






YOLO11+PyQt+MySQL,火灾目标检测模型
1. 前言
大家好,这里是宋大水,今天给大家分享的是火灾目标模型,主要用到的技术包括YOLO目标检测模型、MySQL数据库和PyQt的检测界面。
主要的工作量有登录、注册、图片检测、视频检测和摄像头流的检测,四次对比试验(YOLOv5s,YOLOv8s,YOLO11s,YOLO12s)。为了进一步提升模型的性能,还在表现最好的yolo11s模型的基础上进行改进优化,加入了SE注意力机制和修改损失函数为WIOU。
2. 项目展示
2.1 五次对比试验
| P | R | mAP | mAP50-95 | 参数量(M) | |
| YOLOv5s | 0.637 | 0.642 | 0.67 | 0.341 | 17.6 |
| YOLOv8s | 0.682 | 0.585 | 0.648 | 0.342 | 21.4 |
| YOLO11s | 0.729 | 0.634 | 0.694 | 0.36 | 18.3 |
| YOLO12s | 0.748 | 0.597 | 0.673 | 0.357 | 18.1 |
| YOLO11+SE+WIOU | 0.736 | 0.617 | 0.702 | 0.363 | 18.3 |
选择了目前主流的v5,v8,11,12这四个模型进行训练,从表中可以看出YOLO11s的最终表现结果最好。在表现最好的yolo11s模型的基础上进行改进优化,加入了SE注意力机制和修改损失函数为WIOU。
2.2 登录界面

