







day5(10月17日)
今日关键词:机器学习基础 视觉处理基础 CIFAR-10代码实现
- 机器学习的基本任务
机器学习基本任务一般分为四类:监督学习、无监督学习、半监督学习以及强化学习。
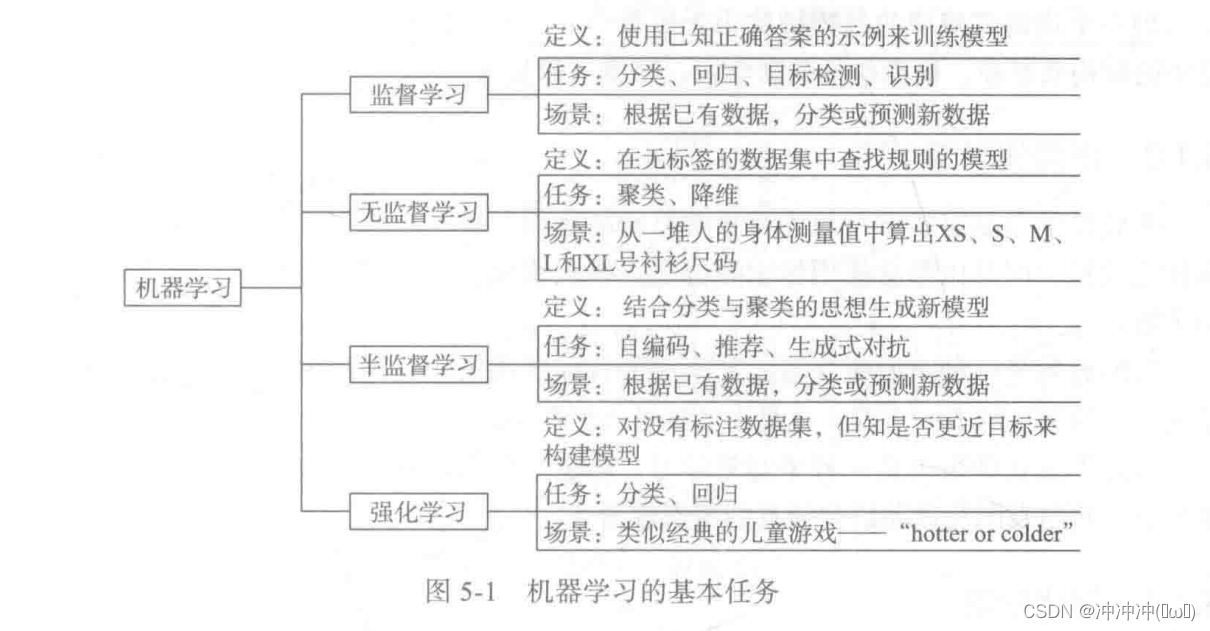
监督学习的任务特点是给定学习目标,整个学习目标就是围绕着如何使预测与目标更接近而来的。其过程图如下:
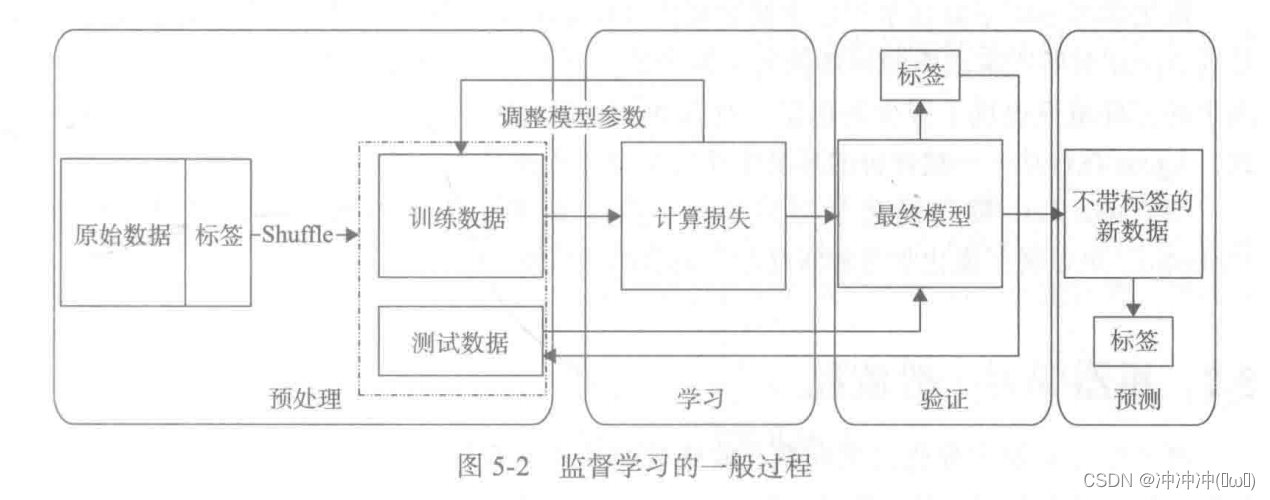
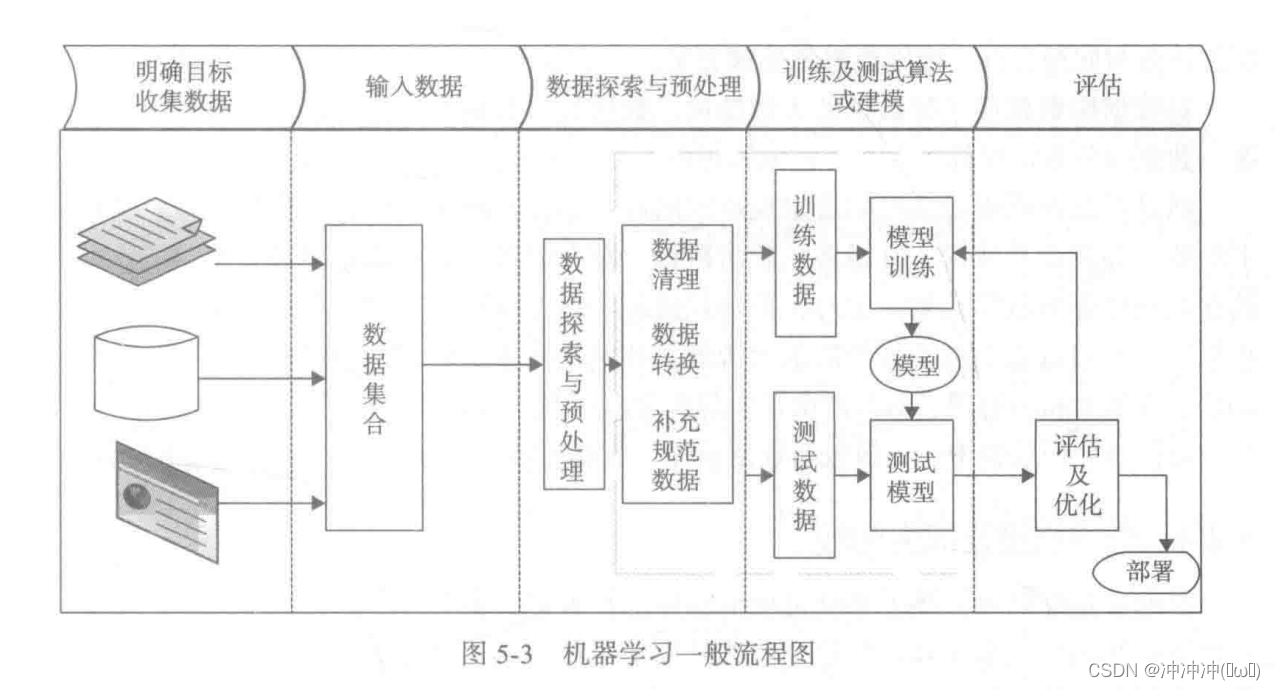
- 机器学习一般流程
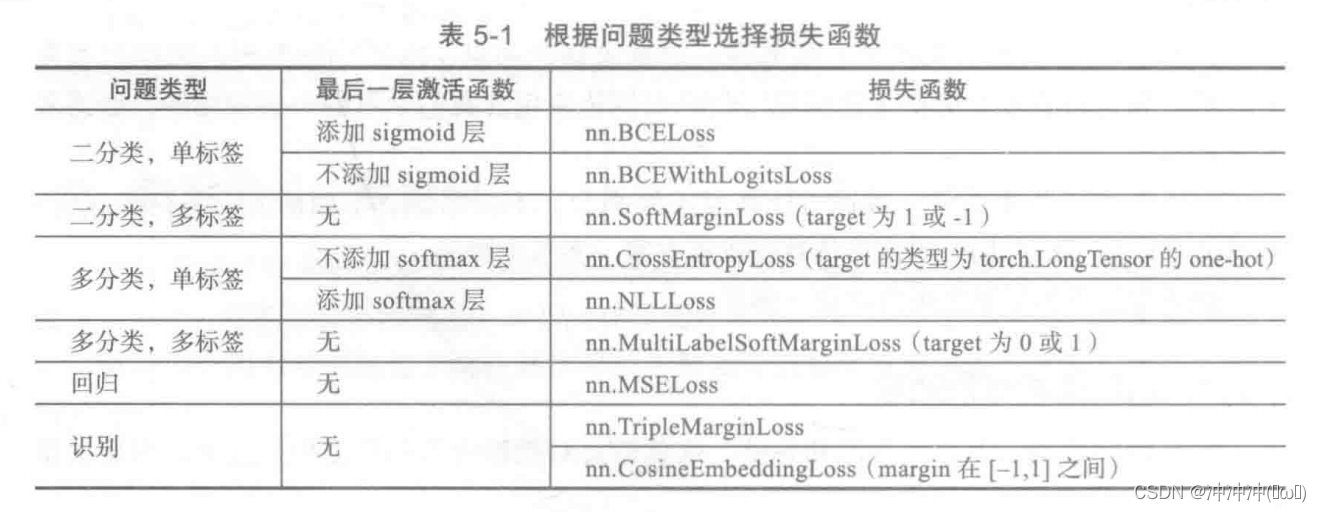
常见问题类型最后一层激活函数和损失函数的对应关系:
常见的评估方法:

- 过拟合与欠拟合
模型确定后,开始训练模型,然后对模型进行评估和优化,这个过程往往是循环往复的。在训练模型过程中,经常会出现刚开始训练时,训练和测试精度不高(或损失值较大),然后通过增加迭代次数或通过优化,训练精度和测试精度继续提升,如果出现这种情况,当然最好。但随着我们训练迭代次数的增加或不断优化,也有可能会出现训练精度或损失值继续改善,但测试精度或损失值不降反升的情况。出现这种情况,说明我们的优化过头了,把训练数据中一些无关紧要甚至错误的模式也学到了。这就是通常说的出现过拟合了。那如何解决这类问题?机器学习中有很多解决方法,这些方法又统称为正则化,接下来我们介绍一些常用的正则化方法。
1、权重正则化
该方法是解决过拟合问题的一个有效方法。直观感受:
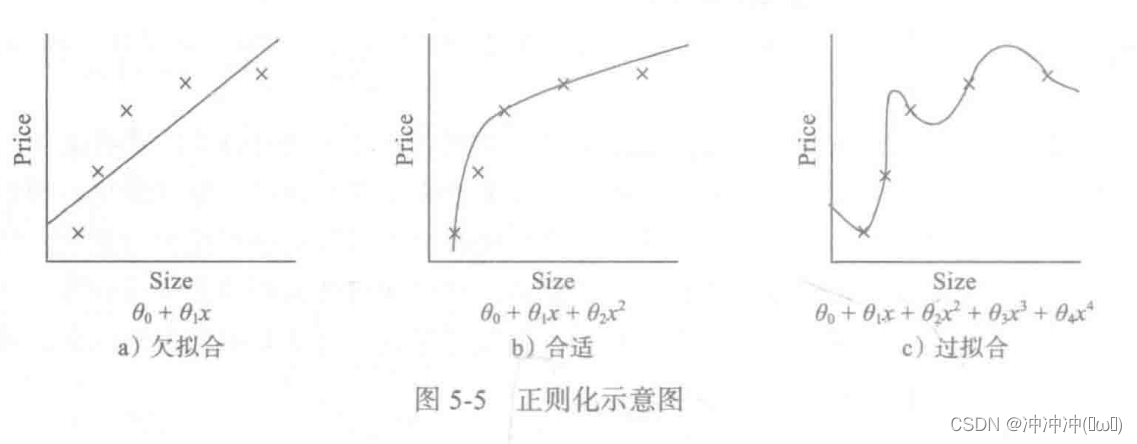
如果要降低模型的复杂度,可以通过缩减它们的系数来实现,如把第3次、4次项的系数3、04缩减到接近于0即可。
那在算法中如何实现呢?这个得从其损失函数或目标函数着手。

这里取10000只是用来代表它是一个大值”。现在,如果要最小化这个新的损失函数,应要让,和04尽可能的小。因为如果你在原有损失函数的基础上加上10000乘以,这一项,那么这个新的损失函数将变得很大,所以,当要最小化这个新的损失函数时,将使。的值接近于0,同样a的值也接近于0,就像我们所忽略的这两个值一样。如果做到这一点(;和04接近于0),那么将得到一个近似的二次函数。
PyTorch如何实现正则化呢?
这里以实现L2为例,神经网络的L2正则化称为权重衰减(Weight Decay)。
torch.optim集成了很多优化器,如SGD、Adadelta、Adam、Adagrad、RMSprop等,这些优化器自带的一个参数weight decay,用于指定权值衰减率。
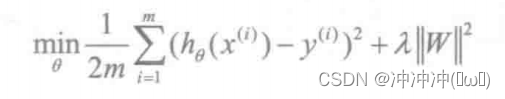
2、Dropout正则化
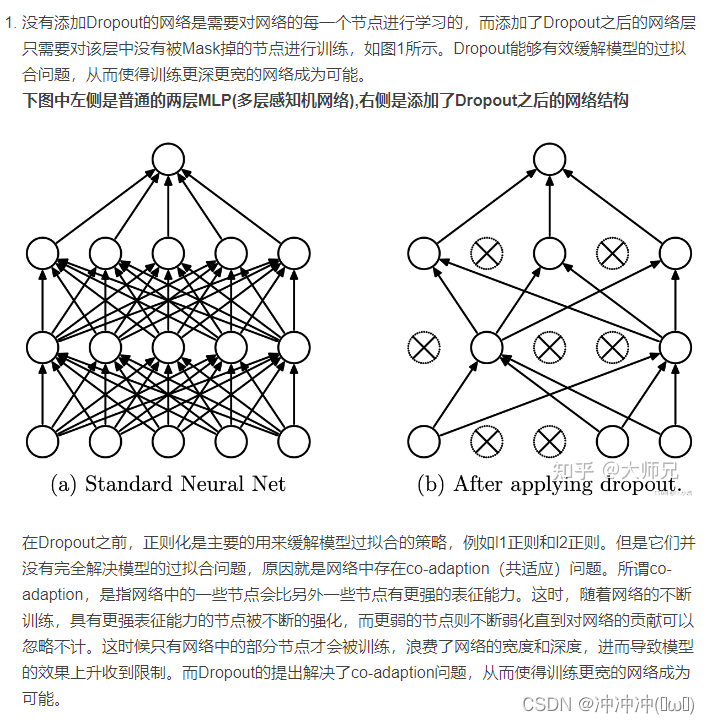
Dropout在训练阶段和测试阶段是不同的,一般在训练中使用,测试时不使用。不过在测试时,为了平衡(因训练时舍弃了部分节点或输出),一般将输出按Dropout Rate比例缩小。

