









 Nevergrad是一个由Facebook开源的Python库,专为无导数优化设计,提供了多种优化算法,如差分进化、粒子群算法等,适用于多模态、病态及噪声等问题。它简化了AI研究者在不同设置下比较SOTA算法的流程,并在FAIR的多个项目中得到应用,如强化学习和图像生成。
Nevergrad是一个由Facebook开源的Python库,专为无导数优化设计,提供了多种优化算法,如差分进化、粒子群算法等,适用于多模态、病态及噪声等问题。它简化了AI研究者在不同设置下比较SOTA算法的流程,并在FAIR的多个项目中得到应用,如强化学习和图像生成。
本文翻译自Olivier Teytaud等人于2018年底发布在
code.fb.com上的一篇文章Nevergrad: An open source tool for derivative-free optimization . Nevergrad是一个新颖的东西, 按开发者的意思, 未来要将其纳入到对PyTorch等AI框架的支持中, 这引起了我的一点点兴趣, 下面开始贴正文.
0. 前言
大多数的机器学习任务 — 无论是NLP, 图像分类还是其它 — 都是依赖derivative-free—无导数优化算法[1]优化方法来优化模型的参数以及超参数的, 为了让这类优化方法变得更快和容易使用, Facebook开源了一个Python3的库叫做Nevergrad.
Nevergrad 提供了一大堆不需要梯度计算的优化算法(如CauchyLHSSearch, RandomSearch, and etc):
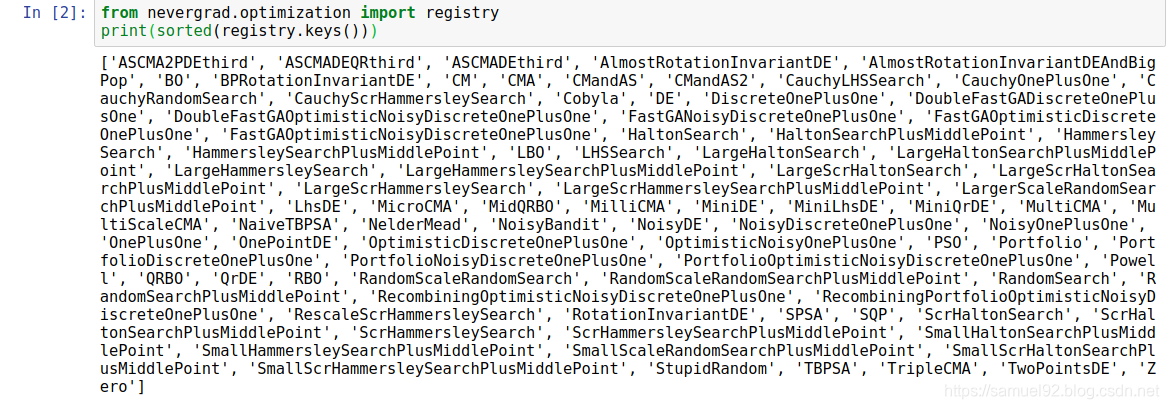
并在Python框架中标准的实现了它们, 使得这些优化算法兼具易用和速度. 此外, Nevergrad 还包含了测试和验证工具, 方便用户使用其内置的调试工具进行调试.
Nevergrad 目前已经可用了, 并且可以立即用作AI研究人员以及工作涉及derivative-free的用户的工具箱(toolbox). Nevergrad允许研究人员实现SOTA (state-of-the-art)的算法并比较它们在不同的设置条件下的性能. 此外, 它还将帮助Machine Learning科学家找到针对特定用例的最佳优化器. 在FAIR(Facebook人工智能研究院: the Facebook Artificial Intelligence Research group), 研究人员将Nevergrad应用于 强化学习、图像生成 和其他领域的各种项目中。例如,它有助于更好地优化ML模型,以取代参数扫描(之前常见的方式是grid search参数搜索)。
Nevergrad包含非常丰富的优化算法, 如:
- Differential evolution. (差分进化)
- Sequential quadratic programming. (逐步二次规划法)
- FastGA.
- Covariance matrix adaptation. (协方差矩阵适应)
- Population control methods for noise management.
