







本人最近在本地的虚拟机centos系统中搭建了一个hadoop2.7.2的伪分布式环境,并且可以成功执行wordcount代码,以下步骤大家可以参考参考。
以下是需要用到的软件列表:
1.VMware12 pro
2.CentOS-6.7-x86_64-bin-DVD1.iso
3.jdk-8u20-linux-x64.tar.gz
4.sublime_text_3_build_3103_x64.tar.bz2
5.hadoop-2.7.2.tar.gz
一、安装虚拟机并且通过CentOs镜像文件安装Centos6.7系统(步骤省略)
二、安装sublime_text_3
首先将sublime_text_3_build_3103_x64.tar放到/opt 目录下。
然后执行解压命令: tar-jxvf sublime_text_3_build_3103_x64.tar.bz2
解压后进入sublime_text_3目录。
执行命令 cp /opt/sublime_text_3/sublime_text.desktop /usr/share/applications
将sublime_text.desktop放到/usr/share/applications
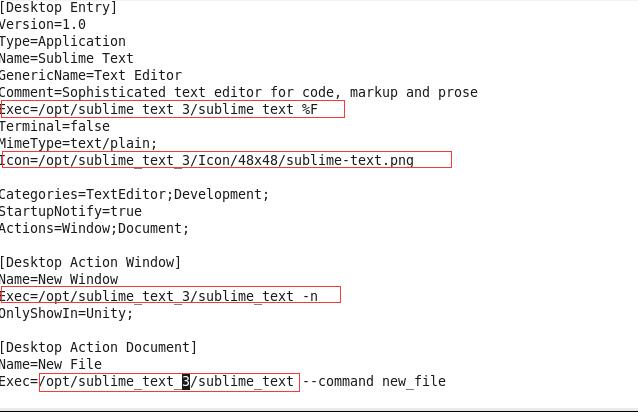
然后执行命令vi命令: vi /usr/share/applications/sublime_text.desktop
如何修改正确本地路径:
如下图添加桌面快捷方式:
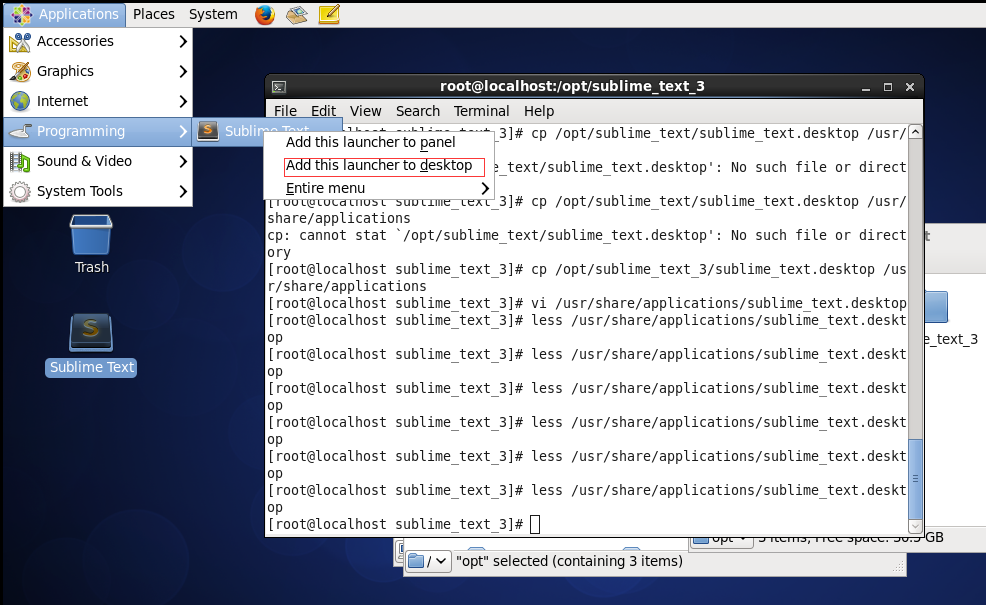
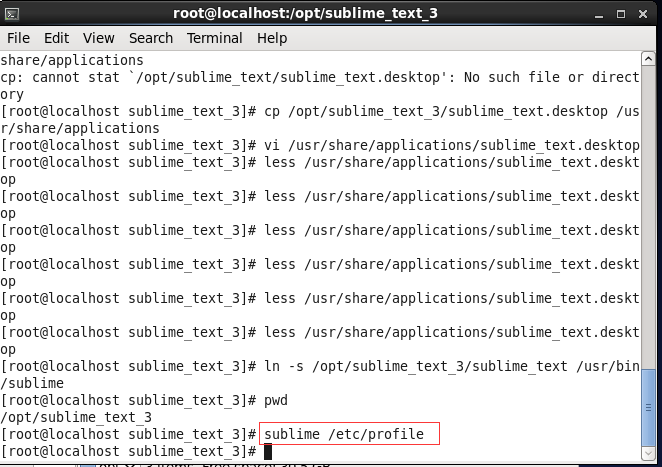
执行命令ln -s /opt/sublime_text_3/sublime_text /usr/bin/sublime 将sublime命令添加到本地环境。
