






一、Collection
(1)List
1、CopyOnWriteList
包括CopyOnWriteList和CopyOnWriteSet两个。当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
a、CopyOnWriteArrayList Add方法
CopyOnWriteArrayList容器是Collections.synchronizedList(List list)的替代方案,是一个ArrayList的线程安全的变体。
基本原理:
初始化的时候只有一个容器,很常一段时间,这个容器数据、数量等没有发生变化的时候,大家(多个线程),都是读取(假设这段时间里只发生读取的操作)同一个容器中的数据,所以这样大家读到的数据都是唯一、一致、安全的,但是后来有人往里面增加了一个数据,这个时候CopyOnWriteArrayList 底层实现添加的原理是先copy出一个容器(可以简称副本),再往新的容器里添加这个新的数据,最后把新的容器的引用地址赋值给了之前那个旧的的容器地址,但是在添加这个数据的期间,其他线程如果要去读取数据,仍然是读取到旧的容器里的数据。
CopyOnWriteArrayList中add方法的实现(向CopyOnWriteArrayList里添加元素),可以发现在添加的时候是需要加锁的,否则多线程写的时候会Copy出N个副本出来。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 复制出新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 把新元素添加到新数组里
newElements[len] = e;
// 把原数组引用指向新数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
/**
* Sets the array.
*/
final void setArray(Object[] a) {
array = a;
}
b、remove方法
删除元素,很简单,就是判断要删除的元素是否最后一个,如果最后一个直接在复制副本数组的时候,复制长度为旧数组的length-1即可;
但是如果不是最后一个元素,就先复制旧的数组的index前面元素到新数组中,然后再复制旧数组中index后面的元素到数组中,最后再把新数组复制给旧数组的引用。最后在finally语句块中将锁释放。
2、ArrayList
可以看做动态数组,数据存放在Object数组里,默认情况下初始化空数组(长度为0的数组)
// 数据的数组
transient Object[] elementData; // non-private to simplify nested class access
指定数组的初始容量
当指定的初始容量大于0,初始化指定大小的数组
当指定的初始容量等于0,初始化空数组
当指定的初始容量小于0,抛出IllegalArgumentException异常
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
a、E get(int index) 获取index位置的元素
b、E set(int index, E element) 设置(覆盖)index位置的元素
和get一样先判断index(下标)是否越界,不越界则先获取原来index位置上的元素,接着设置(覆盖)index位置上的元素,然后返回原来的元素,反之抛出IndexOutOfBoundsException异常
c、boolean add(E e) 添加一个元素到列表尾
(添加一个元素到列表尾,当列表容量不足时自动扩容(通常是扩容至原来的1.5倍),添加成功返回true )
public boolean add(E e) {
// 检查当前容量是否还可以容纳一个元素,不够则扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
// 添加到数组末尾
// 这个语句可以分解为
// elementData[size] = e;
// size += 1;
elementData[size++] = e;
return true;
}
d、void add(int index, E element) 在index处放置元素
(将elementData数组从index开始后面的元素往后移一位,接着在index处放置元素)
public void add(int index, E element) {
// 检查下标是否越界
rangeCheckForAdd(index);
// 检查当前容量是否还可以在容纳一个元素,不够则扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
// 将elementData从index开始后面的元素往后移一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
3、LinkedList
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行列表操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
}
其存储结构为内部类Node
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
}
add方法会调用linkLast方法,会在链表尾端添加节点~
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
方法add(int index, E element)
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
该方法包含如下两个步骤
检查指定index的值是否有效[0,size]
如果index == size 则使用linkLast添加在尾部;如果index != size, 则使用linkBefore将新元素添加在指定位置之前~
get方法。 node(index)方法找到指定位置节点,先判断index是否大于中间位置,是则从头找,否则从尾找。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
4、Vector
Vector 类实现了一个动态数组。和 ArrayList 很相似,但是两者是不同的:
a、Vector 是同步访问的。
b、Vector 包含了许多传统的方法,这些方法不属于集合框架。
底层也是Object数组,只是所有方法都是带synchronized锁的
protected Object[] elementData;
5、Stack
Stack是栈。它的特性是:先进后出(FILO, First In Last Out)。
java工具包中的Stack是继承于Vector(矢量队列)的,由于Vector是通过数组实现的,这就意味着,Stack也是通过数组实现的,而非链表。当然,我们也可以将LinkedList当作栈来使用!
public class Stack<E> extends Vector<E> {
}
Stack只有一个默认构造函数,它常用的API如下:
1 package java.util;
2
3 public
4 class Stack<E> extends Vector<E> {
5 // 版本ID。这个用于版本升级控制,这里不须理会!