3、批量正则化

4、权重初始化
初始化对训练有哪些影响?初始化能决定算法是否收敛,如果算法的初始化不适当,初始值过大可能会在前向传播或反向传播中产生爆炸的值;如果太小将导致丢失信息。对收敛的算法适当的初始化能加快收敛速度。初始值的选择将影响模型收敛局部最小值还是全局最小值,如图5-10所示,因初始值的不同,导致收敛到不同的极值点。另外,初始化也可以影响模型的泛化。
如何对权重、偏移量进行初始化?初始化这些参数是否有一般性原则?常见的参数初始化有零值初始化、随机初始化、均匀分布初始、正态分布初始和正交分布初始等。一般采用正态分布或均匀分布的初始值,实践表明正态分布、正交分布、均匀分布的初始值能带来更好的效果。
继承nm.Module的模块参数都采取了较合理的初始化策略,一般情况使用其缺省初始化策略就足够了。当然,如果想要修改,PyTorch也提供了nm.init模块,该模块提供了常用的初始化策略,如xavier、kaiming等经典初始化策略,使用这些初始化策略有利于激活值的分布呈现出更有广度或更贴近正态分布。xavier一般用于激活函数是S型(如 sigmoid、tanh)的权重初始化,而kaiming则更适合于激活函数为ReLU类的权重初始化。
- 选择合适激活函数
常见的激活函数:


在搭建神经网络时,如何选择激活函数?如果搭建的神经网络层数不多,选择sigmoid、tanh、relu、softmax都可以;而如果搭建的网络层次较多,那就需要小心,选择不当就可导致梯度消失问题。此时一般不宜选择sigmoid、tanh激活函数,因它们的导数都小于1,尤其是sigmoid的导数在[0,1/4]之间,多层叠加后,根据微积分链式法则,随着层数增多,导数或偏导将指数级变小。所以层数较多的激活函数需要考虑其导数不宜小于1当然也不能大于1,大于1将导致梯度爆炸,导数为1最好,而激活函数relu正好满足这个条件。所以,搭建比较深的神经网络时,一般使用relu激活函数,当然一般神经网络也可使用。此外,激活函数softmax常用于多分类神经网络输出层。 - 选择合适的损失函数
损失函数(Loss Function)在机器学习中非常重要,因为训练模型的过程实际就是优化损失函数的过程。损失函数对每个参数的偏导数就是梯度下降中提到的梯度,防止过拟合时添加的正则化项也是加在损失函数后面。损失函数用来衡量模型的好坏,损失函数越小说明模型和参数越符合训练样本。任何能够衡量模型预测值与真实值之间的差异的函数都可以叫作损失函数。在机器学习中常用的损失函数有两种,即交叉熵(Cross Entropy)和均方误差(Mean squared error,MSE),分别对应机器学习中的分类问题和回归问题。
pytorch中两个经典的损失函数:
1、torch.nn.MSELoss
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(10)
loss = nn.MSELoss(reduction='mean')
input = torch.randn(1,2,requires_grad=True)
print(input)
target = torch.randn(1,2)
print(target)
output = loss(input,target)
print(output)
output.backward()
2、torch.nn.CrossEntropyLoss
import torch
import torch.nn as nn
torch.manual_seed(10)
1oss=nn.CrossEntropyLoss()
#假设类别数为5
input=torch.randn(3,5,requires grad=True)
#每个样本对应的类别索引,其值范围为[0,4]
target=torch.empty(3,dtype=torch.1ong).random_(5)
output=loss(input,target)
output.backward()
- 选择合适优化器
1、传统梯度优化的不足
传统梯度优化的不足对参数学习率比较敏感,其更新策略可表示为:

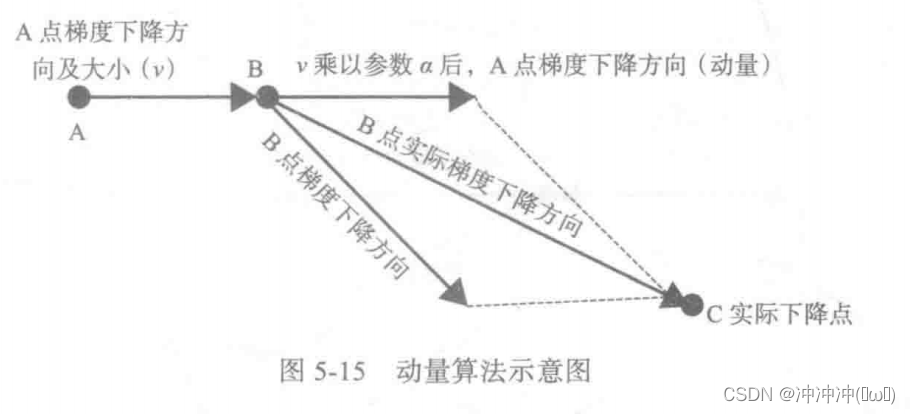
2、动量算法
3、AdaGrad算法、
AdaGrad算法是一种自适应算法,其通过参数来调整合适的学习率,是能独立地自动的调整模型采纳数的学习率,对稀疏参数进行大幅更新和对频繁参数进行小幅更新。
4、RMSProp算法