这个界面由PyQt设计,具备两个功能,一个是登录功能,一个是注册功能,使用了MySQL数据库,因此我们在登录前首先要配置好数据库,才可以进行注册和登录,登录进去后进行目标检测功能。
2.3 检测界面
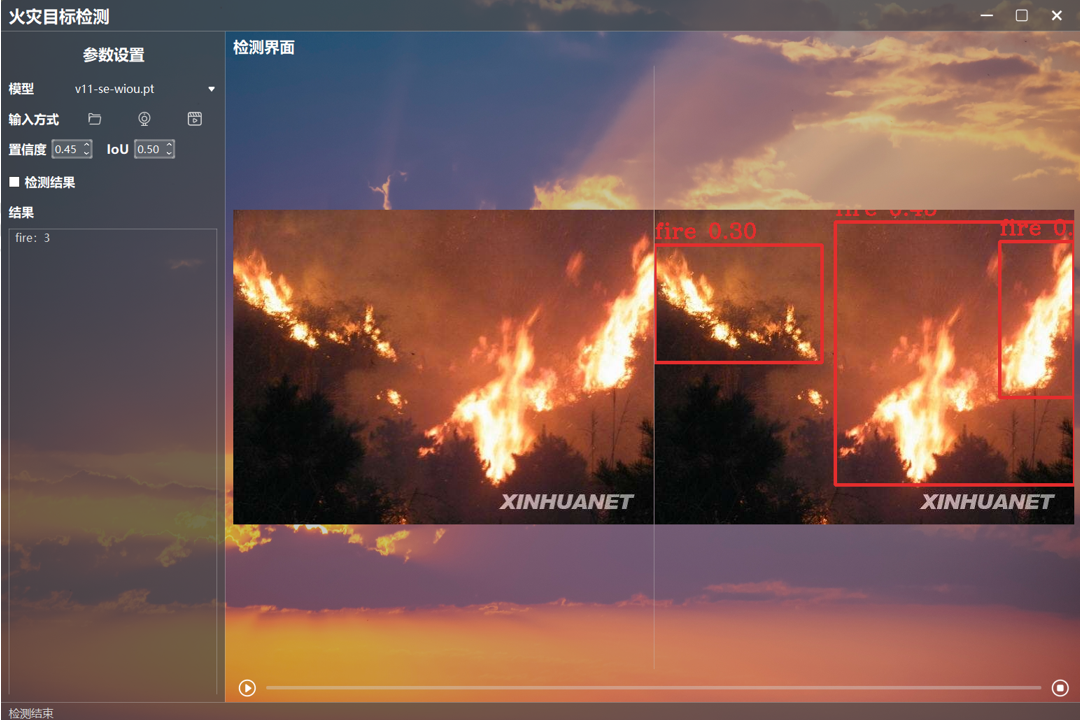
这个检测界面也是由PyQt所设计的,因为我们训练了五次,所以可以选择五个检测模型pt文件,分别是v5,v8,v11,v12和v11-se,选择需要检测的资源,例如图片,视频,摄像头和rtsp流,设置好置信度和IOU,选择是否要将检测结果保存到文件夹,然后点击下方的停止按钮即可开始推理检测。
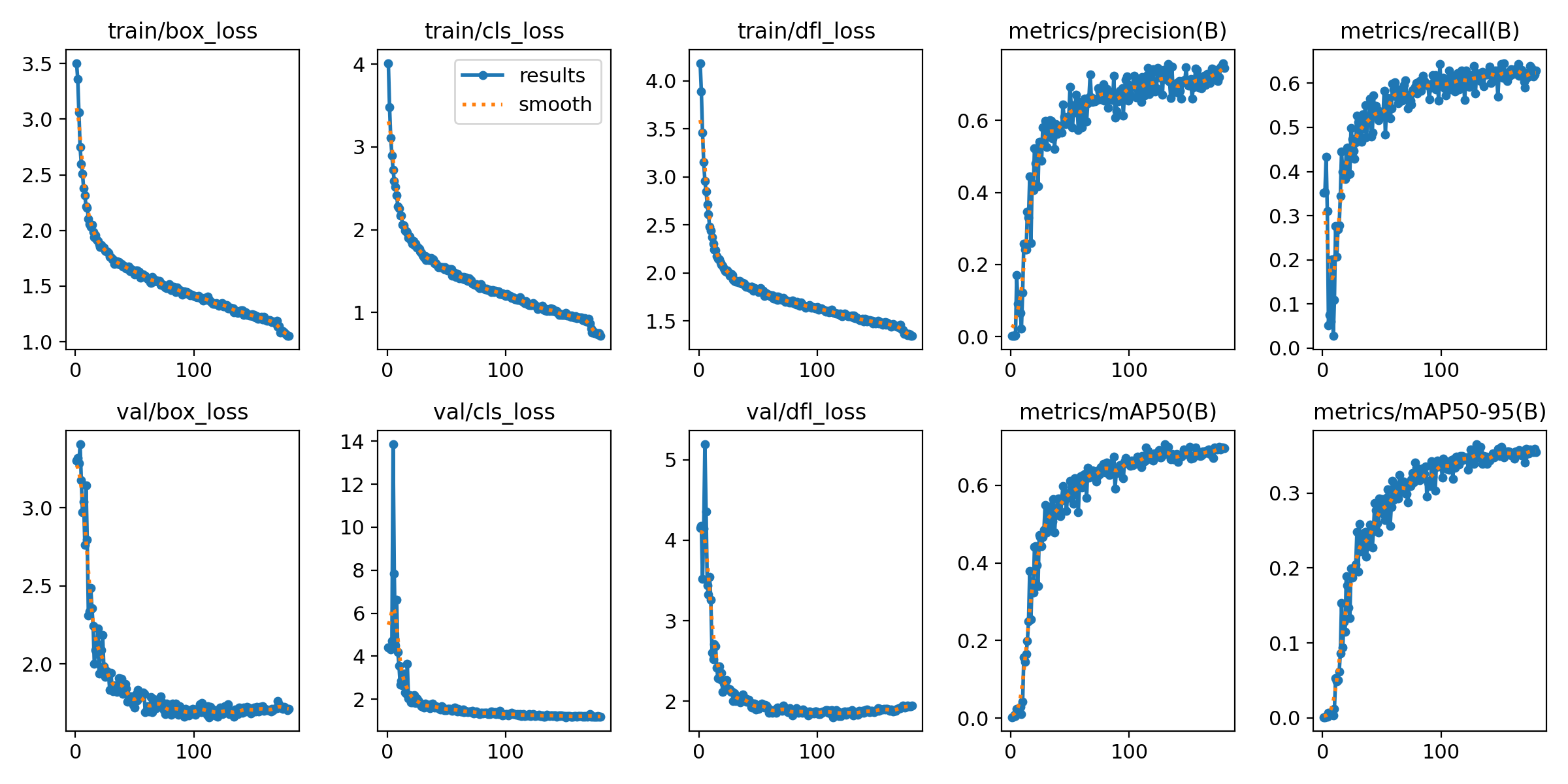