- Particle swarm optimization. (粒子群算法)
在Nevergrad出现之前, 使用这些优化算法通常涉及很多自定制部分,这使得比较来自各种最先进方法的结果变得困难或不可能. 而现在, AI开发者们可以很容易地在一个特定的Machine Learning问题上测试许多不同的方法,然后比较结果. 或者,他们可以使用已知的benchmarks来评估新的无导数优化方法(derivative-free)与当前技术状态的比较。
Nevergrad中的无导数优化可以在很多机器学习问题得到使用, 比如:
- 多模态问题.
such as those that have several minima(有多个最小值的问题). (For example, hyperparametrization of deep learning for language modeling.
- 病态问题.
which typically arise when trying to optimize several variables with very different dynamics (for example, dropout and learning rate without problem-specific rescaling).
对于一些参数有非常不同的动力特性: 以深度学习为例, 对特定问题的dropout选择和学习率确定.
-
离散,连续或混合问题. 这些可以包括电力系统(因为一些电厂有可调的连续输出,而另一些电厂有连续或半连续输出),或者具有神经网络的任务,这些任务需要同时选择每一层的学习速率(learning rate)、每一层的权值衰减(weight decay)以及每一层的非线性激活设置(ReLU等)。
-
噪声问题, 比如当使用完全相同的参数调用函数时,函数可能返回不同结果的问题,例如强化学习中的独立事件.
在机器学习中, Nevergrad可以被用于对hyperparameters such as learning rate, momentum, weight decay (possibly per layer), dropout, and layer parameters for each part of a deep network进行tuning. 一般地, 无梯度方法也被用于 电网管理(power grid management) 、航空学(aeronautics) 、透镜设计(lens design) 和许多其他科学和工程应用.
1. The need for gradient-free optimization
在某些情况下,如神经网络权值优化,很容易分析计算函数的梯度。然而,在其他情况下,估计梯度可能是不切实际的——例如,如果函数f的计算速度很慢,或者f的定义域不是连续的。此时, gradient-free或者说derivative-free方法在这些用例中提供了一个新的解决方案。
一个简单的无梯度解决方案是随机搜索(random search),它包括
- 随机抽取大量搜索点
- 对每个搜索点进行评估
- 然后选择最佳搜索点
随机搜索(Random Search) 在许多简单情况下都能很好地执行,但在输入数据维度很高情况下(比如维度为千万级别的推荐系统)就不行了。
网格搜索(Grid Search) 通常用于机器学习中的参数调优,但也存在类似的局限性。然而,有许多替代方法。一些来自应用数学,如序列二次规划,它更新了模拟器的二次逼近。贝叶斯优化还建立了目标函数的模型,包括不确定性模型。
进化计算(Evolutionary computation) 包含了大量关于选择、变异和混合以及变种(variants)的工作。

本例展示了进化算法(evolutionary algorithm)是如何工作的: 1.在函数空间中采样点 2.选择最佳点的总体 3.然后在现有点的基础上提出新的点来改进现有的总体。
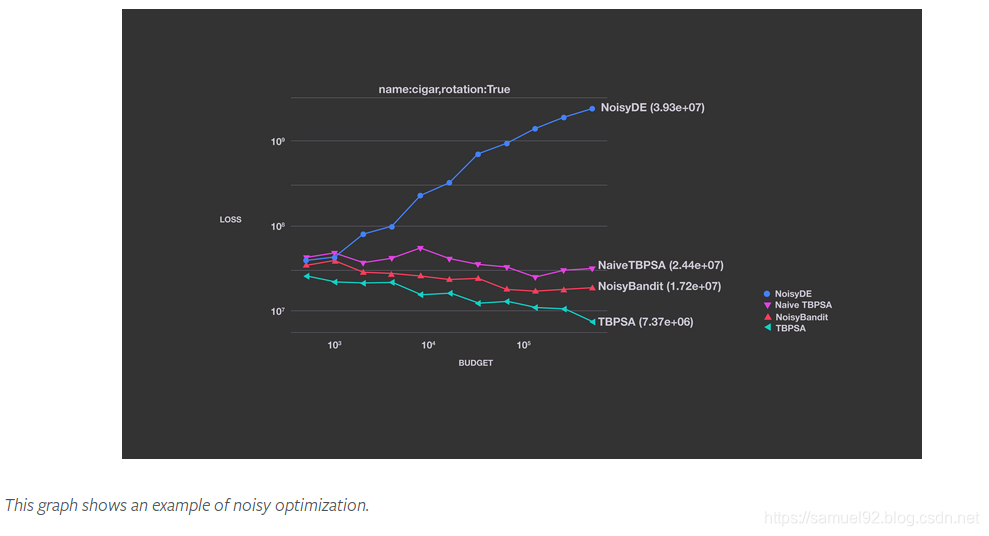
2. Algorithm benchmarks generated with Nevergrad
这部分是使用Nevergrad对一些标准的benchmarks进行评估: 用以确定哪些算法在特定任务中表现最佳. 关于这些例子我就不介绍,详情请看原文[2]
3. Expanding the toolkit for researchers and ML scientists
对于应用来讲, Nevergrad的开发者将会持续努力来让其变得更加容易使用, 并开始探索将其纳入PyTorch框架之中来优化PyTorch强化学习中参数(因为强化学习中的梯度并没有良好的定义)的调整. 此外, Nevergrad有潜力在需要进行**参数扫描(parameter sweep)**的任务中大放异彩. 同样, 对于A/B测试和任务调度等任务也有很大的前景.