5、Adam算法


- GPU加速

- 卷积神经网络简介
- 卷积神经网络(CNN)是一种前馈神经网络。
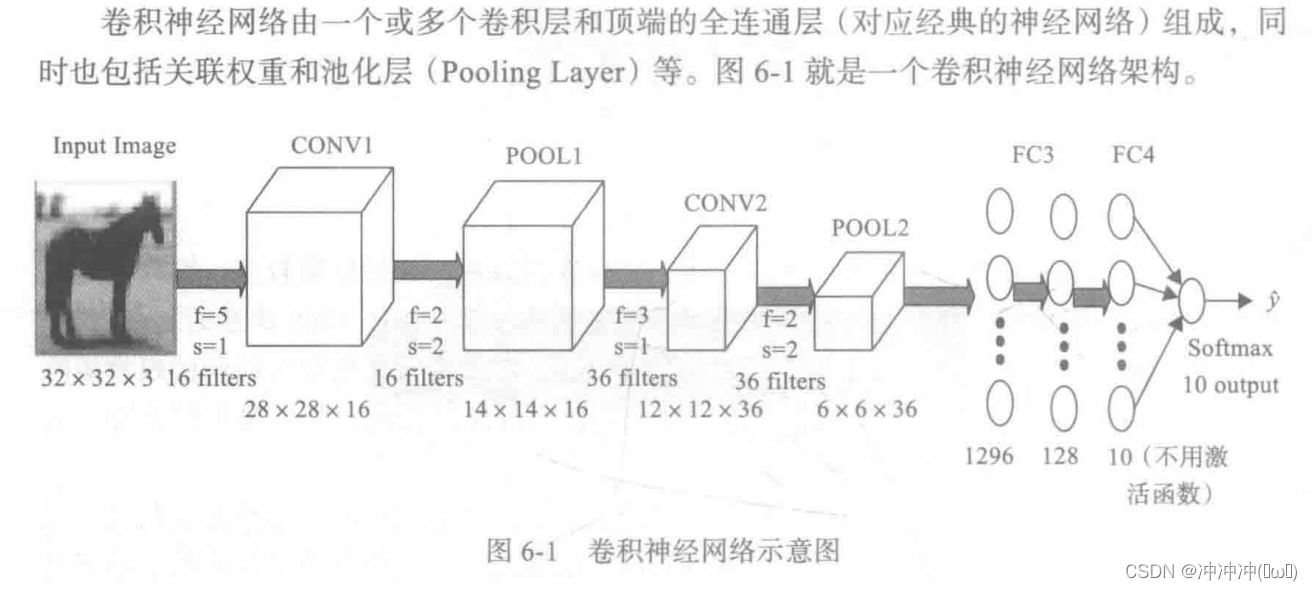
代码定义该卷积神经网络示意图:
import torch
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2 = nn.Conv2d(in_channels=16,out_channels=36,kernel_size=3,stride=1)
self.pool2 = nn.MaxPool2d(kernel_size=2,stride=2)
self.fc1 = nn.Linear(1296,128)
self.fc2 = nn.Linear(128,10)
def forward(self,x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1,36*6*6)
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return x
net = CNNNet()
net = net.to(device)
- 卷积层
卷积层是卷积神经网络的核心层,而卷积又是卷积层的核心。对卷积直观的理解,就是两个函数的一种运算,这种运算就称为卷积运算。二维卷积运算示例如下:
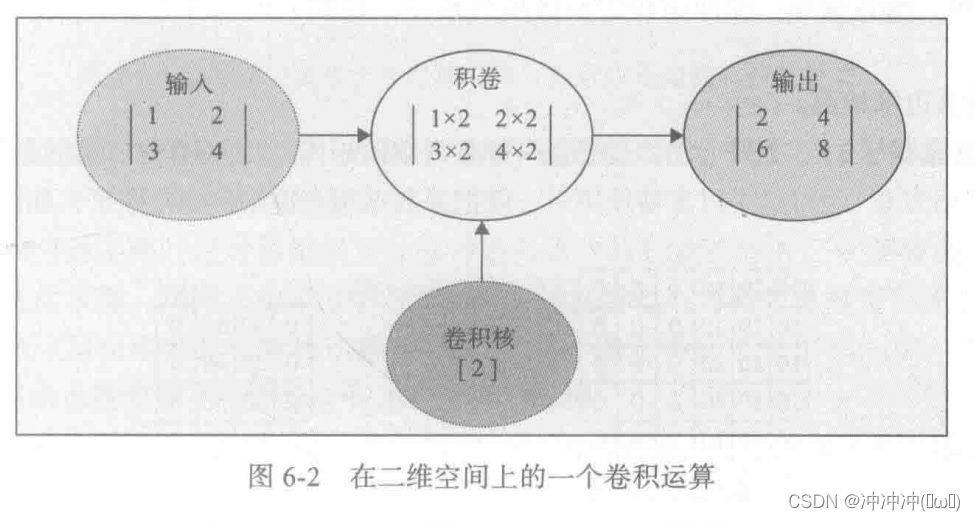
卷积宛如特征提取,卷积核十分重要。卷积核内所有元素和一般为1。一种卷积核一般只能提取一种特征。 - 池化层
池化操作后的结果相比其输入缩小了。池化层的引入是仿照人的视觉系统对视觉输入对象进行降维和抽象。
常见的池化层:
(1)最大池化、平均池化、全局平均池化、全局最大池化。
平均池化(average pooling):计算图像区域的平均值作为该区域池化后的值。
最大池化(max pooling):选图像区域的最大值作为该区域池化后的值。
(2)重叠池化(OverlappingPooling):
重叠池化就是,相邻池化窗口之间有重叠区域,此时一般sizeX > stride。
视频讲解:点击就送
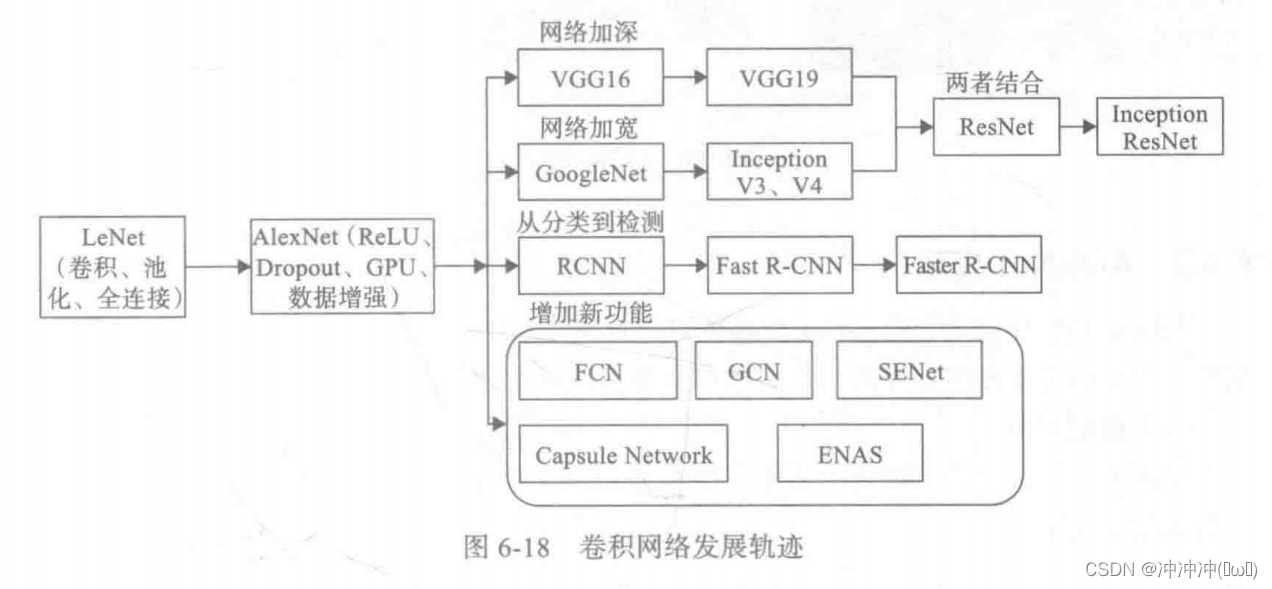
- 现代经典网络
- pytorch实现CIFAR-10多分类

import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
from torch import optim
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(img):
img = img /2 + 0.5
npimg = img.numpy()
# tensor --> numpy
# print(type(npimg))
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
pass
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet, self).__init__()
# 特征图尺寸的计算公式为:(原图片尺寸 - 卷积核尺寸)/步长 + 1
self.conv1 = nn.Conv2d(in_channels=3,out_channels=6,kernel_size=5,stride=1)
#卷积层1 输入是32*32*3 计算(32-5)/1 + 1 = 28 那么通过conv1输出的结果是28*28*6
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
# 池化层1 输入是28*28*6 窗口是2*2 计算28/2=14 那么通过调用之后变成14*14*6
self.conv2 = nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5,stride=1)
# 卷积层2 输入是14*14*6 计算(14-5)/1 + 1 =10 那么通过conv2输出的结果为10*10*16
self.pool2 = nn.MaxPool2d(kernel_size=2,stride=2)
# 池化层2 输入是10*10*16 窗口是2*2 计算10/2=5 那么通过调用之后变成5*5*16
self.fc1 = nn.Linear(16*5*5,120)
# self.fang = nn.Linear(128,10)
# self.fc3 = nn.Linear(1290,10)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1,16*5*5)
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return x
if __name__ == '__main__':
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 模型归一化 使数据到达【-1,1】之间 使模型训练更加的快速 提高准确率
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=16, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# dataiter = iter(trainloader)
# images,labels = dataiter.next()
# imshow(torchvision.utils.make_grid(images))
# print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
net = CNNNet()
net = net.to(device)
# print(net)
# nn.Sequential(*list(net.children())[:4])
# for m in net.modules():
# if isinstance(m, nn.Conv2d):
# nn.init.normal_(m.weight)
# nn.init.xavier_normal_(m.weight)
# nn.init.kaiming_normal_(m.weight)
# nn.init.constant_(m.bias, 0)
# elif isinstance(m, nn.Linear):
# nn.init.normal_(m.weight)
criterion = nn.CrossEntropyLoss()
# SGD 梯度下降算法
optimizer = optim.SGD(net.parameters(),lr=0.001,momentum=0.9)
for epoch in range(15):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# 梯度置零
optimizer.zero_grad()
# 训练
outputs = net(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 累计损失
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d,%5d] loss:%.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print("Finished Training")
# 保存模型
# torch.save(net.state_dict(),'./fang')
# 加载模型
# model =CNNNet()
# model.load_state_dict(torch.load('./fang'))
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images,labels = data
images,labels = images.to(device),labels.to(device)
outputs = net(images)
_,predicted = torch.max(outputs.data,1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images:%d %%' %(100*correct/total))
pass