6 private static final long serialVersionUID = 1224463164541339165L;
7
8 // 构造函数
9 public Stack() {
10 }
11
12 // push函数:将元素存入栈顶
13 public E push(E item) {
14 // 将元素存入栈顶。
15 // addElement()的实现在Vector.java中
16 addElement(item);
17
18 return item;
19 }
20
21 // pop函数:返回栈顶元素,并将其从栈中删除
22 public synchronized E pop() {
23 E obj;
24 int len = size();
25
26 obj = peek();
27 // 删除栈顶元素,removeElementAt()的实现在Vector.java中
28 removeElementAt(len - 1);
29
30 return obj;
31 }
32
33 // peek函数:返回栈顶元素,不执行删除操作
34 public synchronized E peek() {
35 int len = size();
36
37 if (len == 0)
38 throw new EmptyStackException();
39 // 返回栈顶元素,elementAt()具体实现在Vector.java中
40 return elementAt(len - 1);
41 }
42
43 // 栈是否为空
44 public boolean empty() {
45 return size() == 0;
46 }
47
48 // 查找“元素o”在栈中的位置:由栈底向栈顶方向数
49 public synchronized int search(Object o) {
50 // 获取元素索引,elementAt()具体实现在Vector.java中
51 int i = lastIndexOf(o);
52
53 if (i >= 0) {
54 return size() - i;
55 }
56 return -1;
57 }
58 }
(01) Stack实际上也是通过数组去实现的。
执行push时(即,将元素推入栈中),是通过将元素追加的数组的末尾中。
执行peek时(即,取出栈顶元素,不执行删除),是返回数组末尾的元素。
执行pop时(即,取出栈顶元素,并将该元素从栈中删除),是取出数组末尾的元素,然后将该元素从数组中删除。
(02) Stack继承于Vector,意味着Vector拥有的属性和功能,Stack都拥有。
(2)Set
1、HashSet
HashSet继承了AbstractSet抽象类,和ArrayList和LinkedList一样,在他们的抽象父类中,都提供了equals()方法和hashCode()方法。它们自身并不实现这两个方法,(但是ArrayList和LinkedList的equals()实现不同。你可以看我的关于ArrayList这一块的源码解析)这就意味着诸如和HashSet一样继承自AbstractSet抽象类的TreeSet、LinkedHashSet等,他们只要元素的个数和集合中元素相同,即使他们是AbstractSet不同的子类,他们equals()相互比较的后的结果仍然是true。下面给出的代码是JDK中的equals()代码:
从JDK源码可以看出,底层并没有使用我们常规认为的利用hashcode()方法求的值进行比较,而是通过调用AbstractCollection的containsAll()方法,如果他们中元素完全相同(与顺序无关),则他们的equals()方法的比较结果就为true。
HashSet内部通过使用HashMap的键来存储集合中的元素,而且内部的HashMap的所有值
都是null。(因为在为HashSet添加元素的时候,内部HashMap的值都是PRESENT),而PRESENT在实例域的地方直接初始化了,而且不允许改变。
static final long serialVersionUID = -5024744406713321676L;
//底层使用了HashMap存储数据。
private transient HashMap<E,Object> map;
//用来填充底层数据结构HashMap中的value,因为HashSet只用key存储数据
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
add方法:
//底层仍然利用了HashMap键进行了元素的添加。
//在HashMap的put()方法中,如果key不重复,返回null,如果重复,返回get(key)
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
remove方法:
//该方法底层实现了仍然使用了map的remove()方法。
//map的remove()方法的返回的是被删除键对应的值。(在HashSet的底层HashMap中的所有
//键值对的值都是PRESENT)
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
clone方法(浅克隆):
底层仍然使用了Object的clone()方法,得到的Object对象,并把它强制转化为HashSet,然后把它的底层的HashMap也克隆一份(调用的HashMap的clone()方法),并把它赋值给newSet,最后返回newSet即可。
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
2、LinkedHashSet
LinkedHashSet继承自HashSet,,LinkedHashSet继承自HashSet,它的添加、删除、查询等方法都是直接用的HashSet的,唯一的不同就是它使用LinkedHashMap存储元素。
// LinkedHashSet继承自HashSet
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
