







Scrapy(官网 http://scrapy.org/)是一款功能强大的,用户可定制的网络爬虫软件包。其官方描述称:"
Scrapy is a fast high-level screen scraping and web crawling framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing
"
Scrapy在github中有源码托管https://github.com/scrapy/scrapy,其安装可以参考github中提供的安装方法(大百度中也提供了很多安装方法的描述)。另外网站1和网站2提供了scrapy的使用方法和简单实例(小编后续随笔也会简单写一个scrapy实例,供大家参考)。
Scrapy的爬虫原理:
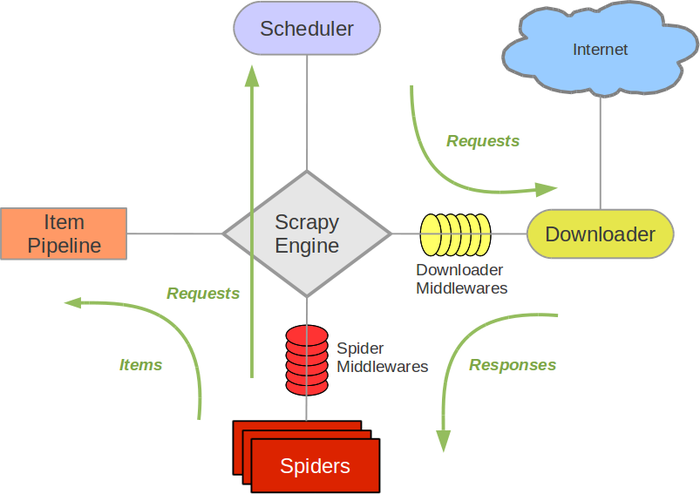
”盗用“的scrapy 官网中的scrapy核心框架图
Scrapy Engine是scrapy软件的核心,他负责各个组件的协调处理
Scheduler是调度器,负责爬去队列的管理,如Request的入队和出队管理
Item Pipeline 是抓取内容的核心组件,用户想要获取的内容可以写入item 然后再pipeline中设计数据的流向比如写入文件或是持久化到数据库中
Downloader 则是scrapy与web site接触的端口,负责根据Request 请求网页然后以response的形式返回用户处理接口(默认是 spider的parse函数)
Spider则是用户定制兴趣内容的模块,在scrapy的spiders中内置了BaseSpider,CSVFeedSpider,CrawlerSpider,用户可以根据情况选择合适spider继承与开发
Spider Middlewares则是Spider与Scrapy Engine 的中间层,用户可以个性化定义Spider向Engine传输过程
Scrpay的运行过程:
(1)Engine从Spider中获取一个需要爬取的URL(从spider中start_url获取),并以Request的形式在Scheduler中列队。
(2)Scheduler根据列队情况,把Request发送给Downloader,Downloader根据Request请求网页,并获取网页内容。
(3)网页内容以Response的形式经过Engine发送给Spider,并根据用户解析生成Item,发送给Pipeline。
(4)Pipeline根据获得的item和settings中的设置,处理item(process_item)把数据输出到文件或是数据库中。
上述过程反复进行,直到没有新的请求为止(此过程是一个异步处理过程)。














 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









