







摘要
【目的】 对数据密集型超算的发展历程、主流系统结构、典型应用和计算、存储子系统进行较全面的梳理,指出未来发展趋势,为后续数据密集型超算系统优化提供参考。【方法】 本文首先梳理了数据密集型超算中的关键概念,分析阐述现有平台对数据密集型应用的支持程度。说明了科学界和工业界对数据密集型应用的实际需求情况。并对数据密集型超算的未来发展趋势和面临的潜在挑战进行展望,建立了超算系统评测模型。【结果】 相关研究人员和从业者可从本文快速了解到超算技术的关键概念及发展状况,精准捕捉当下与未来数据密集型超算研究热点和亟待解决的关键问题。【结论】 数据密集型超算存储系统面临的复杂数据类型优化、混合负载优化、多协议支持与互通等将会成为未来一段时间内研究和发展的热点问题。
关键词: 数据密集型超算; I/O密集型超算; 高性能数据分析; 并行处理系统; 超算存储系统
引言
直至上世纪末,超算一直作为解决计算密集型科学和工程问题的高端计算基础设施,是人类社会进步的重要驱动力。
随着超算软硬件技术发展和应用需求变革,其所扮演的角色悄然发生转变。图1给出了2020年中国HPC TOP100中行业应用领域系统数量统计。结果显示用于云计算和大数据处理的系统最多,表明目前应用正转变为以数据密集型为主。
图1

图1 HPC TOP100行业应用分布
Fig.1 HPC TOP100 application distribution
目前学术界对数据密集型任务和计算密集型任务的区分主要有两种认识,AM Middleton认为将大部分执行时间用于计算的任务被视为计算密集型,而用于I/O和数据处理的任务视为数据密集型任务[1]。而Kleppmann认为如果数据问题是一项任务的主要挑战,那这个任务就是数据密集型任务,否则就是计算密集型任务[2]。
当一个任务中处理数据时间占据了大部分整体完成时间时,数据处理一定会成为瓶颈,而瓶颈是提高系统性能关键限制因素[3]。所以,本文认为,数据密集型任务就是一类数据规模海量、数据种类丰富、数据操作频繁、数据处理成为关键瓶颈的应用。
超算的最终目标是服务应用[4],基因测序[5]、智能交通[6]、工程设计[7]、医药健康[8-9]等领域内出现大量需要频繁访问大规模数据的数据密集型任务。
超算平台未来的发展趋势集中体现在计算处理任务数据量骤增、超算系统算力提升且多元化、可靠性及可用性要求变高、超算中心与数据/智算中心深度融合。
超算平台一系列的变化需求对超算存储系统提出了巨大的挑战。不断增长的数据处理需求和相对落后的存储能力在超算领域的矛盾日益凸显,因此本文认为未来超算平台需要统筹兼顾计算密集型任务和数据密集型任务。
本文首先介绍目前典型的数据密集型应用需求,揭示超算平台最新架构演进情况,对当前超算平台中典型并行文件系统进行归纳总结;进一步地,本文梳理了多元算力发展情况,在此基础上总结数据密集型超算所面临的挑战,并展望其未来发展趋势。
1 典型超算平台对数据密集型应用支持程度
本节选取了2021年12月最新TOP 500榜单中的世界排名前十名中的富岳、尖峰、珀尔默特超算,国内排名前两位的神威太湖之光和天河2A超算,以及即将面世的E级超算作为典型超算平台来介绍它们对数据密集型应用的支持程度。
本文从存储带宽、存储容量、数据接口、多元算力支持情况四个维度评判超算平台对数据密集型任务的支持程度。
1.1 富岳
日本基于ARM的富岳(Fugaku)[11,14]超级计算系统被公认为目前世界上最强大的超级计算机。截至2021年6月,该系统因其在大规模科学计算的长期指标上的表现,在全球500款最强大的商用计算机系统的TOP 500排名中名列榜首。与此同时,富岳也兼顾了现代超级计算任务同时强调计算、存储等多种能力的情况,在Graph500[15]、HPL-AI[16]等其他基准测试上也表现出色。
富岳使用基于Armv8.2-A架构的A64FX CPU[17-18]。A64FX是一款具有高计算性能和内存带宽的通用处理器。图2展示出了A64FX的架构图,其具有48个计算核心和2或4个辅助核心,辅助内核处理来自操作系统和通信的中断。用户可以选择2.0或2.2 GHz作为给定作业的CPU频率。A64FX有四个核心内存组(CMG),由12+1个核心和HBM2 (8 GiB、256 GB/s)组成。因为四个CMG由片上网络(NOC)连接,所以对于一般应用,每个节点的进程数应该是4的除数。
图2

图2 A64FX 架构图
Fig.2 A64FX architecture diagram
Fugaku使用Tofu Interconnect网络互连,其拓扑是一个六维网格/圆环体。节点位置可以由XY Zabc轴指定。ac轴是仅由两个节点组成的网格拓扑,其他轴是圆环拓扑。abc轴的尺寸固定在(a,b,c)=(2,3,2),XY Z轴的尺寸取决于系统。因为(X,Y,Z) = (24,23,24),对于Fugaku,节点总数是158,976。图3还显示XY Zb轴使用两个端口,交流轴使用一个端口。A64FX有六个豆腐网络接口(TNIs),能够在六个方向上同时进行6.8 GB/s的通信。
图3

图3 富岳架构
Fig.3 Fugaku architecture
富岳存储分为三层,如图4所示:第一层作为作业执行的专用高性能区域,第二层提供供用户和作业使用的大容量共享区域,第三层提供商业云存储。
图4