private static final long serialVersionUID = -2851667679971038690L;
// 传入容量和装载因子
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
// 只传入容量, 装载因子默认为0.75
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
// 使用默认容量16, 默认装载因子0.75
public LinkedHashSet() {
super(16, .75f, true);
}
// 将集合c中的所有元素添加到LinkedHashSet中
// 好奇怪, 这里计算容量的方式又变了
// HashSet中使用的是Math.max((int) (c.size()/.75f) + 1, 16)
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
// 可分割的迭代器, 主要用于多线程并行迭代处理时使用
@Override
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}
* @param initialCapacity the initial capacity of the hash map --容量
* @param loadFactor the load factor of the hash map --负载因子
* @param dummy ignored (distinguishes this
* constructor from other int, float constructor.)
* --忽略(区分此构造函数与其他int、float构造函数)
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
3、SortedSet和TreeSet
SortedSet 接口扩展了 Set 接口,同时又提供了一些功能增强的方法,比如 comparator 从而实现了元素的有序性。插入到有序集中的所有元素必须实现Comparable接口(或者被指定的Comparator接受),并且所有这些元素必须是可相互比较的。
public interface SortedSet<E> extends Set<E> {
}
comparator(): 返回用于对此集合中的元素进行排序的比较器,如果此集合使用其元素的自然顺序,则返回null。
first(): 返回此集合中当前的第一个(最低)元素。
headSet(E toElement): 返回此set的部分视图,其元素严格小于toElement。
last(): 返回此集合中当前的最后一个(最高)元素。
subSet(E fromElement,E toElement): 返回此set的部分视图,其元素范围从 fromElement(包括) 到 toElement(不包括)。
tailSet(E fromElement): 返回此set的部分元素,其元素大于或等于fromElement。
spliterator(): 在此有序集中的元素上创建Spliterator。
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
/**
* TreeSet底层是以TreeMap来储存数据的,key为add()中的元素,value为PRESENT值
*/
private transient NavigableMap<E,Object> m;
/**
* 无参构造方法,创建一个TreeSet对象
*/
public TreeSet() {
this(new TreeMap<E,Object>());
}
/**
* 创建一个TreeMap对象
*/
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
}
(01) TreeSet是有序的Set集合,因此支持add、remove、get等方法。
(02) 和NavigableSet一样,TreeSet的导航方法大致可以区分为两类,一类时提供元素项的导航方法,返回某个元素;另一类时提供集合的导航方法,返回某个集合。
lower、floor、ceiling 和 higher 分别返回小于、小于等于、大于等于、大于给定元素的元素,如果不存在这样的元素,则返回 null。
(3)Queue
对于Queue来说,就是一个FIFO(先进先出)的队列,添加元素只能在队尾,移除只能在队首。
对于这一组方法,成功返回true,在操作失败时抛出异常,这是与下面一组方法的主要区别。
**add(E e):**添加一个元素到队尾(add方法还是调用offer,返回false则抛出异常)
**remove():**获取队首的元素,并从队列中移除
**element():**获取队首的元素,但不从队列中移除
这一组,成功返回true,失败时返回一个特殊值(取决于操作,为NULL或false),offer(E e)操作是专为容量受限的队列实现而设计的;在大多数实现中,插入操作不会失败。
**offer(E e):**添加一个元素到队尾
**poll():**获取队首的元素,并从队列中移除
**peek():**获取队首的元素,但不从队列中移除
1、Deque(双端队列)
(a)ArrayDeque
ArrayDeque底层存储是一个循环数组,用head和tail两个指针标记头尾。
public interface Deque<E> extends Queue<E> {
}
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable {
// 队列中存放数据的数组
transient Object[] elements;
// 标记队头下标,当head==tail时,队列为空。
transient int head;
// 标记队尾下标。
transient int tail;
// 最小初始化数组容量
private static final int MIN_INITIAL_CAPACITY = 8;
}
/**
