。
StdJDBCDelegate是使用“原始” JDBC代码(和SQL语句)完成其工作的委托。如果没有专门为您的数据库创建的另一个委托,请尝试使用此委托-我们仅对使用StdJDBCDelegate与(发现最多!)发现问题的数据库进行了特定于数据库的委托。其他代表可以在“ org.quartz.impl.jdbcjobstore”包或其子包中找到。其他代表包括DB2v6Delegate(用于DB2版本6和更早版本),HSQLDBDelegate(用于HSQLDB),MSSQLDelegate(用于Microsoft SQLServer),PostgreSQLDelegate(用于PostgreSQL),WeblogicDelegate(用于使用由Weblogic制造的JDBC驱动程序),
选择委托后,将其类名称设置为JDBCJobStore使用的委托。
配置JDBCJobStore以使用DriverDelegate
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
接下来,您需要通知JobStore您正在使用的表前缀(上面已讨论过)。
使用表前缀配置JDBCJobStore
org.quartz.jobStore.tablePrefix = QRTZ_
最后,您需要设置JobStore应该使用哪个数据源。还必须在Quartz属性中定义命名的DataSource。在这种情况下,我们指定Quartz应该使用数据源名称“ myDS”(在配置属性的其他位置定义)。
使用要使用的数据源的名称配置JDBCJobStore
org.quartz.jobStore.dataSource = myDS
如果您的调度程序很忙(即几乎总是执行与线程池大小相同的作业数),那么您可能应该将DataSource中的连接数设置为线程池大小的+ 2。
可以将“ org.quartz.jobStore.useProperty”配置参数设置为“ true”(默认为false),以指示JDBCJobStore JobDataMaps中的所有值均为字符串,因此可以存储为名称-值对,而不是而不是将更复杂的对象以其序列化形式存储在BLOB列中。从长远来看,这样做更加安全,因为可以避免将非String类序列化为BLOB时出现的类版本控制问题。
TerracottaJobStore
TerracottaJobStore提供了一种无需使用数据库即可进行缩放和增强功能的方法。这意味着您的数据库可以免于Quartz的负载,而可以为应用程序的其余部分保存所有资源。
TerracottaJobStore可以集群化或非集群化运行,并且在两种情况下都可以为您的作业数据提供一种存储介质,该存储介质在应用程序重新启动之间是持久的,因为数据存储在Terracotta服务器中。它的性能比通过JDBCJobStore使用数据库要好得多(大约好一个数量级),但比RAMJobStore慢得多。
要使用TerracottaJobStore(并假设您使用的是StdSchedulerFactory),只需指定类名称org.quartz.jobStore.class = org.terracotta.quartz.TerracottaJobStore作为用于配置Quartz的JobStore类属性,然后添加一行配置以指定Terracotta服务器的位置:
org.quartz.jobStore.class = org.terracotta.quartz.TerracottaJobStore
org.quartz.jobStore.tcConfigUrl = localhost:9510
有关此JobStore和Terracotta的更多信息, 请访问http://www.terracotta.org/quartz。
10.配置,资源使用情况和SchedulerFactory
Quartz的体系结构是模块化的,因此要使其运行,需要将多个组件“绑定”在一起。幸运的是,存在一些帮助实现此目标的助手。
Quartz进行工作之前需要配置的主要组件是:
- 线程池
- 作业库
- 数据源
- 调度程序本身
该***线程池***提供了一组线程供Quartz在执行Jobs时使用。池中的线程越多,可以并行运行的作业数越多。但是,太多线程可能会使您的系统瘫痪。
大多数Quartz用户发现5个左右的线程是足够的-因为在任何给定的时间它们少于100个作业,通常不安排这些作业同时运行,并且这些作业是短暂的(快速完成)。
其他用户发现他们需要10、15、50甚至100个线程-因为它们具有成千上万个具有各种计划的触发器-最终平均有10到100个试图在任何给定时刻执行的作业。
为调度程序池找到合适的大小完全取决于您使用调度程序的目的。没有真正的规则,除了使线程数尽可能小(为了节省计算机资源)外-还要确保有足够的空间按时启动作业。
请注意,如果触发器的触发时间到了,并且没有可用的线程,Quartz将阻塞(暂停)直到某个线程可用,然后作业将执行-比原先的时间晚了几毫秒。
如果在调度程序配置的misfire阈值期间没有可用的线程,这甚至可能导致线程不触发。
在org.quartz.spi包中定义了ThreadPool接口,您可以按照自己喜欢的任何方式创建ThreadPool实现。Quartz附带了一个简单(但非常令人满意)的线程池,名为org.quartz.simpl.SimpleThreadPool。此ThreadPool只是在其池中维护一组固定的线程-永不增长,永不收缩。但是它非常健壮,并且经过了很好的测试-因为几乎所有使用Quartz的人都使用该池。
这里值得一提的是,所有JobStore都实现了org.quartz.spi.JobStore接口-如果捆绑的JobStore之一不符合您的需求,那么您可以自己制作。
最后,您需要创建Scheduler实例。需要给Scheduler本身一个名称,告诉它的RMI设置,并传递JobStore和ThreadPool的实例。RMI设置包括调度程序是否应将其自身创建为RMI的服务器对象(使其可用于远程连接),要使用的主机和端口等。StdSchedulerFactory(下面讨论)还可以产生实际上是代理的Scheduler实例( RMI存根)到在远程进程中创建的调度程序。
StdSchedulerFactory