day6(10月18日)
今日关键词:自然语言处理基础
卷积神经网络利用卷积核的方式来共享参数,这使得参数量大大降低的同时还可以利用位置信息,不过其输入大小是固定的。但是,在语言处理、语音识别等方面,文档中每句话的长度是不一样的,且一句话的前后是有关系的,类似这样的数据还有很多,如语音数据、翻译的语句等。像这样与先后顺序有关的数据被称之为序列数据。处理这样的数据就不是卷积神经网络的特长了。对于序列数据,可以使用循环神经网络(Recurrent Natural Network,RNN),它特别适合处理序列数据,RNN是一种常用的神经网络结构,已经成功应用于自然语言处理(Neuro-Linguistic Programming,NLP)、语音识别、图片标注、机器翻译等众多时序问题中。
-
循环神经网络基本结构
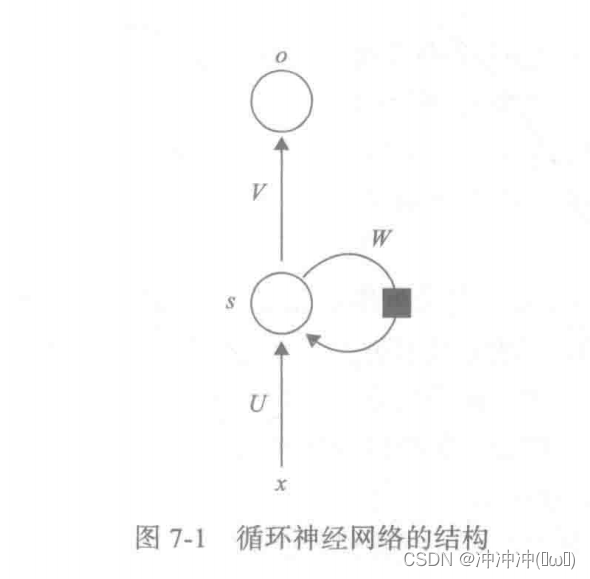
太过于抽象,点击讲解视频 -
LSTM
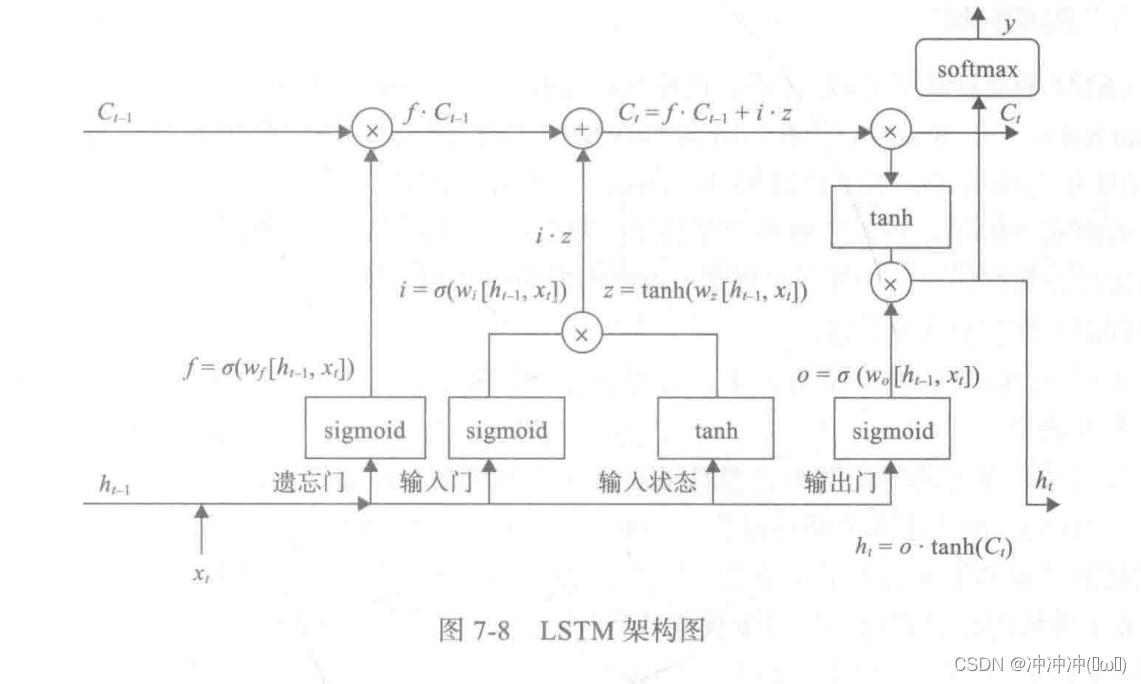
-
GRU
-
Bi-RNN
-
循环神经网络的PyTorch实现
- RNN实现

这是一个典型的RNN网络,使用pytorch实现这个神经网络
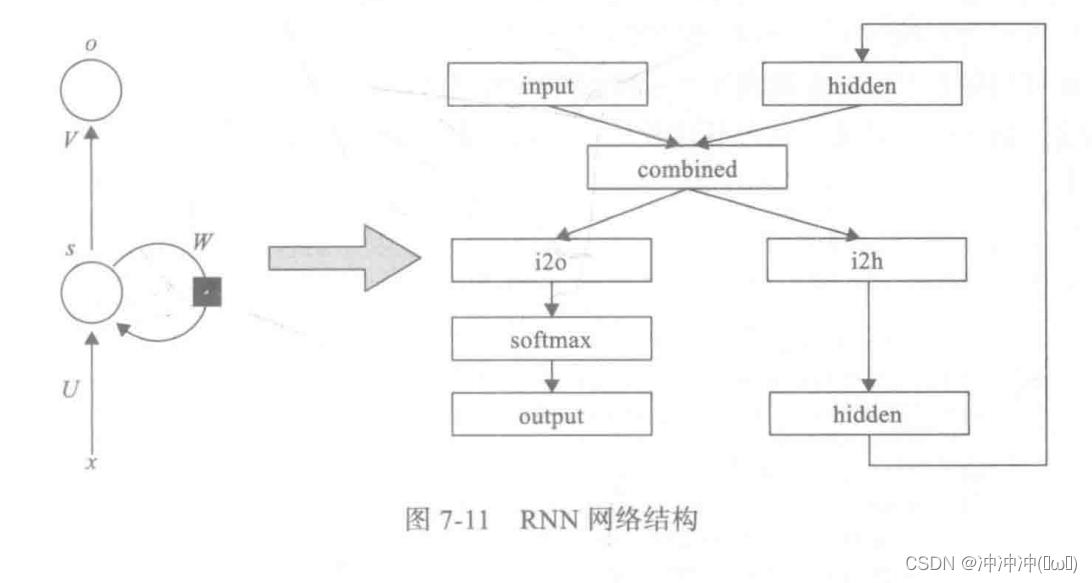
- RNN实现
import torch
import torch.nn as nn
class RNN(nn.Module):
# 定义一种循环神经网络
def __init__(self,input_size,hidden_size,output_size):
super(RNN,self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size,hidden_size)
self.i2o = nn.Linear(input_size + hidden_size,output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forword(self,input,hidden):
combined = torch.cat((input,hidden),1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output,hidden
def initHidden(self):
return torch.zeros(1,self.hidden_size)
- 文本数据处理
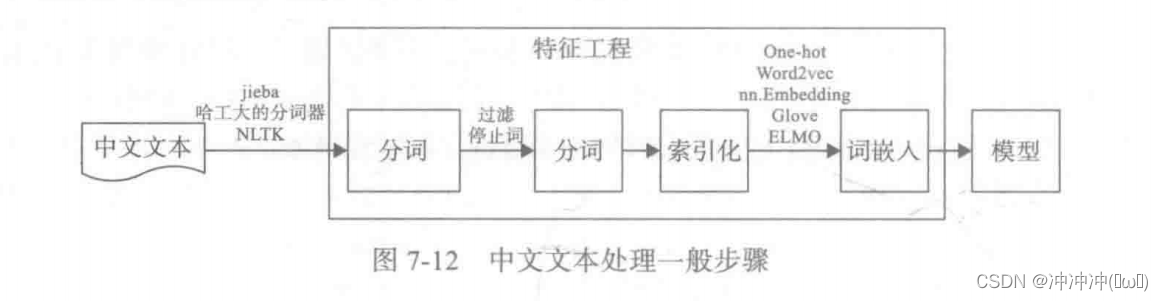
def text_processing():
raw_test = """我爱上海
她喜欢北京"""
stoplist = [' ','\n'] #停用词包括空格 回车符'\n'
words = list(jieba.cut(raw_test))
# 利用jieba进行分词
words=[i for i in words if i not in stoplist]
print(words)
# 去重,然后对每个词加上索引或给一个整数
word_to_ix = {i:word for i,word in enumerate(set(words))}
print(word_to_ix)
# 把整数转换成向量 参数为(词总数,向量长度)
embeds = nn.Embedding(6,8)
lists = []
for k,v in word_to_ix.items():
tensor_value = torch.tensor(k)
lists.append((embeds(tensor_value).data))
print(lists)
- 词性判别主要步骤