* 默认构造方法,初始容量为16
*/
public ArrayDeque() {
elements = new Object[16];
}
/**
* 自定义容量
*/
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
/**
* 获得2的N次方
*/
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
/**
* 在java中,int类型占4个字节,也就是32位,例如0100 0000 0000 0000 0000 0000 0000 0000
* 逻辑右移1位,并且进行或操作,可得0110 0000 0000 0000 0000 0000 0000 0000
* 逻辑右移2位,并且进行或操作,可得0111 1000 0000 0000 0000 0000 0000 0000
* 逻辑右移4位,并且进行或操作,可得0111 1111 1000 0000 0000 0000 0000 0000
* 逻辑右移8位,并且进行或操作,可得0111 1111 1111 1111 1000 0000 0000 0000
* 逻辑右移16位,并且进行或操作,可得0111 1111 1111 1111 1111 1111 1111 1111
* 然后加1得1000 0000 0000 0000 0000 0000 0000 0000
* 通过计算后可得比numElements大的最小2的N次方。
*/
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
/**
* 是否溢出,当溢出时,该数为-2147483648,也就是
* 10000000000000000000000000000000
*/
if (initialCapacity < 0)
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
return initialCapacity;
}
addFirst方法
插入前:
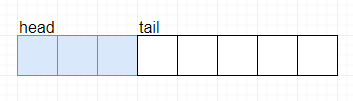
插入后:
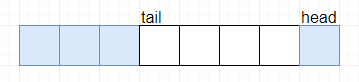
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
/**
* 计算head的下标,如果我们不考虑边界,那么head = head - 1,
* 但是实际上当head = 0时,我们插入元素到队列的头部,
* head的值应该存储在数组的尾部,但是这里不能使用(head - 1) % (elements.length - 1),
* 把数组长度设计为2的N次方,可以减少判断,而且位运算要更快
*/
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
扩容

(b)BlockingDeque(LinkedBlocingDeque)
容量问题
LinkedBlockingDeque是一个可选容量的阻塞队列,如果没有设置容量,那么容量将是Int的最大值。
底层数据结构
LinkedBlockingDeque的底层数据结构是一个双端队列,该队列使用链表实现,其结构图如下:
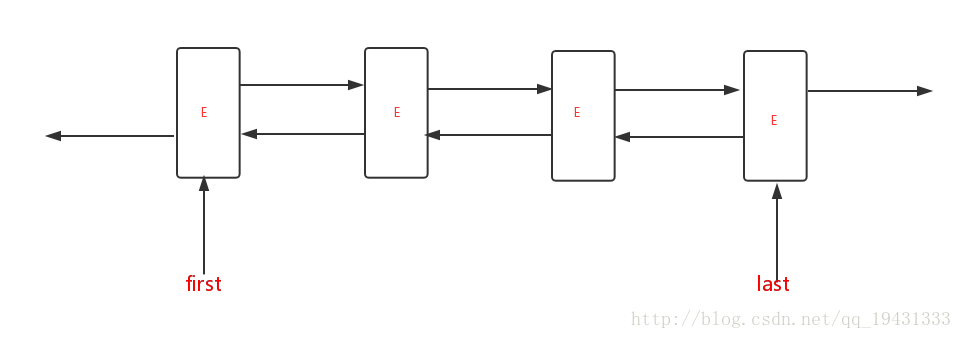
public class LinkedBlockingDeque<E>
extends AbstractQueue<E>
implements BlockingDeque<E>, java.io.Serializable {
//队列的头节点
transient Node<E> first;
//队列的尾节点
transient Node<E> last;
//队列中元素的个数
private transient int count;
//队列中元素的最大个数
private final int capacity;
//锁
final ReentrantLock lock = new ReentrantLock();
//队列为空时,阻塞take线程的条件队列
private final Condition notEmpty = lock.newCondition();
//队列满时,阻塞put线程的条件队列
private final Condition notFull = lock.newCondition();
}
入队方法,putFirst( )
public void putFirst(E e) throws InterruptedException {
//不允许元素为null
if (e == null) throw new NullPointerException();
//新建节点
Node<E> node = new Node<E>(e);
final ReentrantLock lock = this.lock;
//占有锁
lock.lock();
try {
//如果添加失败,等待
while (!linkFirst(node))
notFull.await();
} finally {
//释放锁
lock.unlock();
}
}
private boolean linkFirst(Node<E> node) {
// 如果容量满了
if (count >= capacity)
return false;
//插入节点,将first指向新建节点
Node<E> f = first;
node.next = f;
first = node;
if (last == null)
last = node;
else
f.prev = node;
++count;
//因为插入了一个元素,通知因元素为0时阻塞的take线程
notEmpty.signal();
return true;
}
总结
LinkedBlockingDeque和LinkedBlockingQueue的相同点在于:
1、基于链表
2、容量可选,不设置的话,就是Int的最大值
和LinkedBlockingQueue的不同点在于:
1、双端链表和单链表
2、不存在哨兵节点