StdSchedulerFactory是org.quartz.SchedulerFactory接口的实现。它使用一组属性(java.util.Properties)创建和初始化Quartz Scheduler。
这些属性通常存储在文件中并从文件中加载,但是也可以由程序创建并直接交给工厂。只需在工厂上调用getScheduler()即可生成调度程序,对其进行初始化(及其ThreadPool,JobStore和DataSources),并将句柄返回其公共接口。
Quartz发行版的“ docs / config”目录中有一些示例配置(包括属性说明)。您可以在Quartz文档的“Reference”部分下的“Configuration”手册中找到完整的文档。
DirectSchedulerFactory
DirectSchedulerFactory是另一个SchedulerFactory实现。对于希望以更具编程性的方式创建其Scheduler实例的用户来说,这很有用。通常不建议使用它,原因如下:
- 它要求用户对他们的工作有更深入的了解
- 它不允许进行声明式配置-换句话说,您最终会很难-对所有调度程序的设置进行编码。
日志
Quartz使用SLF4J框架来满足其所有日志记录需求。为了“调整”日志记录设置(例如输出的数量以及输出的输出位置),您需要了解SLF4J框架,这不在本文档的讨论范围之内。
如果要捕获有关触发器触发和作业执行的其他信息,则可能对启用org.quartz.plugins.history.LoggingJobHistoryPlugin或 org.quartz.plugins.history.LoggingTriggerHistoryPlugin感兴趣。
11.高级功能
群集当前可与JDBC-Jobstore(JobStoreTX或JobStoreCMT)和TerracottaJobStore一起使用。功能包括负载平衡和作业故障转移(如果JobDetail的“请求恢复”标志设置为true)。
使用JobStoreTX或JobStoreCMT进行群集通过将org.quartz.jobStore.isClustered属性设置为“ true”来启用群集。
集群中的每个实例都应使用quartz.properties文件的相同副本。例外情况是使用相同的属性文件,但允许以下例外:不同的线程池大小和org.quartz.scheduler.instanceId属性的不同值。
集群中的每个节点必须具有唯一的instanceId,可以通过将“ AUTO”放置为该属性的值来轻松完成(不需要其他属性文件)。
切勿在单独的计算机上运行集群,除非使用非常定期运行的某种形式的时间同步服务(守护程序)同步它们的时钟(时钟之间的时间间隔必须在1秒钟之内)。 如果您不熟悉此操作,请参阅http://www.boulder.nist.gov/timefreq/service/its.htm。
切勿针对其他实例正在运行的同一组表启动非集群实例。您可能会遇到严重的数据损坏,并且肯定会遇到不稳定的行为
每次触发时,只有一个节点将触发该作业。我的意思是,如果作业具有重复的触发器,告诉它每10秒触发一次,则在12:00:00恰好一个节点将运行该作业,而在12:00:10恰好一个节点将运行作业等等。不一定每次都在同一个节点上-哪个节点运行它或多或少是随机的。对于繁忙的调度程序(大量触发器),负载平衡机制几乎是随机的,但偏向于对于非繁忙的调度程序(例如,一个或两个触发器)仅处于活动状态的同一节点。
使用TerracottaJobStore进行集群只需配置调度程序以使用TerracottaJobStore(已在 第9课:JobStores中介绍),您的调度程序将全部设置为集群。
您可能还需要考虑如何设置Terracotta服务器的含义,特别是打开诸如持久性等功能以及为HA运行一系列Terracotta服务器的配置选项。
TerracottaJobStore企业版提供高级Quartz Where功能,可将作业智能地定向到适当的群集节点。
JTA事物
JobStoreCMT允许在较大的JTA事务中执行Quartz调度操作。
通过将org.quartz.scheduler.wrapJobExecutionInUserTransaction属性设置为true,作业还可以在JTA事务(UserTransaction)中执行。
设置此选项后,JTA事务将在Job的execute方法被调用之前开始begin(),而execute调用终止后将进行commit()。这适用于所有作业。
如果要为每个作业指示JTA事务是否应该包装其执行,则应在作业类上使用 @ExecuteInJTATransaction批注。
除了Quartz在JTA事务中自动包装Job执行之外,在使用JobStoreCMT时,您在Scheduler接口上进行的调用也会参与事务。只需确保已启动事务,然后再调用调度程序上的方法即可。您可以通过使用UserTransaction来直接执行此操作,也可以将使用调度程序的代码放在使用容器管理的事务的SessionBean中。
12.其他功能
Quartz提供了一个用于插入附加功能的接口(org.quartz.spi.SchedulerPlugin)。
可以在*org.quartz.plugins* 包中找到Quartz附带的提供各种实用程序功能的插件。它们提供了一些功能,例如在调度程序启动时自动调度作业,记录作业和触发事件的历史记录,并确保在JVM退出时调度程序完全关闭。
JobFactory
触发触发器时,将通过在Scheduler上配置的JobFactory实例化与之关联的Job。默认的JobFactory仅在作业类上调用newInstance()。
您可能需要创建自己的JobFactory实现,以完成诸如使应用程序的IoC或DI容器生成/初始化作业实例之类的事情。
Factory-Shipped Jobs
Quartz还提供了许多实用程序作业,您可以在应用程序中使用它们来完成诸如发送电子邮件和调用EJB之类的事情。这些开箱即用的作业可以在*org.quartz.jobs* 包中找到。















 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









