






目录
前言
本人在大学期间接受过一个委托,要求我将一个PSP游戏中关于剧情的文本全部提取出来。由于本人没有相关经验,便在互联网中寻找相关教程。但网上的大多PSP资源提取教程都是关于影像和音频的,关于文本的却寥寥无几。最终从几篇远古文章中,找到思路完成了委托,于是有感而发写下这篇文章。
注意:不同psp游戏的文件结构可能不一样,该文章仅供参考。
一、提取工具
- Windows 11。Windows 10以上的电脑可直接打开PSP游戏文件——光盘映像文件 (.iso),否则得使用第三方软件。
- MadEdit。MadEdit是一款支持多种编码格式和语言的文件编辑器,用于查看文件内容。
- Python 3.10。这个无需多言,不会的话可用其他编程语言代替。
- PSP游戏文件。本文所用到的游戏为《加速世界-银翼的觉醒》。
二、提取步骤
1.找到文本位置
双击打开游戏文件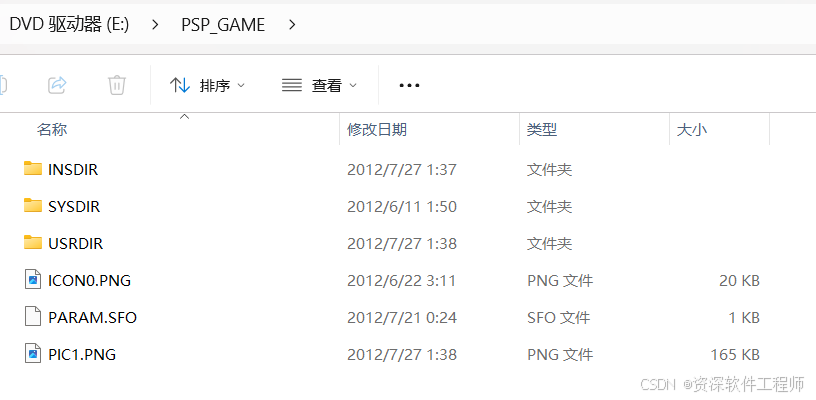
映入眼帘的是三个文件夹和三个文件。先看文件,png是图片,剩下那个1KB里面肯定没有什么。然后三个文件夹,第一印象INSDIR应该和内部(不知道是什么)有关,SYSDIR应该和系统有关,USRDIR应该和用户有关。三个文件夹我都仔细看过,直接说结论,最后在INSDIR里面找到的文本。
双击打开INSDIR文件夹
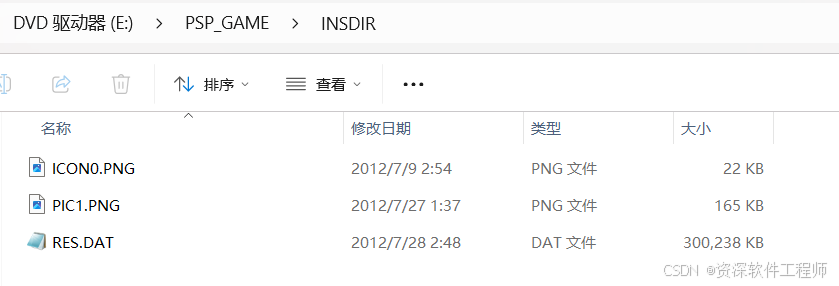 又是几个文件,这次我们直接锁定到RES.DAT这个文件。文件大小大概300MB,RES好像是resource的缩写,直接从这个文件入手。