3、一把锁+两个条件
LinkedBlockingDeque和ArrayBlockingQueue的相同点在于:使用一把锁+两个条件维持队列的同步。
2、BlockingQueue
| 处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put() | offer(e, time, unit) |
| 移除方法 | remove() | poll() | take() | take(time, unit) |
| 检查方法 | element() | peek() | 无 | 无 |
(a)ArrayBlockingQueue
这是一个由数组结构组成的有界阻塞队列。首先看下它的构造方法,有三个。
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public ArrayBlockingQueue(int capacity, boolean fair,Collection<? extends E> c) { }
第一个可以指定队列的大小,第二个还可以指定队列是否公平,不指定的话,默认是非公平。它是使用 ReentrantLock 的公平锁和非公平锁实现的(后续讲解AQS时,会详细说明)。
简单理解就是,ReentrantLock 内部会维护一个有先后顺序的等待队列,假如有五个任务一起过来,都被阻塞了。如果是公平的,则等待队列中等待最久的任务就会先进入阻塞队列。如果是非公平的,那么这五个线程就需要抢锁,谁先抢到,谁就先进入阻塞队列。
第三个构造方法,是把一个集合的元素初始化到阻塞队列中。
另外,ArrayBlockingQueue 没有实现读写分离,也就是说,读和写是不能同时进行的。因为,它读写时用的是同一把锁,如下图所示:
//存放元素的数组(循环数组)
final Object[] items;
//队头
int takeIndex;
//队尾
int putIndex;
//队列中的元素个数
int count;
//锁
final ReentrantLock lock;
//监视队列是否为空的监视器
private final Condition notEmpty;
//监视队列是否到达容量的监视器
private final Condition notFull;
可以看出ArrayBlockingQueue内部使用final修饰的对象数组来存储元素,一旦初始化数组,数组的大小就不可改变。使用ReentrantLock锁来保证锁竞争,使用Condition来控制插入或获取元素时,线程是否阻塞。
put()方法
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
//获得支持响应中断的锁
lock.lockInterruptibly();
try {
//使用while循环来判断队列是否已满,防止假唤醒
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
//把当前元素插入到数组中去
items[putIndex] = x;
//这里可以看出这个数组是个环形数组
if (++putIndex == items.length)
putIndex = 0;
count++;
// 唤醒在notEmpty条件上等待的线程
notEmpty.signal();
}
take()方法
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
//获得可响应中断锁
lock.lockInterruptibly();
try {
//使用while循环来判断队列是否已满,防止假唤醒
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
//获取元素
E x = (E) items[takeIndex];
//将当前位置的元素设置为null
items[takeIndex] = null;
//这里可以看出这个数组是个环形数组
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
//修改迭代器参数
itrs.elementDequeued();
// 唤醒在notFull条件上等待的线程
notFull.signal();
return x;
}
(b)LinkedBlockingQueue
这是一个由链表结构组成的有界阻塞队列。它的构造方法有三个。
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
public LinkedBlockingQueue(Collection<? extends E> c) {}
//队列容量
private final int capacity;
//队列中的元素个数
private final AtomicInteger count = new AtomicInteger();
//队头
transient Node<E> head;
//队尾
private transient Node<E> last;
//出队的锁
private final ReentrantLock takeLock = new ReentrantLock();
//队列非空的监视器
private final Condition notEmpty = takeLock.newCondition();
//入队的锁
private final ReentrantLock putLock = new ReentrantLock();
//对类未满的监视器
private final Condition notFull = putLock.newCondition();
static class Node<E> {
E item;
/**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head.next
* - null, meaning there is no successor (this is the last node)
*/
Node<E> next;
