







 本文介绍了C4.5决策树算法,它是ID3算法的改进版,通过信息增益率选择属性,能处理连续属性和不完整数据。作者分享了算法的基本概念、数据集、程序代码及结果分析,强调了理论与实践结合的重要性。
本文介绍了C4.5决策树算法,它是ID3算法的改进版,通过信息增益率选择属性,能处理连续属性和不完整数据。作者分享了算法的基本概念、数据集、程序代码及结果分析,强调了理论与实践结合的重要性。
一、前言
当年实习公司布置了一个任务让写一个决策树,以前并未接触数据挖掘的东西,但作为一个数据挖掘最基本的知识点,还是应该有所理解的。
程序的源码可以点击这里进行下载,下面简要介绍一下决策树以及相关算法概念。
决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。 数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测(就像上面的银行官员用他来预测贷款风险)。从数据产生决策树的机器学习技术叫做决策树学习, 通俗说就是决策树。(来自维基百科)
1986年Quinlan提出了著名的ID3算法。在ID3算法的基础上,1993年Quinlan又提出了C4.5算法。为了适应处理大规模数据集的需要,后来又提出了若干改进的算法,其中SLIQ (super-vised learning in quest)和SPRINT (scalable parallelizableinduction of decision trees)是比较有代表性的两个算法,此处暂且略过。
本文实现了C4.5的算法,在ID3的基础上计算信息增益,从而更加准确的反应信息量。其实通俗的说就是构建一棵加权的最短路径Haffman树,让权值最大的节点为父节点。
二、基本概念
下面简要介绍一下ID3算法:
ID3算法的核心是:在决策树各级结点上选择属性时,用信息增益(information gain)作为属性的选择标准,以使得在每一个非叶结点进行测试时,能获得关于被测试记录最大的类别信息。
其具体方法是:检测所有的属性,选择信息增益最大的属性产生决策树结点,由该属性的不同取值建立分支,再对各分支的子集递归调用该方法建立决策树结点的分支,直到所有子集仅包含同一类别的数据为止。最后得到一棵决策树,它可以用来对新的样本进行分类。
某属性的信息增益按下列方法计算:
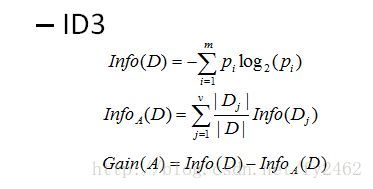
信息熵是香农提出的,用于描述信息不纯度(不稳定性),其计算公式是Info(D)。
其中:Pi为子集合中不同性(而二元分类即正样例和负样例)的样例的比例;j是属性A中的索引,D是集合样本,Dj是D中属性A上值等于j的样本集合。
这样信息收益可以定义为样本按照某属性划分时造成熵减少的期望,可以区分训练样本中正负样本的能力。信息增益定义为结点与其子结点的信息熵之差,公式为Gain(A)。
ID3算法的优点是:算法的理论清晰,方法简单,学习能力较强。其缺点是:只对比较小的数据集有效,且对噪声比较敏感,当训练数据集加大时,决策树可能会随之改变。
C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