又是几个文件,这次我们直接锁定到RES.DAT这个文件。文件大小大概300MB,RES好像是resource的缩写,直接从这个文件入手。
使用MadEdit打开RES.DAT

打开一看头都大了,左边十六进制右边乱码加英文字母。这个英文也是好多.dat,第一印象就是一个文件里面又有很多子文件。我会在下面慢慢解释。
①文件魔数,是存储在文件头部的一组特定的字节序列,用于标识文件的格式和类型,这里的是GPDA。
②文件大小,0x12533800字节。

我们把编辑器拉到最底部,发现最后的地址就是0x12533800,如上图所示。
③子文件数量,0x12,也就是十进制18。.dat后缀英文的数量刚好是18个。
④子文件偏移地址。第二行开始为子文件信息,每个子文件信息占0x10字节,也就是一行。这里是第一个子文件偏移地址,为0x0800。
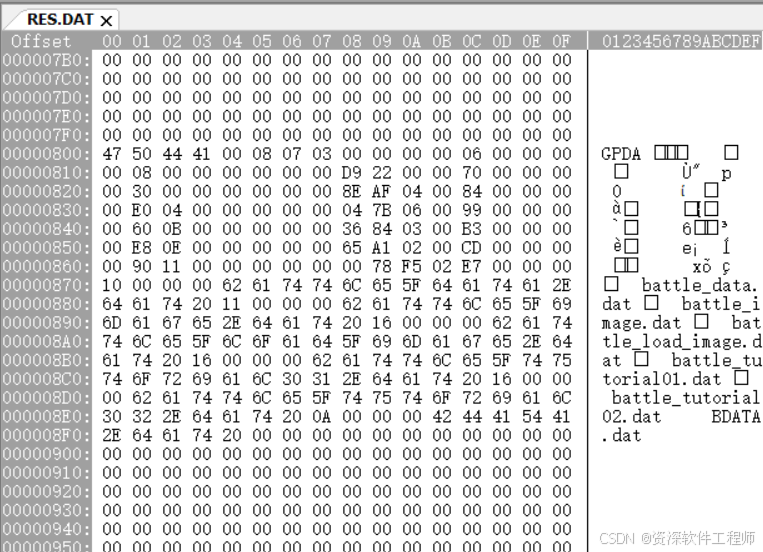
我们把编辑器拉到0x0800处,可以看到GPDA,说明这是一个.dat文件开头,如上图所示。
⑤子文件大小。这里是第一个子文件的大小,为0x03070800字节。
⑥子文件名称相关信息偏移地址。这里是第一个子文件名称相关信息偏移地址,为0x0130,所以第一个子文件名称信息的位置在0+0x0130=0x0130处,详情请看⑦。
⑦子文件名称相关信息。这里为第一个子文件名称相关信息,前4个字节为子文件名称的长度,这里为0x0B个字节长度,文件名结尾固定为0x20。
总的来说,就是一个文件里又有许多子文件,文件头里存储着这些子文件的信息。