Node(E x) { item = x; }
}
可以看到,与ArrayBlockingQueue和LinkedBlockingDeque不同,这里使用了两把锁,实现了读写分离,提高了效率。
LinkedBlockingQueue使用双锁可并行读写,其吞吐量更高。
ArrayBlockingQueue在插入或删除元素时直接放入数组指定位置(putIndex、takeIndex),不会产生或销毁任何额外的对象实例;而LinkedBlockingQueue则会生成一个额外的Node对象,在高效并发处理大量数据时,对GC的影响存在一定的区别。
在大部分并发场景下,LinkedBlockingQueue的吞吐量比ArrayBlockingQueue更好。
(c)SynchronousQueue
SynchronousQueue是一种阻塞队列,其中每个插入操作必须等待另一个线程的对应移除操作 ,反之亦然。同步队列没有任何内部容量,甚至连一个队列的容量都没有。
由于SynchronousQueue的支持公平策略和非公平策略,所以底层可能两种数据结构:队列(实现公平策略)和栈(实现非公平策略),队列与栈都是通过链表来实现的。
利用CAS保证同步安全
基本成员
abstract static class Transferer<E> {
// 出队入队都是这一个方法
abstract E transfer(E e, boolean timed, long nanos);
}
// cpu数
static final int NCPUS = Runtime.getRuntime().availableProcessors();
// 带超时时间的自旋次数
static final int maxTimedSpins = (NCPUS < 2) ? 0 : 32;
// 没有超时的自旋次数
static final int maxUntimedSpins = maxTimedSpins * 16;
主要成员
TransferStack 非公平的实现
static final class TransferStack<E> extends Transferer<E> {
/** 0表示消费者 */
static final int REQUEST = 0;
/** 1表示数据的生产者 */
static final int DATA = 1;
/** 2 表示数据正在匹配 */
static final int FULFILLING = 2;
static final class SNode {
volatile SNode next; // 下一个节点
volatile SNode match; // 匹配的节点
volatile Thread waiter; // 等待的线程
Object item; // 数据
int mode; // 模式 0 , 1 , 2
}
/** 头结点 */
volatile SNode head;
}
TransferQueue 公平实现
static final class TransferQueue<E> extends Transferer<E> {
static final class QNode {
volatile QNode next; // next 节点
volatile Object item; // 数据项
volatile Thread waiter; // 等待线程
final boolean isData; // 区分生产和消费
}
/** 头结点 */
transient volatile QNode head;
/** 尾节点 */
transient volatile QNode tail;
}
构造方法
public SynchronousQueue() {
this(false);
}
// 构造方法,fair表示公平或者非公平
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
put( )方法
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}
take( )方法
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
transfer方法
E transfer(E e, boolean timed, long nanos) {
QNode s = null; // constructed/reused as needed
boolean isData = (e != null);
for (;;) {
QNode t = tail;
QNode h = head;
if (t == null || h == null) // saw uninitialized value
continue; // spin
if (h == t || t.isData == isData) { // empty or same-mode
QNode tn = t.next;
if (t != tail) // inconsistent read
continue;
if (tn != null) { // lagging tail
advanceTail(t, tn);
continue;
}
if (timed && nanos <= 0) // can't wait
return null;
if (s == null)
s = new QNode(e, isData);
if (!t.casNext(null, s)) // failed to link in
continue;
advanceTail(t, s); // swing tail and wait
Object x = awaitFulfill(s, e, timed, nanos);
if (x == s) { // wait was cancelled
clean(t, s);
return null;
}
if (!s.isOffList()) { // not already unlinked
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e;