import torch
import torch.nn as nn
import jieba
import torch.nn.functional as F
class RNN(nn.Module):
# 定义一种循环神经网络
def __init__(self,input_size,hidden_size,output_size):
super(RNN,self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size,hidden_size)
self.i2o = nn.Linear(input_size + hidden_size,output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forword(self,input,hidden):
combined = torch.cat((input,hidden),1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output,hidden
def initHidden(self):
return torch.zeros(1,self.hidden_size)
def text_processing():
raw_test = """我爱上海
她喜欢北京"""
stoplist = [' ','\n'] #停用词包括空格 回车符'\n'
words = list(jieba.cut(raw_test))
# 利用jieba进行分词
words=[i for i in words if i not in stoplist]
print(words)
# 去重,然后对每个词加上索引或给一个整数
word_to_ix = {i:word for i,word in enumerate(set(words))}
print(word_to_ix)
# 把整数转换成向量 参数为(词总数,向量长度)
embeds = nn.Embedding(6,8)
lists = []
for k,v in word_to_ix.items():
tensor_value = torch.tensor(k)
lists.append((embeds(tensor_value).data))
print(lists)
class LSTMTagger(nn.Module):
def __init__(self,embedding_dim,hidden_dim,vocab_size,tagset_size):
super(LSTMTagger, self).__init__()
self.hidden_dim = hidden_dim
self.word_embeddings = nn.Embedding(vocab_size,embedding_dim)
self.lstm = nn.LSTM(embedding_dim,hidden_dim)
self.hidden2tag = nn.Linear(hidden_dim,tagset_size)
self.hidden = self.init_hidden()
# 初始化隐含状态state及C
def init_hidden(self):
return (torch.zeros(1,1,self.hidden_dim),torch.zeros(1,1,self.hidden_dim))
def forward(self,sentence):
# 获得词嵌入矩阵embeds
embeds = self.word_embeddings(sentence)
# 按LSTM格式 修改embeds的形状
lstm_out,self.hidden = self.lstm(embeds.view(len(sentence),1,-1),self.hidden)
# 修改隐含状态的形状 作为全连接层的输入
tag_space = self.hidden2tag(lstm_out.view(len(sentence),-1))
# 计算每个单词属于各词性的概率
tag_scores = F.log_softmax(tag_space,dim=1)
return tag_scores
pass
def prepare_sequence(seq,to_ix):
idxs = [to_ix[w] for w in seq]
tensor = torch.LongTensor(idxs)
return tensor
def fun1():
# 定义训练数据
training_data = [("The cat ate the fish".split(),["DET","NN","V","DET","NN"]),("They read that book".split(),["NN","V","DET","NN"])]
# 定义测试数据
testing_data = [("They ate the fish".split())]
word_to_ix = {}
for sent,tags in training_data:
for word in sent:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
print(word_to_ix)
tag_to_ix = {"DET":0,"NN":1,"V":2}
EMBEDDING_DIM = 10
HIDDEN_DIM = 3
model = LSTMTagger(EMBEDDING_DIM, HIDDEN_DIM, len(word_to_ix), len(tag_to_ix))
loss_function = nn.NLLLoss()
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
# inputs = prepare_sequence(training_data[0][0],word_to_ix)
# tag_scores = model(inputs)
# print(training_data[0][0])
# print(inputs)
# print(tag_scores)
# print(torch.max(tag_scores,1))
for epoch in range(400):
for sentence,tags in training_data:
model.zero_grad()
model.hidden = model.init_hidden()
sentence_in = prepare_sequence(sentence,word_to_ix)
targets = prepare_sequence(tags,tag_to_ix)
tag_scorex = model(sentence_in)
loss = loss_function(tag_scorex,targets)
loss.backward()
optimizer.step()
inputs = prepare_sequence(training_data[0][0],word_to_ix)
tag_scorex = model(inputs)
print(training_data[0][0])
print(tag_scorex)
print(torch.max(tag_scorex,1))
pass
if __name__ == '__main__':
# text_processing()
fun1()
# EMBEDDING_DIM = 10
# HIDDEN_DIM = 3
# model = LSTMTagger(EMBEDDING_DIM,HIDDEN_DIM,len(word_to_ix),len(tag_to_ix))
- 用LSTM预测股票行情
部分代码如下:
# 1.导入数据
import datetime
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
import tushare as ts
from torch.utils.data import DataLoader
import torch.nn as nn
# 建立连接
cons = ts.get_apis()
#获取沪深指数(000300)的信息,包括交易日期(datetime)、开盘价(open)、收盘价(close),
#最高价(high)、最低价(1ow)、成交量(vo1)、成交金额(amount)、涨跌幅(p_change)
df = ts.bar('000300',conn=cons,asset='INDEX',start_date='2010-01-01',end_date='')
# 删除有null值的行
df = df.dropna()
# 把df保存到目前目录下的sh300.csv文件中 以便后续使用
df.to_csv('sh300.csv')
#查看df涉及的列名
# df.columns
#Index(['code','open','close','high','1ow','vol',‘amount','p_change],
#dtype='object')
#查看df的统计信息
df.describe()
# print(df)
# 预处理数据
# 通过一个序列来生成一个31*(count(*)-train_end)矩阵
# 其中最后一列维标签数据 就是把当天的前n天作为参数 当天的数据作为label
def generate_data_by_n_days(series,n,index=False):
if len(series) <= n:
raise Exception("The Length of series is %d,while affect by (n=%d)."%(len(series),n))
df = pd.DataFrame()
for i in range(n):
df['c%d'%i] = series.tolist()[i:-(n-i)]
df['y'] = series.tolist()[n:]
if index:
df.index = series.index[n:]
return df
# 参数n与上相同 train_end表示的是后面多少个数据作为数据集。
def readData(column='high',n=30,all_too=True,index=False,train_end=-500):
df = pd.read_csv("sh300.csv",index_col=0)
df.index = list(map(lambda x: datetime.datetime.strptime(x,"%Y-%m-%d"),df.index))
df_column = df[column].copy()
df_column_train,df_column_test = df_column[:train_end],df_column[train_end - n:]
df_generate_train = generate_data_by_n_days(df_column_train,n,index=index)
if all_too:
return df_generate_train,df_column,df.index.tolist()
return df_generate_train
# 规范化数据
# 对数据进行预处理 规范化及转换为Tensor
# df_numpy = np.array(df)
# df_numpy_mean = np.mean(df_numpy)
# df_numpy_std = np.std(df_numpy)
# df_numpy = (df_numpy - df_numpy_mean)/df_numpy_std
# df_tensor = torch.Tensor(df_numpy)
# trainset = mytrainset(df_tensor)
# trainloader = DataLoader(trainset,batch_size=batch_size,shuffle=False)
# # 可视化最高价数据
# from pandas.plotting import register_matplotlib_converters
# register_matplotlib_converters()
# # # 获取训练数据 原始数据 索引数据信息
# df,df_all,df_index = readData('high',n=30,train_end=500)
# df_all = np.array(df_all.tolist())
# plt.plot(df_index,df_all,label='real-data')
# plt.legend(loc='upper right')
# 定义模型
class RNN(nn.Module):
def __init__(self,input_size):
super(RNN,self).__init__()
self.rnn = nn.LSTM(
input_size = input_size,
hidden_size=64,
num_layers = 1,
batch_size = True
)
self.out = nn.Sequential(
nn.Linear(64,1)
)
def forward(self,x):
r_out,(h_n,h_c) = self.rnn(x,None)
out = self.out(r_out)
return out
# 训练模型
from tensorboardX import SummaryWriter
writer = SummaryWriter(log_dir='logs')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
rnn = RNN(nn).to(device)
optimizer = torch.optim.Adam(rnn.parameters(),lr=0.001)
loss_func = nn.MSELoss()
day7
今日关键词:生成式深度学习
- 用变分自编码器(VAE)生成图像
定义以下VAE模型:
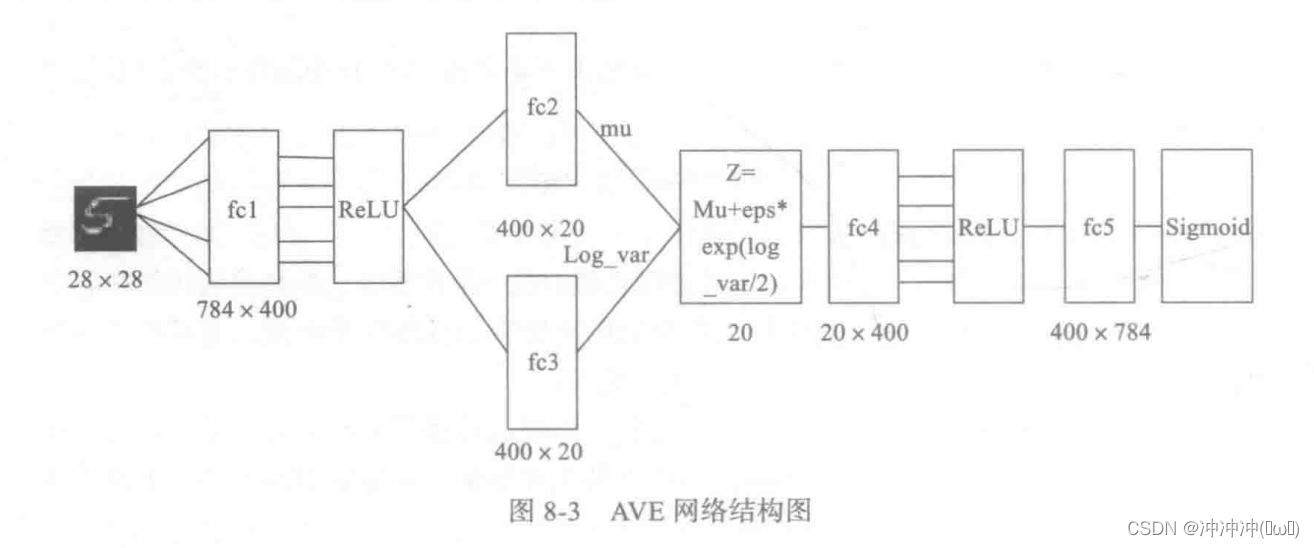
class VAE(nn.Module):
def __init__(self,image_size=784,h_dim=400,z_dim=20):
super(VAE,self).__init__()
self.fc1 = nn.Linear(image_size,h_dim)
self.fc2 = nn.Linear(h_dim,z_dim)
self.fc3 = nn.Linear(z_dim,h_dim)
self.fc4 = nn.Linear(z_dim,h_dim)
self.fc5 = nn.Linear(h_dim,image_size)
def encode(self,x):
h = F.relu(self.fc1(x))
return self.fc2(h),self.fc3(h)
def reparameterize(self,mu,log_var):
std = torch.exp(log_var/2)
eps = torch.randn_like(std)
return mu+eps*std
def decode(self,z):
h = F.relu(self.fc4(z))
return torch.sigmoid(self.fc5(h))
def forward(self,x):
mu,log_var = self.encode(x)
z = self.reparameterize(mu,log_var)
x_reconst = self.decode(z)
return x_reconst,mu,log_var
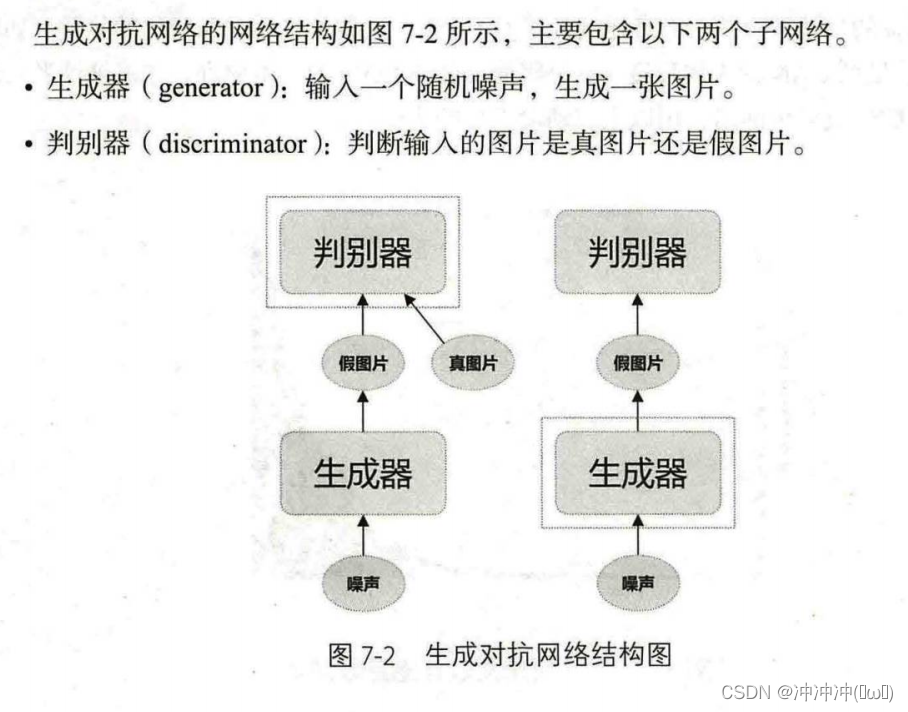
day8(10月21日)