图4 富岳存储架构
Fig.4 Fugaku storage architecture
富岳存储系统虽然容量较大和带宽较高,但是对多协议支持不完善,数据接口种类少,元数据性能差,无法支持每秒百万级别文件操作。不支持多元算力,无法针对多元算力场景优化存储性能。
1.2 尖峰
尖峰(Summit)[19⇓⇓⇓-23]由256个机架组成,每个机架有18个IBM Power System AC922计算节点。图5显示了由两个IBM POWER9 CPUs和六个NV-IDIA V100 GPUs组成的节点架构,通过NVLink 2.0连接。中央处理器和图形处理器通过高带宽NVLink连接到超过5TB可寻址存储器。梅兰诺增强数据速率(EDR)无限带宽(IB)以无阻塞胖树拓扑将节点联网。节点内CPU带宽为64 GB/s,GPU带宽为50 GB/s。每个节点都有1.6 TB的本地高速暂存(NVMe)存储,读取带宽为6.0 GB/s,写入带宽为2.1 GB/s。大型高性能全局暂存文件系统以全中心GPFS的形式提供。SummitDev在Summit构建之前是一个早期的可移植性和测试访问系统,有54个IBM POWER8 S822LC计算节点,每个节点有两个IBM POWER8 CPUs和四个NVIDIA特斯拉P100 GPU,通过NVLink 1.0连接。
图5

图5 Summit计算节点架构图
Fig.5 Summit computing node architecture
IBM Summit采用IBM Spectrum Scale存储系统提供存储能力。IBM Spectrum Scale是高性能、高扩展性的文件、对象、块和大数据分析的存储系统,具备随地存储、运行和数据访问能力。Spectrum Scale具有良好的可扩展性、闪存加速性能,以及基于策略的自动存储分层功能(从闪存、磁盘到磁带)。
Spectrum Scale提供了丰富的业务访问能力,如文件接口 (POSIX、NFS、CIFS), 对象接口 (S3、 SWIFT) 、大数据接口Hadoop Distributed File System (HDFS)等,从而更好支持数据密集型应用。
Summit存储规模大、带宽高,具有多协议存储接口,并且支持多元算力,对数据密集型应用支撑较好。
1.3 神威太湖之光
神威[12,24]的系统架构是一个融合体系架构,它一部分面向传统超算的高速计算系统,这一部分偏重计算能力;而另一部分则面向大数据等新型应用的辅助计算系统,这一部分考虑到了存储的问题,但总体来说神威太湖之光依然注重于计算能力,其余的部分只是作为辅助计算系统存在。其系统架构如图6所示。
图6

图6 神威系统架构
Fig.6 Sunway system architecture
系统高速计算部分采用自主可控的神威指令集的SW26010处理器组成,该处理器采用异构众核体系结构,片上计算阵列集群和并行共享存储相结合。其架构图如图7所示。
图7

图7 SW26010处理器架构
Fig.7 SW26010 processor architecture
神威的存储系统[25]由在线存储系统和近线存储系统组成。在线存储系统由带SSD存储服务节点、高性能双控制器光纤串行SCSI盘阵和元数据服务节点组成,负责为用户提供高速可靠的在线数据存储访问服务,其I/O聚合带宽达341GB/s。近线存储系统由元数据服务节点、存储服务节点和大容量光纤存储区域网络组成,负责提供面向云和用户业务的存储服务,如图8所示。
图8

图8 神威存储系统
Fig.8 Sunway storage system
神威太湖之光支持的存储规模较小,带宽也远小于Summit、富岳等系统,且只支撑POSIX接口,也未对多元算力场景进行存储侧优化。因此,难以适应数据密集型应用需求。
1.4 天河2A
天河2A的节点[26]由计算处理模块(CPM)和加速处理器单元(APU)模块两部分组成,CPM模块有4个CPU,APU装有4个Matrix-2000加速器,其逻辑架构如图9所示。
图9
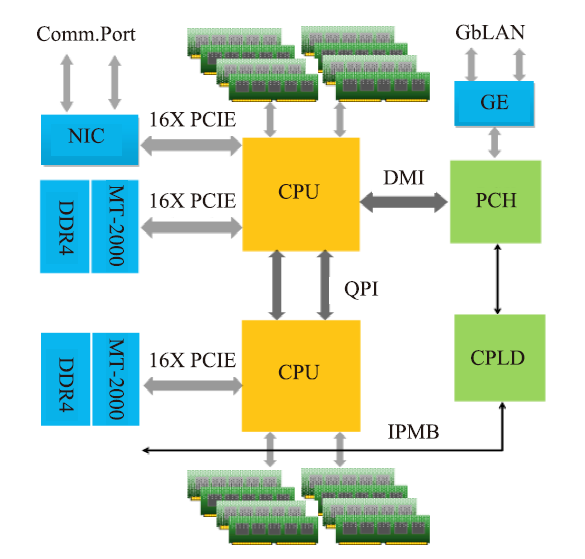
图9 天河2A节点架构
Fig.9 Tianhe 2A node architecture
两个CPU通过intel QPI进行连接,每个CPU有4个内存通道,8个内存插槽,并通过×16 PCI Express 3.0连接到专用网卡和Matrix-2000加速器,每个加速器有8个存储通道。在一个计算节点中,CPU配备64GB的DDR3内存,加速器配备128GB的DDR4内存。
Matrix-2000配置了四个超级节点(SN),它们通过一个可伸缩的片上通信网络连接。每个SN有32个计算核,符合cache一致性要求,支持
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2090
2090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