作者们还希望与对这些感兴趣的研究人员和开发者们合作, 提出新的工具以及应用.
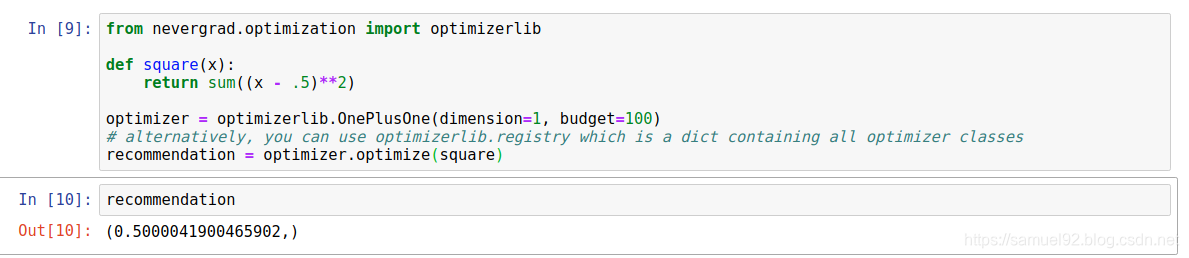
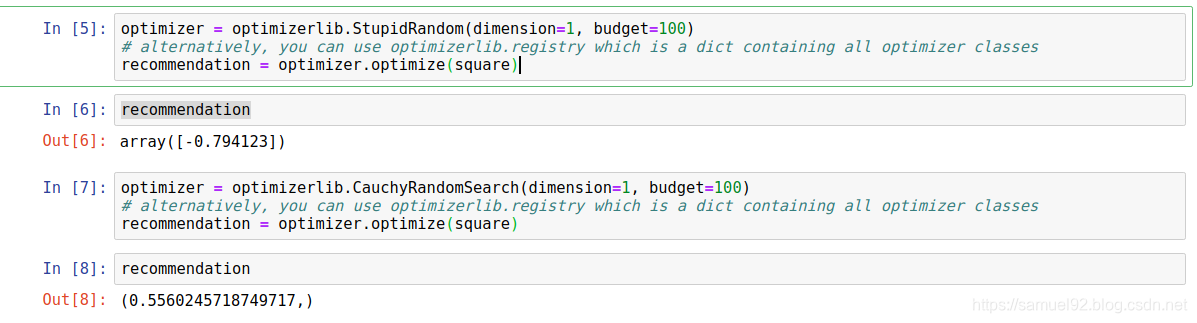
4. 一个hello world级别的例子
以优化一个简单的平方函数为例:
y
=
∑
(
x
−
0.5
)
2
y = \sum (x - 0.5)^2
y=∑(x−0.5)2
我们使用nevergrad.optimization.optimizerlib中的各种优化算法,对这个函数进行优化, 得到结果如下, 可以看出, 在我们使用的3个算法中,OnePlusOne的效果最好,StupidRandom效果最差.
参考资料
[1] Wikipedia: Derivative-free optimization
[2] Nevergrad: An open source tool for derivative-free optimization
[3] Nevergrad: Benchmark Examples

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