- 优化器
BGD在训练的时候选用所有的训练集进行计算,SGD在训练的时候只选择一个数据进行训练,而MBGD在训练的时候只选择小部分数据进行训练。
这种梯度更新算法简洁,当学习率取值恰当时,可以收敛到全面最优点(凸函数)或局部最优点(非凸函数)。但其还有很大的不足点:
对超参数学习率比较敏感(过小导致收敛速度过慢,过大又越过极值点)。
学习率除了敏感,有时还会因其在迭代过程中保持不变,很容易造成算法被卡在鞍点的位置。
在较平坦的区域,由于梯度接近于0,优化算法会因误判,在还未到达极值点时,就提前结束迭代,陷入局部极小值。 - conv2d(卷积)
conv2d(input,wight,bias=None,stride=1,padding=0,diladion=1,groups=1)
input:表示输入形式 输入形式一般为:N*C*H*W
N:表示批量大小
C:为通道数
H:为图片高度
W:为图片的宽度
weight:就是卷积核 其一般为 D*C*h*w
D:表示输出的特征图的通道数 等于卷积核的个数
其它均为上述一样
bias:表示偏置值 大小等于D
最终输出结果的维度为:N*D*(H-h+1)*(W-w+1)
stride:指的是在输入信号上移动卷积核的步幅大小
padding:指的是输入信号周围填充多少维度的零 其目的就是为了改变输入的形状
nn.Conv2d(in_channels,out_channels,kernel_size)
in_channels:
这个很好理解,就是输入的四维张量[N, C, H, W]中的C了,即输入张量的channels数。这个形参是确定权重等可学习参数的shape所必需的。
out_channels:
也很好理解,即期望的四维输出张量的channels数,不再多说。
kernel_size:
卷积核的大小,一般我们会使用5x5、3x3这种左右两个数相同的卷积核,因此这种情况只需要写kernel_size = 5这样的就行了。如果左右两个数不同,比如3x5的卷积核,那么写作kernel_size = (3, 5),注意需要写一个tuple,而不能写一个列表(list)。
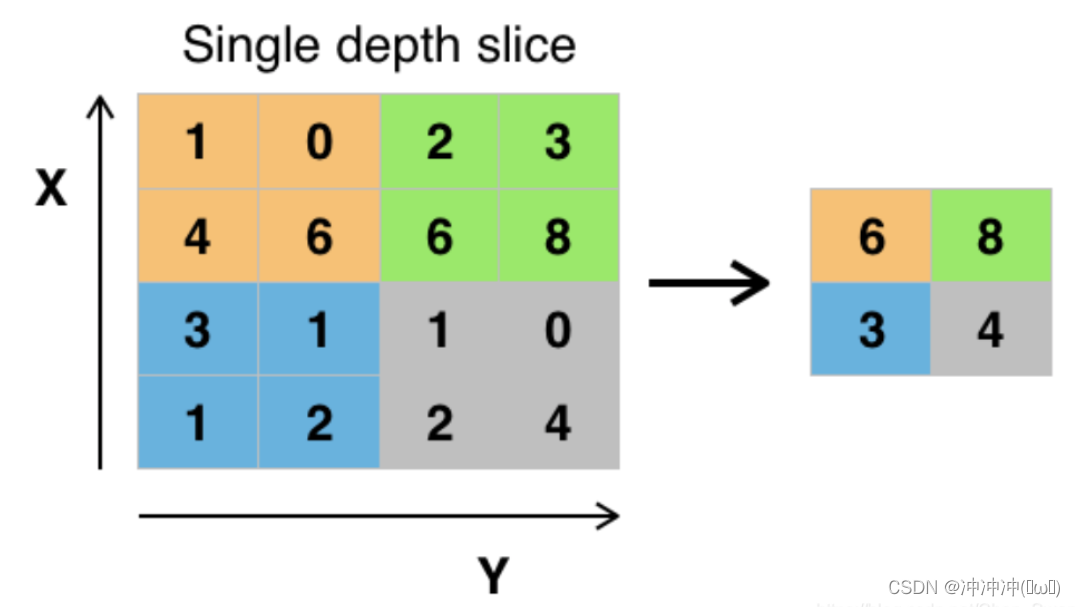
- 池化层(Pooling)
池化是进一步降低数据维度及提取主要特征的步骤
它实际上是一种形式的降采样。有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见的。
它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。直觉上,这种机制能够有效地原因在于,
在发现一个特征之后,它的精确位置远不及它和其他特征的相对位置的关系重要。
池化层会不断地减小数据的空间大小,因此参数的数量和计算量也会下降,
这在一定程度上也控制了过拟合。通常来说,CNN的卷积层之间都会周期性地插入池化层。
其维度计算公式为:N*C*(H/h)*(W/w) 此处全为向下取整