然后可以通过命令sublime 直接打开文件。
三、安装JDK
将jdk-8u20-linux-x64.tar文件放到/opt目录下。
然后执行解压命令tar –zxvf jdk-8u20-linux-x64.tar.gz
接着卸载本地openjdk。
首先执行命令:rpm -qa | grep jdk
如果执行命令显示了openjdk,则执行yum –y remove xxx 将本地openjdk删除。
删除本地openjdk之后配置java环境变量
执行命令sublime /etc/profile
然后将 export JAVA_HOME=/opt/jdk1.8.0_20
export PATH=$PATH:$JAVA_HOME/bin
内容添加到该文件中,并保存。
然后执行 source /etc/profile 命令让环境变量生效。
接着执行 java –version 查看java版本

四、安装hadoop2.7.2伪分布式
Ssh 无密码登陆
vi /etc/ssh/sshd_config
#以下4行的注释需要打开
HostKey /etc/ssh/ssh_host_rsa_key
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
保存并重启sshd执行命令:service sshd restart

生成免登陆秘钥
ssh-keygen -t rsa
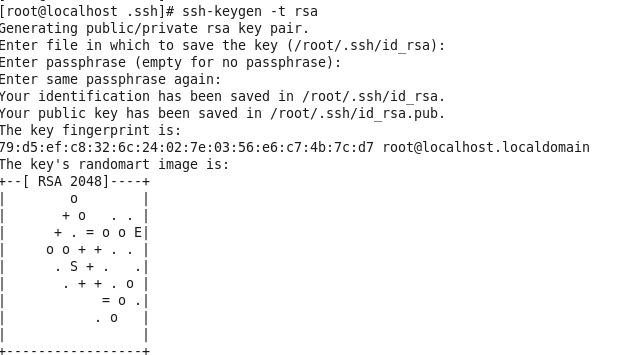
一路回车。之后会在当前登陆用户主目录中的.ssh文件夹里生成2个文件。
如果是root用户则cd /root/.ssh 如何是单独创建的用户则cd /用户名/home/.ssh
进入.ssh目录。
cat id_rsa.pub>> authorized_keys
现在可以用ssh无密码登陆系统了。