2.4 训练结果部分展示
在这里展示一些表现最好的YOLO11s-se-wiou的重要的训练结果图片(F1曲线、P-R曲线、训练结果和训练图片)。
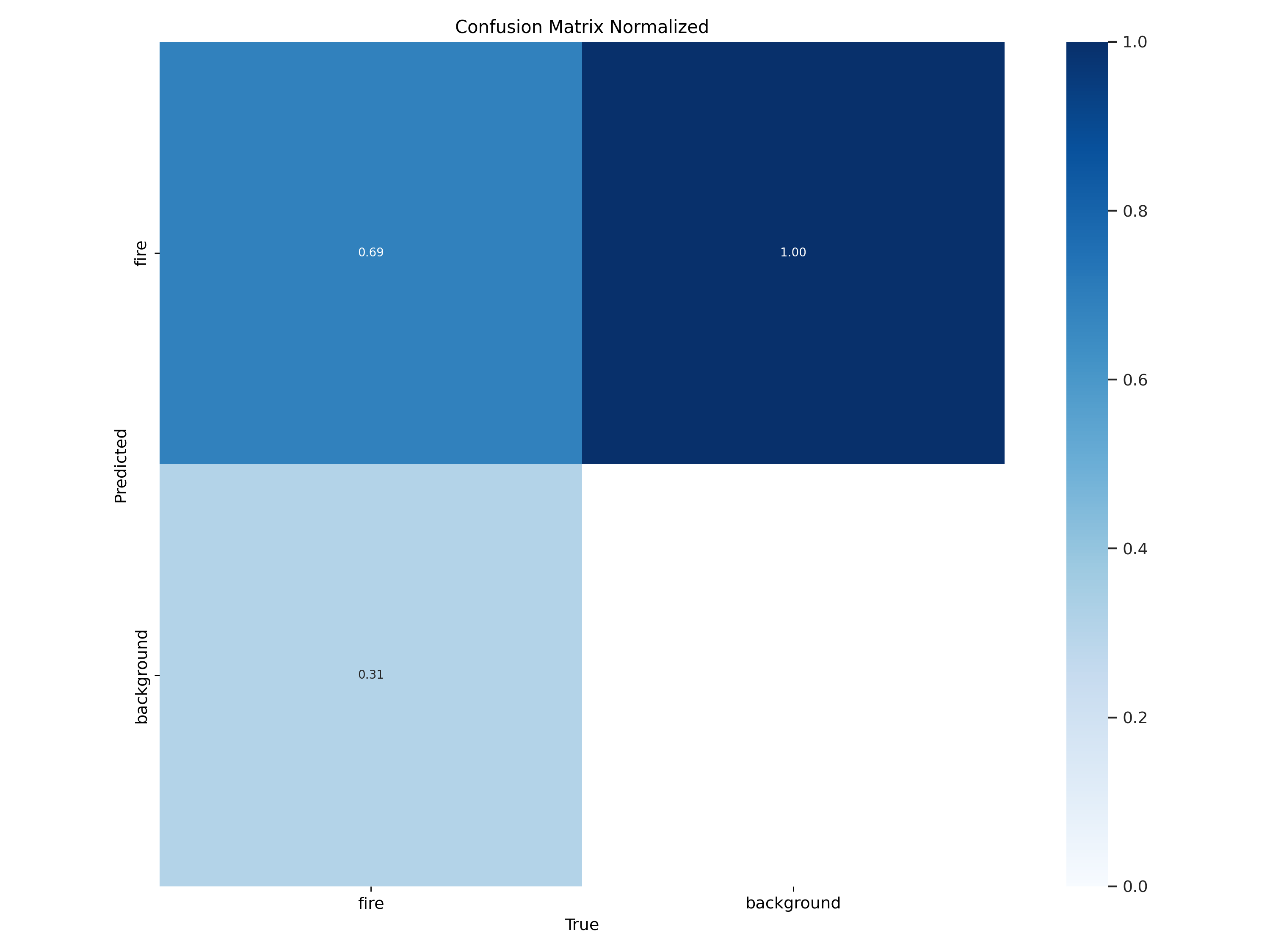
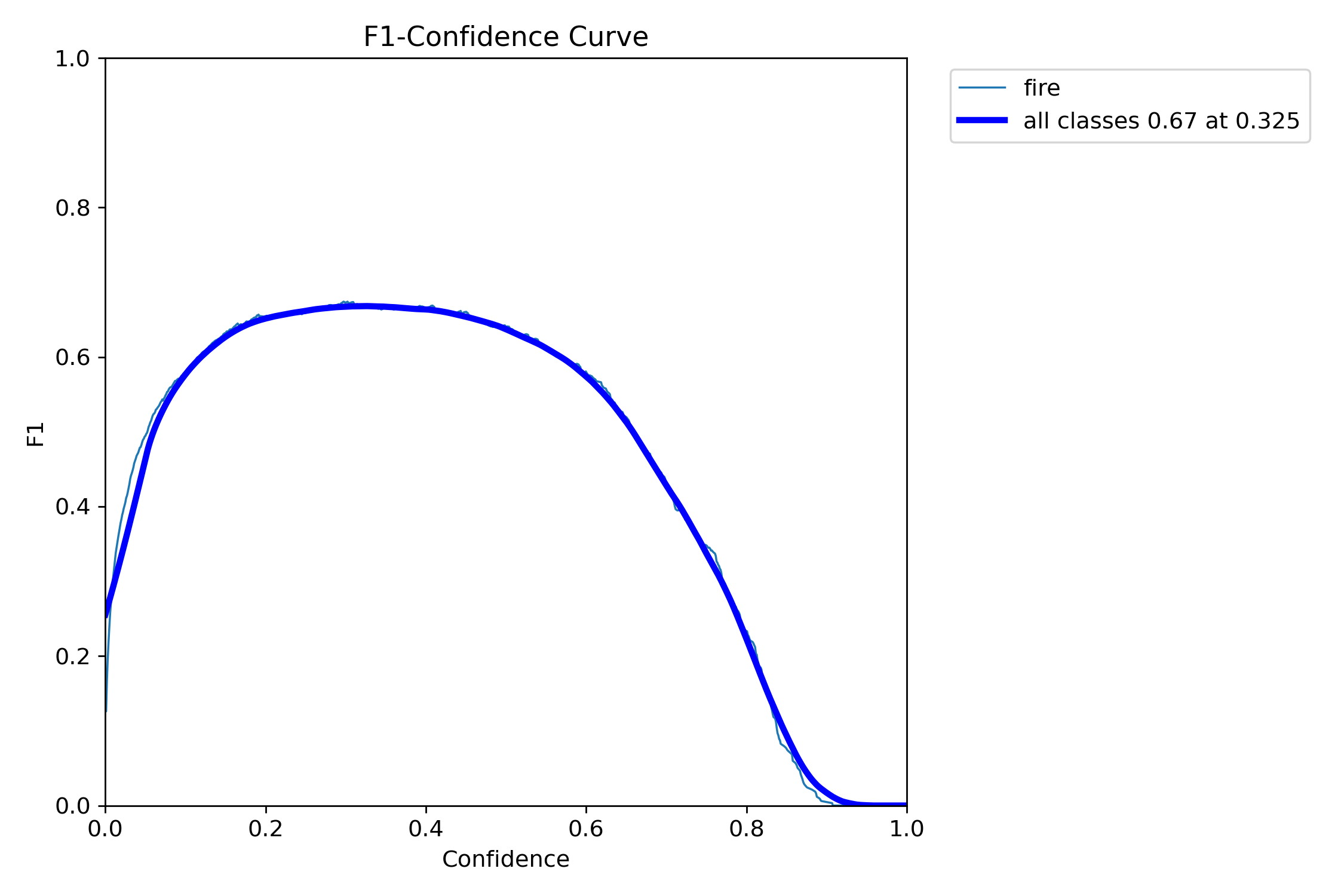
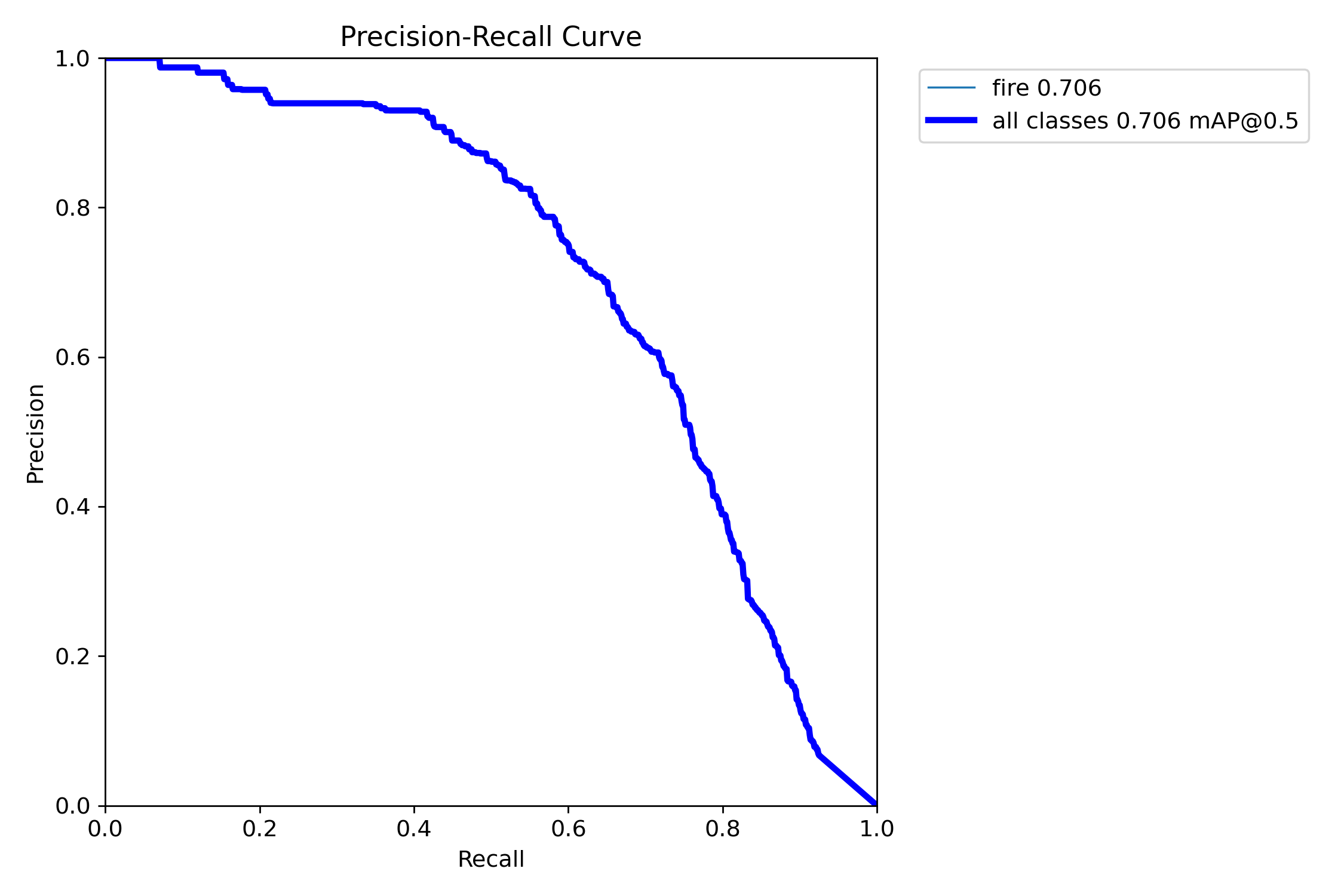

2.5 资源获取
大家可以点击顶端的B站视频评论区置顶链接获取相关资源。

3. 代码运行
3.1 数据集
本实验数据集是一个火灾检测数据集,如下图所示。

3.2 python环境配置
本代码运行需要安装一些深度学习包,例如PyTorch,Torchvision,opencv,ultralytics等。
深度学习环境的三种搭建方式(彻底理解安装逻辑和步骤)
大家可以看上面这个视频学习如何安装深度学习环境。
3.3 mysql数据库
因为登录和注册功能使用到了MySQL数据库,所以我们需要安装配置下这个数据库,只需用该文件中的安装包安装mysql8数据库,然后将下面这个sql语句导入到数据库中,并且配置下LoginWindows.py文件的数据库用户名和密码即可使用。

这就是本次给大家分享的目标检测项目,如需更加详细的信息,可以看置顶的B站视频,谢谢。

















 2136
2136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