} else { // complementary-mode
QNode m = h.next; // node to fulfill
if (t != tail || m == null || h != head)
continue; // inconsistent read
Object x = m.item;
if (isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e)) { // lost CAS
advanceHead(h, m); // dequeue and retry
continue;
}
advanceHead(h, m); // successfully fulfilled
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
}
}
}
(d)PriorityBlockingQueue
基于优先级别的阻塞队列(优先级的判断通过构造函数传入的Compator对象来决定,也就是说传入队列的对象必须实现Comparable接口),在实现PriorityBlockingQueue时,内部控制线程同步的锁采用的是公平锁。
- PriorityBlockingQueue 是基于优先级堆实现的线程安全的、无界、优先级、阻塞队列。
- 队列的元素按照其自然顺序进行排序,或者根据构造队列时提供的 Comparator 进行排序。
- 在并发场景下,需要按照指定的优先级获取元素时可以选择PriorityBlockingQueue。
- PriorityBlockingQueue
是无界的阻塞队列,它并不会阻塞生产者插入元素,当生产速率大于消费速率时,时间一长,可能导致内存溢出
成员变量
/**
* 默认的数组容量
*/
private static final int DEFAULT_INITIAL_CAPACITY = 11;
/**
* 最大的数组容量
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 优先队列数组
*/
private transient Object[] queue;
/**
* 优先级队列中的元素总数
*/
private transient int size;
/**
* 元素比较器,如果按照自然顺序进行排序,则为 null
*/
private transient Comparator<? super E> comparator;
/**
* 控制访问的可重入互斥锁
*/
private final ReentrantLock lock;
/**
* 队列为空时,目标线程将在非空条件阻塞等待
*/
private final Condition notEmpty;
/**
* 初始0为可获取状态,用于控制扩容操作
*/
private transient volatile int allocationSpinLock;
take():如果队列为空,则阻塞等待有可用元素后重试,否则移除并返回优先级最高的元素
- PriorityBlockingQueue类是一个优先级队列,本身是线程安全的,内部使用显示锁ReentrantLock来保证线程安全
- PriorityBlockingQueue存储的对象必须是实现了
Comparable接口的,因为PriorityBlockingQueue队列会根据内存存储的每一个元素的comparaTo方法来比较每个元素的大小。这样在take的时候会根据优先级,将优先级最小的取出。 - PriorityBlockingQueue类似于ArrayBlockingQueue,其内部都使用了一个独占锁来控制同时只有一个线程可以进行入队和出队的操作,另外PriorityBlockingQueue只使用了notEmpty 条件变量,而没有使用 notFull变量,这是因为前者是无界队列,当put的时候永远都不会处于await。
- PriorityBlockingQueue始终保证出队的元素是优先级最高的元素,并且可以定制优先级的规则,内部通过使用一个二叉树最小堆算法来维护内部数组,这个数组是可扩容的,当当前元素的个数>= 最大容量的时候会通过算法进行扩容操作(tryGrow)。这里的扩容是通过释放锁使用cas来实现的。
- 扩容的规则:一种是如果旧的容量小于64,那么新的容量为:2 * 旧的容量 + 2,如果旧容量大于64,那么新的容量为 1.5 * 旧的容量
- PriorityBlockingQueue类的offer 和 poll方法在放入数据和取出数据的时候分别会进行小根堆的建立siftUpComparable,和小根堆的调整siftDownComparable。
(e)LinkedTransferQueue
LinkedTransferQueue 是一个由链表结构组成的无界阻塞传输队列,它是一个很多队列的结合体(ConcurrentLinkedQueue,LinkedBlockingQueue,SynchronousQueue),在除了有基本阻塞队列的功能(但是这个阻塞队列没有使用锁)之外;队列实现了TransferQueue接口重写了tryTransfer和transfer方法,这组方法和SynchronousQueue公平模式的队列类似,具有匹配的功能。
// 是否是多核
private static final boolean MP =
Runtime.getRuntime().availableProcessors() > 1;
// 自旋次数
private static final int FRONT_SPINS = 1 << 7;
// 前驱节点正在处理,当前节点需要自旋的次数
private static final int CHAINED_SPINS = FRONT_SPINS >>> 1;
// 容忍清除节点失败次数的阈值
static final int SWEEP_THRESHOLD = 32;
static final class Node {
// 表示存放数据还是获取数据
final boolean isData; // false if this is a request node
// 存放数据是item有值