把文件结构搞清楚了就可以着手拆包了,Python代码如下。
#dat_unpack.py
import os
import struct
import fnmatch
from tkinter import filedialog
#获取文件夹中所有后缀为.dat的文件位置
def getfn(adr):
flist = []
for root, dirs, files in os.walk(adr):
for name in files:
if fnmatch.fnmatch(name, '*.dat') or fnmatch.fnmatch(name, '*.DAT') :
adr_list = os.path.join(root, name)
flist.append(adr_list)
return flist
# 获取文件夹路径
folder_path = filedialog.askdirectory()
list = getfn(folder_path)
for fn in list:
with open(fn, 'rb') as f:
sig = f.read(4) # 魔数
baseOffset = 0 # 基础地址
f.seek(0x0C)
num = struct.unpack('I', f.read(4))[0] # 子文件个数
if not os.path.isdir(('%s\\' % (fn + '_unpack'))):
os.makedirs(('%s\\' % (fn + '_unpack'))) # 创建个解包文件夹
for i in range(num): # 写个循环
f.seek(0x10 + 0x10 * i)
childOffset = struct.unpack('I', f.read(4))[0] #子文件偏移地址
f.read(4) #跳4个字节
childSize = struct.unpack('I', f.read(4))[0] #子文件大小
childNameOffset = struct.unpack('I', f.read(4))[0] #子文件名称偏移地址
f.seek(baseOffset + childNameOffset)
childNameLength = struct.unpack('I', f.read(4))[0] #子文件名称长度
name = f.read(childNameLength).split()[0].decode('utf-8') # 读取文件名
f.seek(childOffset + baseOffset)
data = f.read(childSize)
new_file_name = '%s_unpack\\%s' % (fn, name)
dest = open(new_file_name, 'wb') # 输出文件
dest.write(data)
dest.close()
这个程序可以把指定目录下的所有.dat(.DAT)文件解包。
运行代码,选择RES.DAT所在文件夹。
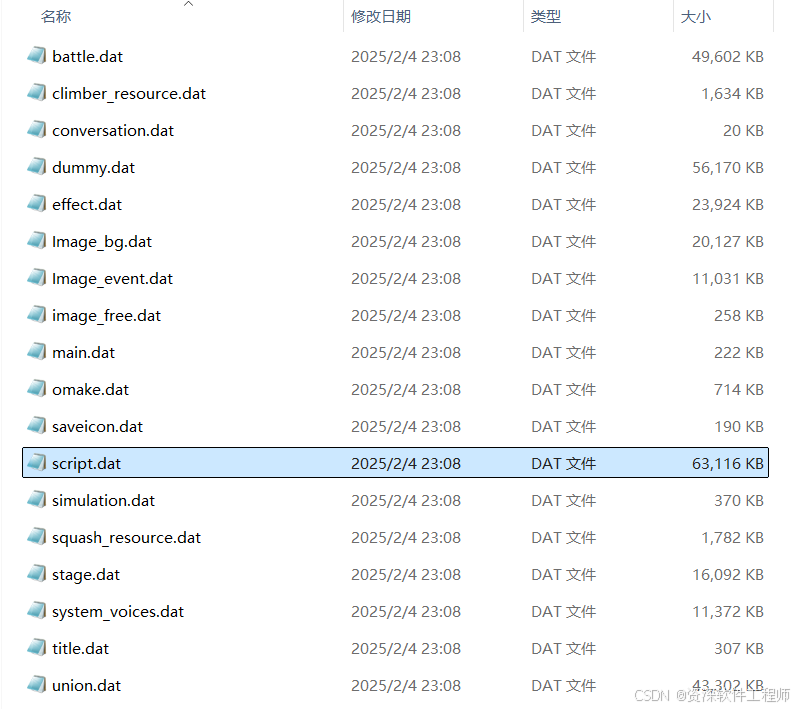
得到了18个.dat文件,但这个script.dat文件引起了我的注意(实际上这些文件我全都看了一遍)。