ssh localhost
将hadoop-2.7.2.tar放到/opt目录下,并解压该文件。
然后配置hadoop环境变量,执行sublime /etc/profile
接着设置以下环境变量:
exportHADOOP_HOME=/opt/hadoop-2.7.2
exportPATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
exportHADOOP_COMMON_HOME=$HADOOP_HOME
exportHADOOP_HDFS_HOME=$HADOOP_HOME
exportHADOOP_MAPRED_HOME=$HADOOP_HOME
exportHADOOP_YARN_HOME=$HADOOP_HOME
exportHADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
exportHADOOP_OPTS=-Djava.library.path=$HADOOP_HOME/lib
然后执行source /etc/profile命令
查看hadoop版本: hadoop version
配置Hadoop
创建hadoop的name与data目录
mkdir -p /usr/hdfs/name
mkdir -p /usr/hdfs/data
mkdir -p /usr/hdfs/tmp
cd /opt/hadoop-2.7.2/etc/hadoop
设置以下文件的JAVA_HOME
hadoop-env.sh yarn-env.sh
export JAVA_HOME=/opt/jdk1.8.0_20
执行命令:sublime core-site.xml
在configuration节点里面加入以下配置
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hdfs/tmp</value>
<description>A base for other temporarydirectories.</description>
</property>
<!--file system properties-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
执行命令:sublime hdfs-site.xml
同样在configuration节点里面加入以下配置
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
从模板复制一份mapred-site.xml
cpmapred-site.xml.template mapred-site.xml
执行命令:sublime mapred-site.xml
同样在configuration节点里面加入以下配置
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
至此,已经将Hadoop初步的环境配置好了,在启动之前还需要格式化namenode。
输入命令“hadoop namenode -format”;
然后 cd /opt/hadoop-2.7.2/sbin 启动hadoop.
执行启动命令: ./start-all.sh
然后执行jps命令,如下图:
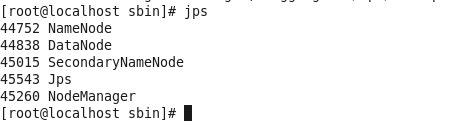
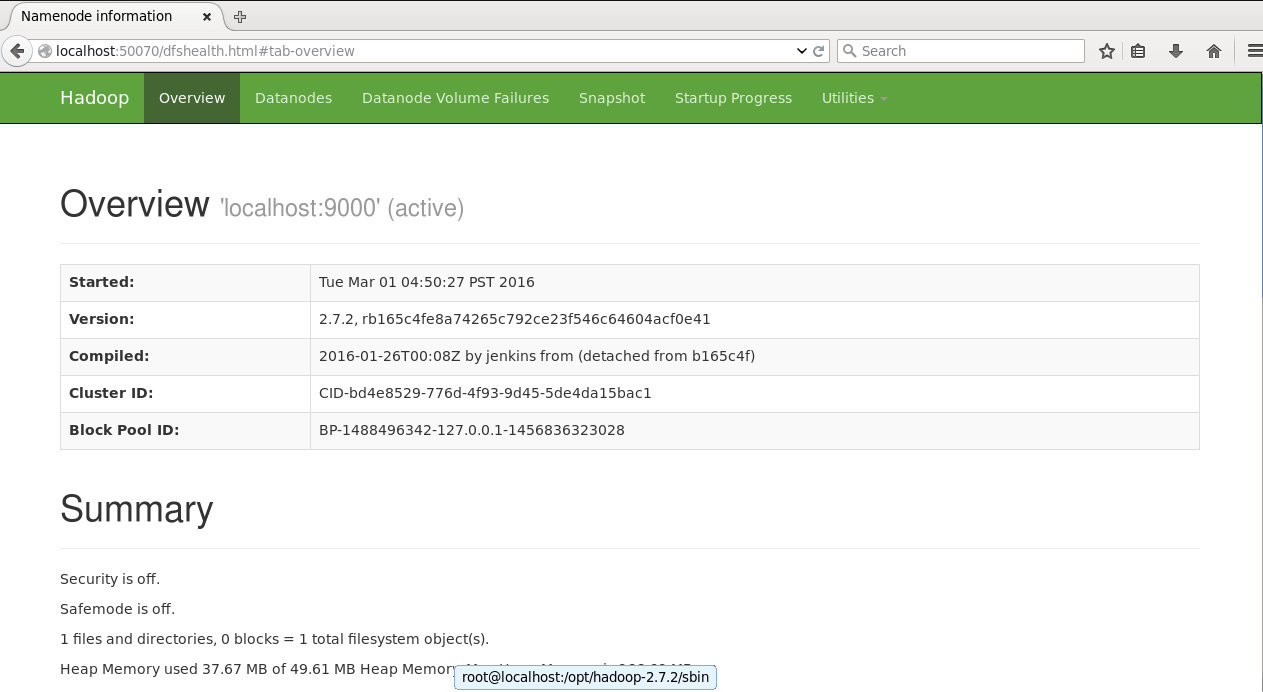
启动完毕,打开浏览器输入 http://localhost:50070 (监控namenode,datanode,查看hdfs) 与 http://localhost:8088/cluster (监控mapreduce运行状况) 验证安装。