- MNIST分类实战(基于全连接层)
import torch
import torch.nn as nn
from torch import optim
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import torch.nn.functional as F
class MNISTNet(nn.Module):
def __init__(self):
super(MNISTNet, self).__init__()
self.layer1 = nn.Linear(784,100)
self.layer2 = nn.Linear(100,10)
def forward(self,x):
# 输入层到隐藏层 激活函数为tanh
x = self.layer1(x.reshape(-1,784))
x = torch.tanh(x)
# 隐藏层到输出层 使用relu激活函数
x = self.layer2(x)
x = F.relu(x)
# 使用F.log_softmax激活函数 最后计算损失值时要使用NLLLoss负对数似然损失函数
x = F.log_softmax(x,dim=1)
return x
# 定义训练方法
def train_model(model,device,train_loader,optimizer,epoch):
model.train()
# pytorch 自带的训练方法
for batch_index,(data,label) in enumerate(train_loader):
# 部署到device
data,label = data.to(device),label.to(device)
# 梯度初始化为0
optimizer.zero_grad()
# 训练后的后果
output = model(data)
# 计算损失(针对多分类任务交叉熵 二分类用sigmoid)
loss = F.cross_entropy(output,label)
# 找到最大概率的下标
pred = output.argmax(dim=1)
# 反向传播Backpropagation 计算梯度
loss.backward()
# 参数的优化 更新梯度
optimizer.step()
if batch_index % 1000 == 0:
print("Train Epoch : {} \t Loss : {:.6f}".format(epoch, loss.item()))
def tet_model(model,device,test_loader):
# 模型验证
model.eval()
# 统计正确率
correct = 0.0
# 测试损失
test_loss = 0.0
with torch.no_grad(): # 不计算梯度 不反向传播
for data,label in test_loader:
data,label = data.to(device),label.to(device)
# 测试数据
output = model(data)
# 计算测试损失
test_loss += F.cross_entropy(output,label).item()
# 找到概率值最大的下标
pred = output.argmax(dim=1)
# 累计正确率
correct += pred.eq(label.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("Test —— Average loss : {:.4f}, Accuracy : {:.3f}\n".format(test_loss, 100.0 * correct / len(test_loader.dataset)))
if __name__ == '__main__':
transforms = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])
train_data = datasets.MNIST('./data',train=True,download=False,transform=transforms)
test_data = datasets.MNIST('./data', train=False, download=False, transform=transforms)
# data_loader = torch.utils.data.DataLoader(mnist_dataset,batch_size=32,shuffle=True,num_workers=10)
batch_size = 32
train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MNISTNet().to(device)
optimizer = optim.Adam(model.parameters())
for epoch in range(1,21):
train_model(model,device,train_loader,optimizer,epoch)
tet_model(model,device,test_loader)
print("end...")
训练结果后,效果能够达到97%。
- MNIST实战(基于卷积神经网络)
import torch
import torch.nn as nn
from torch import optim
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
import torch.nn.functional as F
class CNN_Net(nn.Module):
def __init__(self):
super(CNN_Net, self).__init__()
self.conv1 = nn.Conv2d(1,8,kernel_size=7)
self.pool1 = nn.MaxPool2d(kernel_size=2)
self.conv2 = nn.Conv2d(8,32,kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(288,100)
self.fc2 = nn.Linear(100,10)
def forward(self,x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool1(F.relu(self.conv2(x)))
x = x.view(-1,288)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return F.log_softmax(x,dim=1)
# 定义训练方法
def train_model(model,device,train_loader,optimizer,epoch):
model.train()
# pytorch 自带的训练方法
for batch_index,(data,label) in enumerate(train_loader):
# 部署到device
data,label = data.to(device),label.to(device)
# 梯度初始化为0
optimizer.zero_grad()
# 训练后的后果
output = model(data)
# 计算损失(针对多分类任务交叉熵 二分类用sigmoid)
loss = F.cross_entropy(output,label)
# 找到最大概率的下标
pred = output.argmax(dim=1)
# 反向传播Backpropagation 计算梯度
loss.backward()
# 参数的优化 更新梯度
optimizer.step()
if batch_index % 1000 == 0:
print("Train Epoch : {} \t Loss : {:.6f}".format(epoch, loss.item()))
def tet_model(model,device,test_loader):
# 模型验证
model.eval()
# 统计正确率
correct = 0.0
# 测试损失
test_loss = 0.0
with torch.no_grad(): # 不计算梯度 不反向传播
for data,label in test_loader:
data,label = data.to(device),label.to(device)
# 测试数据
output = model(data)
# 计算测试损失
test_loss += F.cross_entropy(output,label).item()
# 找到概率值最大的下标
pred = output.argmax(dim=1)
# 累计正确率
correct += pred.eq(label.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("Test —— Average loss : {:.4f}, Accuracy : {:.3f}\n".format(test_loss, 100.0 * correct / len(test_loader.dataset)))
if __name__ == '__main__':
transforms = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])
train_data = datasets.MNIST('./data',train=True,download=False,transform=transforms)
test_data = datasets.MNIST('./data', train=False, download=False, transform=transforms)
# data_loader = torch.utils.data.DataLoader(mnist_dataset,batch_size=32,shuffle=True,num_workers=10)
batch_size = 32
train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNN_Net().to(device)
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.9)
for epoch in range(1,21):
train_model(model,device,train_loader,optimizer,epoch)
tet_model(model,device,test_loader)
print("end...")
训练后准确率能够达到99%。注意模型是如何定义的以及优化器的选择。















 8800
8800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