我们使用MadEdit打开script.dat文件。
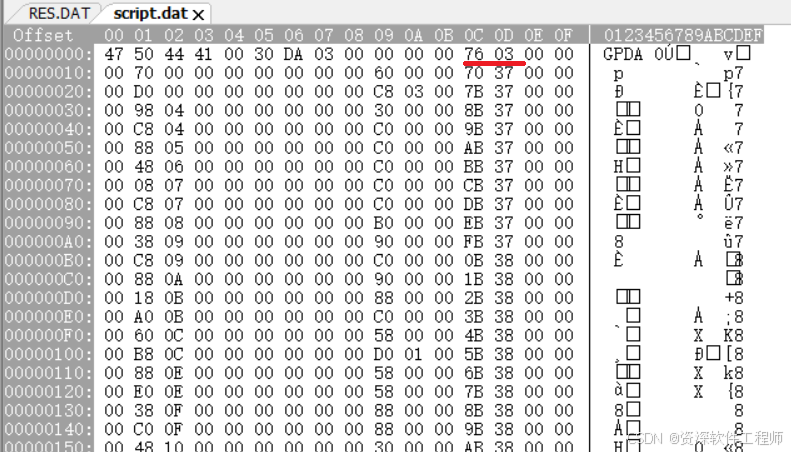
多少?0x0376个子文件。
再解!运行程序,选择script.dat所在文件夹。
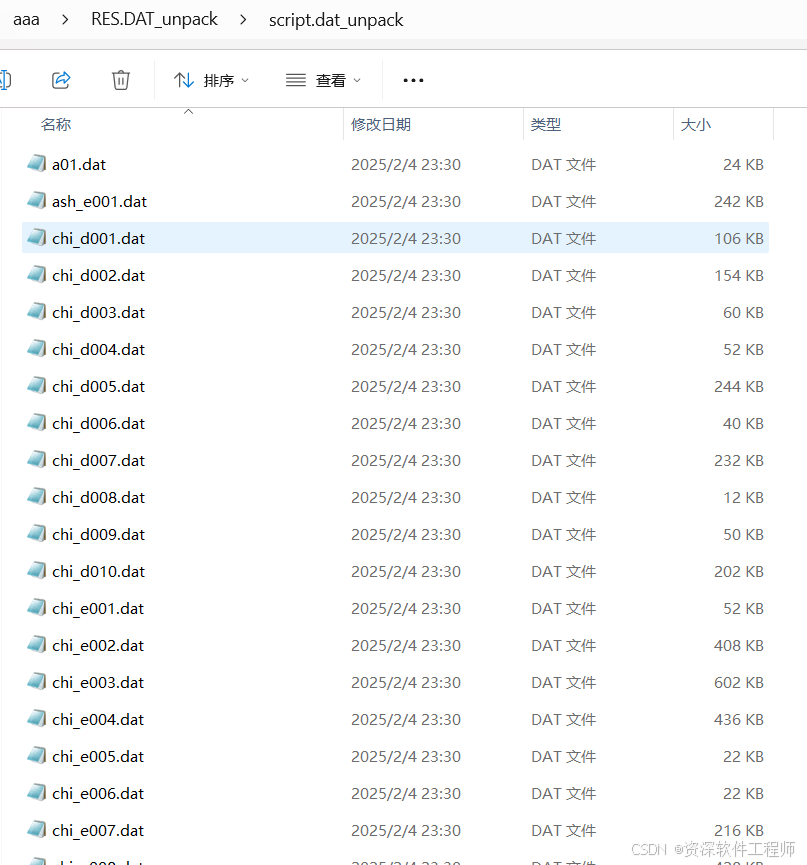
又得到了好多.dat文件,有886个。随便找一个用MadEdit查看,发现又是嵌套文件,又有子文件。
再解!运行程序,选择script.dat_unpack文件夹,把这个文件夹的所有.dat文件都解开。
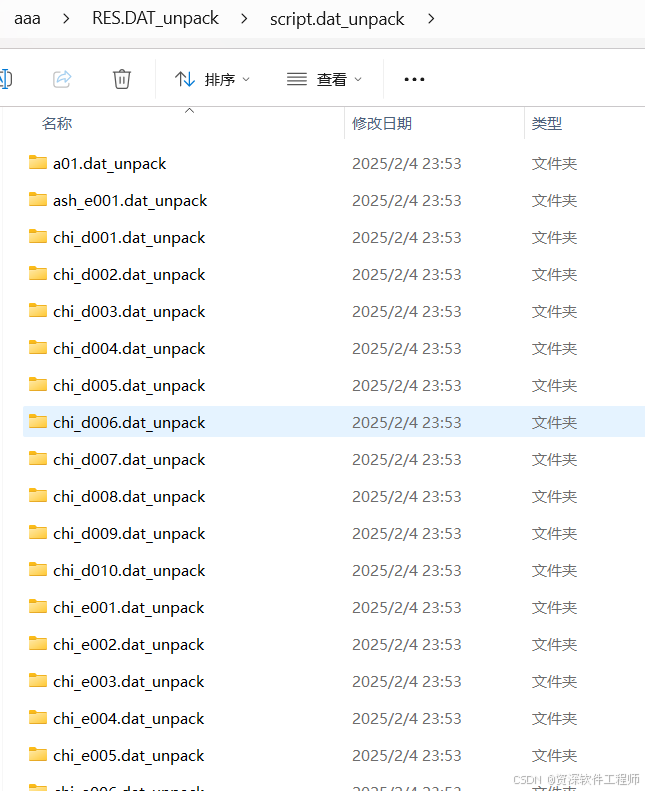
解出来八百多个文件夹。
我们随便打开一个文件夹(这里我打开第二个)。
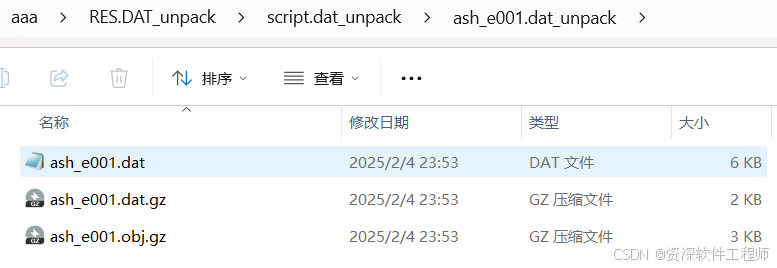
又是三个文件。我用上帝视角告诉大家第一个.dat文件里没有要找的东西,不信可以运行程序再解。
使用MadEdit打开第二个文件。
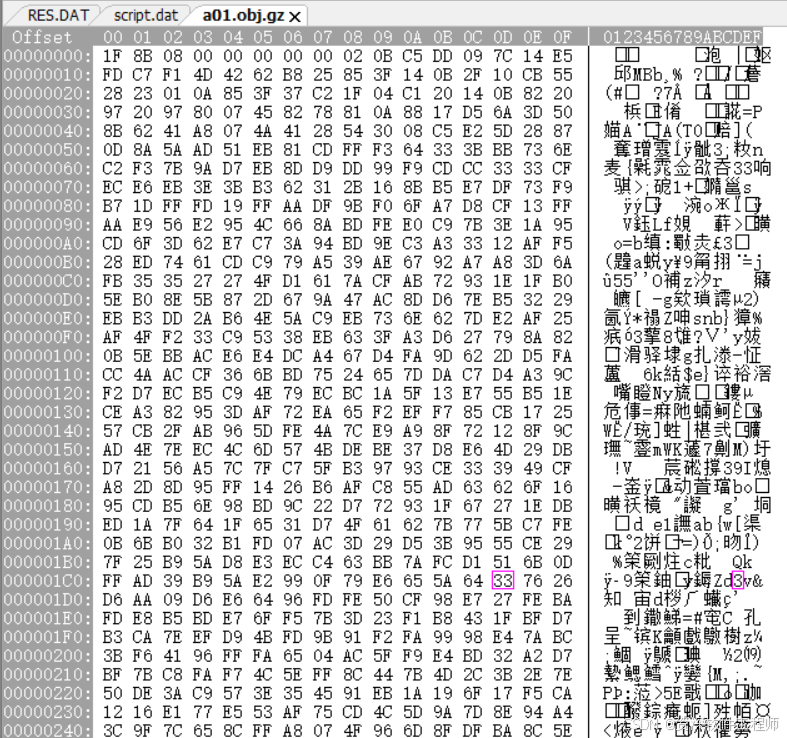
又是左边十六进制右边乱码,如上图所示。头又大了,好像无从下手。把最开头的1F8B08放网上一搜,原来是用gzip压缩了的啊。
写个代码解压缩,Python代码如下。
import gzip
import re
fn = r''#嫌麻烦偷个懒,这里填要解压缩的文件路径
f=gzip.open(fn,'rb')
dat=f.read()
result = re.search("(.*)\.(.*)", fn)