测试Hadoop
通过运行hadoop自带的wordcount来验证安装是否正确。
进入/opt/hadoop-2.7.2/share/hadoop/mapreduce安装的目录,输入以下命令。
mkdir example
cd example
编辑file1.txt与file2.txt
执行命令:sublime file1.txt ,并保存以下内容。
hello zhm
hello hadoop
hello cz
执行命令:sublime file2.txt,并保存以下内容。
hadoop is ok
hadoop is newbee
hadoop 2.7.2
在hdfs上创建 data目录,并把本地两个文件put到data目录中
hadoop fs -mkdir /data
hadoop fs -put -f example/file1.txt example/file2.txt /data
运行wordcount例子
执行命令:
hadoop jar/opt/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jarwordcount /data /output
注意:jar包的地址必须填写好正确的路径,即使你已经cd到jar包的目录下,也不可以省略路径,必须要绝对路径。
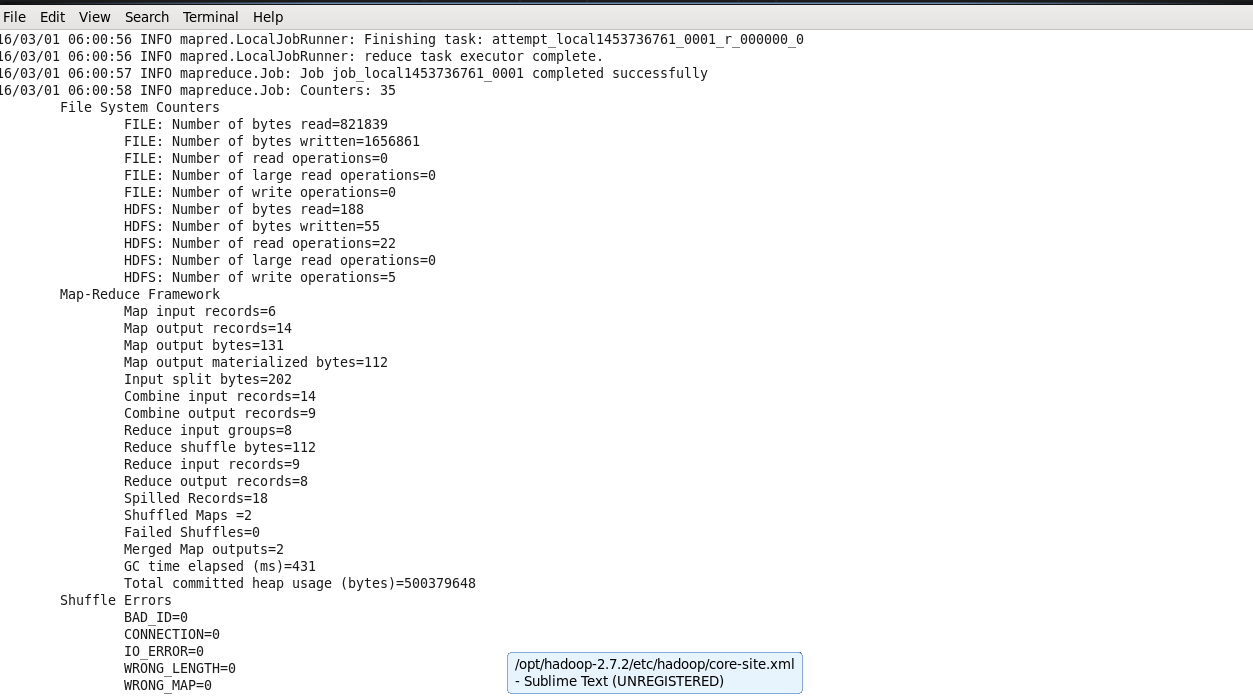
然后可以执行命令查看结果:
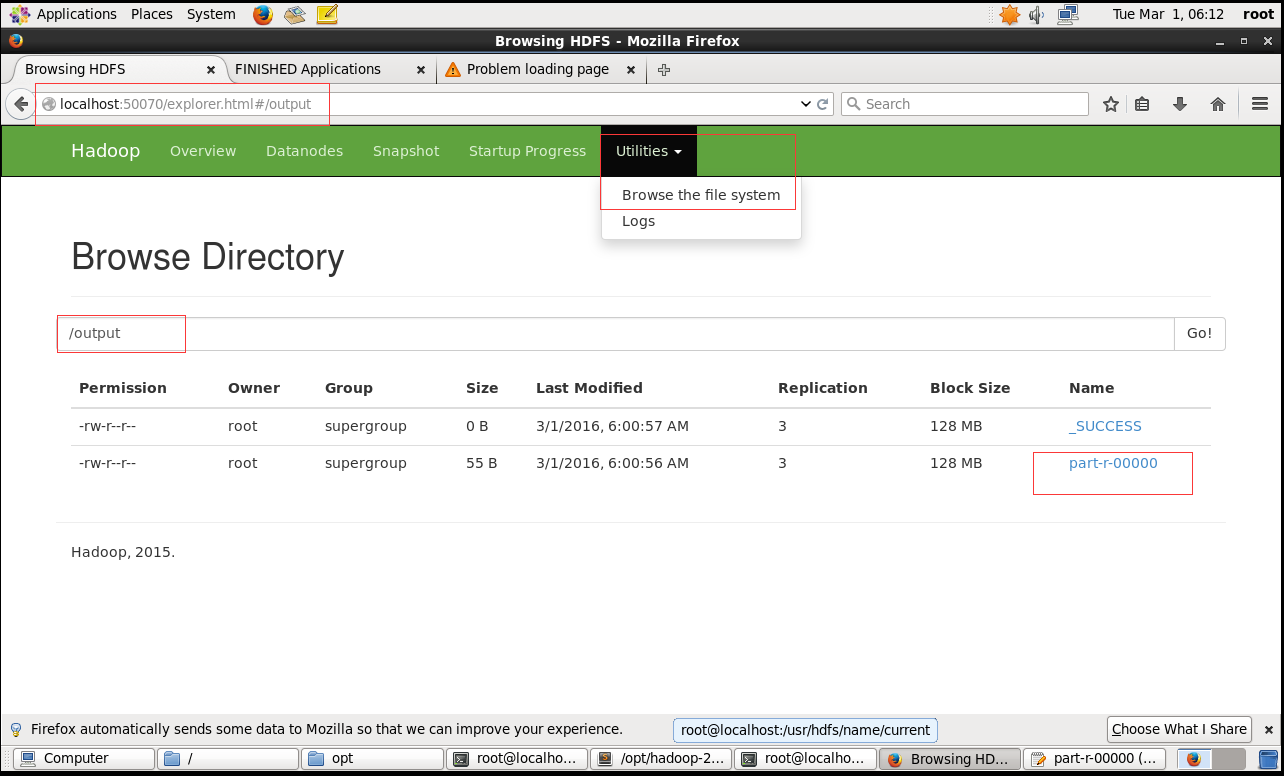
hadoop fs -cat /output/part-r-00000

或者是通过web端,访问查看结果














 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