dest = open(result.group(1) + '_unzip.' + result.group(2), 'wb')
dest.write(dat)
f.close()
dest.close()这个程序能把指定gzip压缩文件给解压缩。
对这两个.gz后缀的文件使用解压缩程序。
 多出两个文件。其中.dat_unzip.gz其实又是个嵌套文件,它的子文件都是wav.vol后缀的不是存储文本的文件,这里不再展开。
多出两个文件。其中.dat_unzip.gz其实又是个嵌套文件,它的子文件都是wav.vol后缀的不是存储文本的文件,这里不再展开。
使用MadEdit打开.obj_unzip.gz后缀文件。
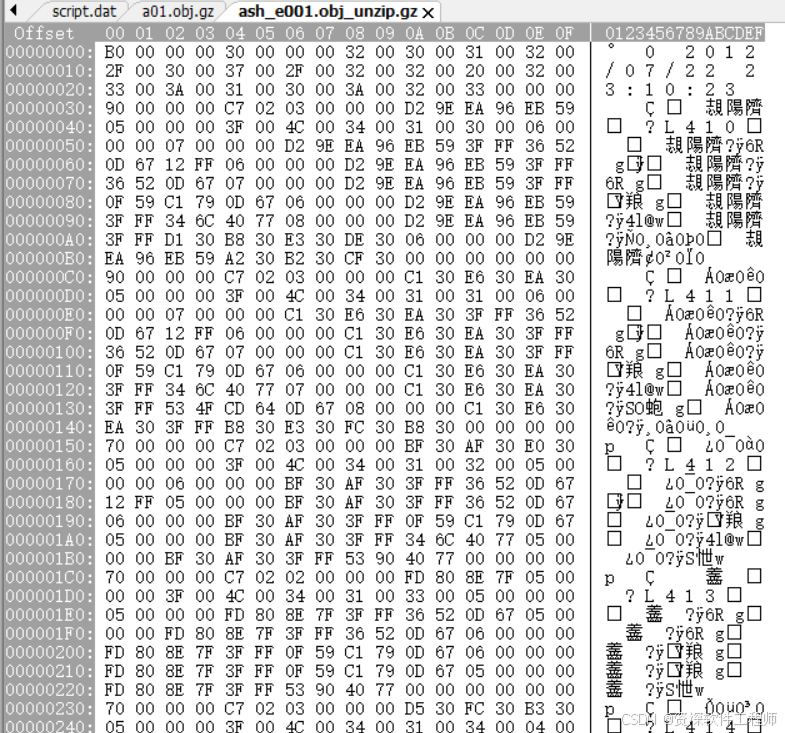
又是乱码,好像折腾这么久半个文本没找着,全是乱码。
试试看换个编码,在MadEdit菜单点击查看,再把编码换成UTF-16LE。
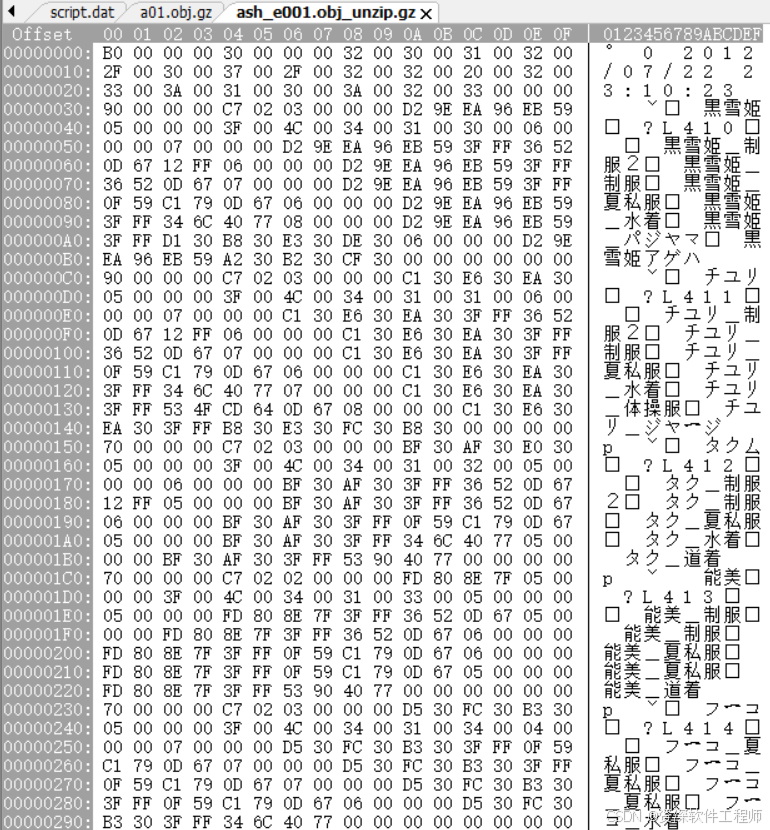
终于看到日文了。
再往下翻。
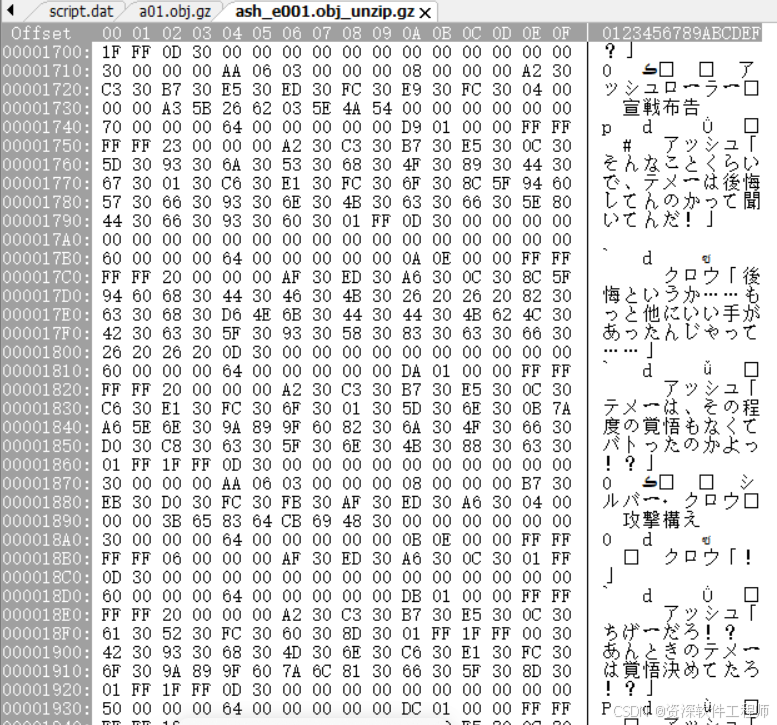
这些不正是对话框里的文本吗,如上图所示。文本位置算是找着了。
2.提取文本
先来分析一下这个剧情文本是怎么存储的
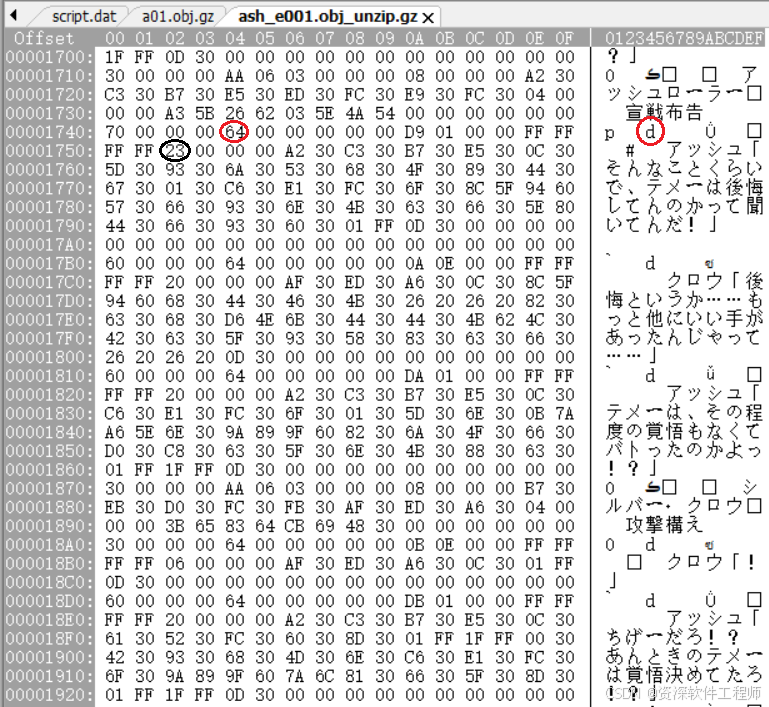
①每段文本前都有一个小写字母d(0x64)。
②d过后的第14个字节,就是文本长度。
③每段文本中必有"「"和"」"。
没找到其他信息了,就只能使用笨方法了,Python代码如下。
import os
import struct
import fnmatch
from tkinter import filedialog
import re
def getfn(adr): #获取当前目录以及子目录下的所有.obj_unzip.gz后缀文件路径
flist = []
for root, dirs, files in os.walk(adr):
for name in files:
if fnmatch.fnmatch(name, '*.obj_unzip.gz') :
adr_list = os.path.join(root, name)
flist.append(adr_list)
return flist
folder = filedialog.askdirectory()
files = getfn(folder)
for fn in files:
size = os.stat(fn).st_size
name = re.search("(.*)\.dat_unpack\\\(.*?).obj_unzip",fn).group(2)
with open(fn,'rb') as f:
dest = open("text/"+name+'.txt', 'wb')
offset = 0x04
n = 1
while size - offset >= 4:
f.seek(offset)
if struct.unpack('I', f.read(4))[0] == 0x64:
f.seek(offset + 0x0E)
length = struct.unpack('I', f.read(4))[0]
f.seek(offset + 0x0E +0x04)
text = f.read(length*2).decode('utf-16')+"\n\n"#实际长度要*2
if length <100 and re.match(".*「(.*)」",text):
dest.write(("## "+str(n)+ " ##\n\n").encode())
dest.write(text.encode())
offset = (offset + length * 2 - 1) // 0x10 * 0x10 + 0x04
n += 1
offset += 0x10这里我直接说逻辑,多的注释我就懒得写了。逻辑就是四个四个字节地读文件,如果读出"0x64"就说明可能有文本在下方。然后读出长度,根据长度再把文本读出。然后再判断读出的文本是否真的是文本,判断逻辑是长度短且包含"「"和"」"字符且"」"是最后一个字符。最后保存至.txt文件。
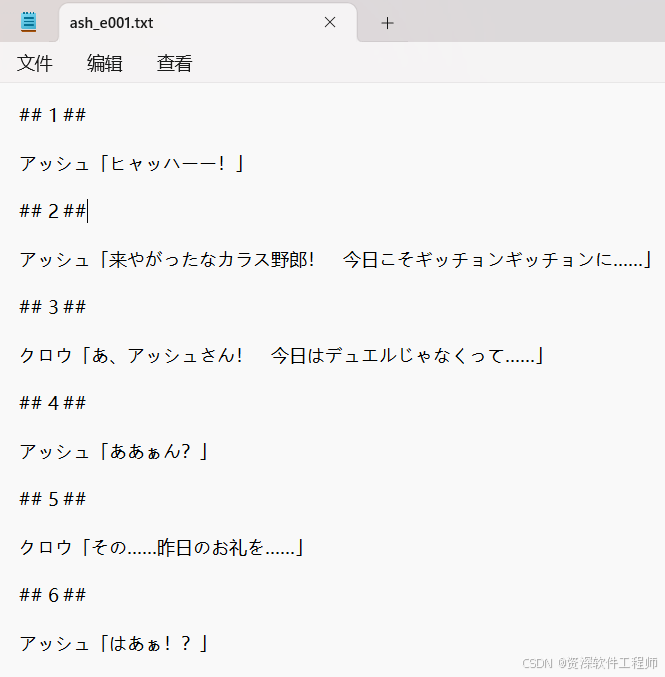
运行程序,最终结果(只是其中一部分)如下。
总结
以上就是今天要讲的内容,本文介绍本人提取psp游戏文本的过程。本人认为在所有步骤中,最困难的要属找文本位置,所花费时间占时间的95%。如果各位有其他见解,请在评论区各抒己见。

















 861
861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