volatile Object item; // initially non-null if isData; CASed to match
// next节点
volatile Node next;
// 等待线程
volatile Thread waiter;
// 构造
Node(Object item, boolean isData) {
UNSAFE.putObject(this, itemOffset, item); // relaxed write
this.isData = isData;
}
}
// 头结点
transient volatile Node head;
// 尾节点
private transient volatile Node tail;
// xfer方法的入参, 不同类型的方法内部调用xfer方法时入参不同
private static final int NOW = 0; // for untimed poll, tryTransfer
private static final int ASYNC = 1; // for offer, put, add
private static final int SYNC = 2; // for transfer, take
private static final int TIMED = 3; // for timed poll, tryTransfer
常用方法
// 队尾弹出一个元素,没有就返回null
public E poll() {
return xfer(null, false, NOW, 0);
}
// 立即转交一个元素给消费者,如果此时队列没有消费者,那就false
public boolean tryTransfer(E e) {
return xfer(e, true, NOW, 0) == null;
}
// 转交一个元素给消费者,如果此时队列没有消费者,那就阻塞
public void transfer(E e) throws InterruptedException {
if (xfer(e, true, SYNC, 0) != null) {
// 清除方法
Thread.interrupted(); // failure possible only due to interrupt
throw new InterruptedException();
}
}
private E xfer(E e, boolean haveData, int how, long nanos) {
// 插入元素,
if (haveData && (e == null))
throw new NullPointerException();
Node s = null; // the node to append, if needed
retry:
for (;;) { // 死循环 // restart on append race
// 从头结点开始匹配
for (Node h = head, p = h; p != null;) { // find & match first node
boolean isData = p.isData; // 获取节点的类型
Object item = p.item; // item 的值
// 两种情况 1.put节点 item != null isData 为true 2.take item = null false isData false
// 或者节点已经被匹配了
if (item != p && (item != null) == isData) { // unmatched // 节点没有被匹配过
if (isData == haveData) // can't match // 类型一致,只能执行入队操作
break;
if (p.casItem(item, e)) { // match 匹配,可能存在多线程竞争匹配
for (Node q = p; q != h;) { // 不是头节点了,头结点发生了改变,被匹配了,自己也匹配了,
// 下一个节点
Node n = q.next; // update by 2 unless singleton
if (head == h && casHead(h, n == null ? q : n)) {
// 自关联 节点不要了
h.forgetNext();
break;
} // advance and retry
// head 已经被更新过,或者更新head失败,需要重新判断
// h = head == null,队列为空
// (q = h.next) == null 最后一个节点
// 头接单的下一个节点有没有被匹配
// 说明值有头结点匹配了,头结点的next节点也匹配了,才要更新头结点,优化手段
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
// 匹配成功
LockSupport.unpark(p.waiter);
return LinkedTransferQueue.<E>cast(item);
}
}
// 已经匹配就往下走
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
}
/* // xfer方法的入参, 不同类型的方法内部调用xfer方法时入参不同
private static final int NOW = 0; // for untimed poll, tryTransfer
private static final int ASYNC = 1; // for offer, put, add
private static final int SYNC = 2; // for transfer, take
private static final int TIMED = 3; // for timed poll, tryTransfer*/
// 模式不同只能入队啦
if (how != NOW) { // No matches available
if (s == null)
// 创建一个新节点
s = new Node(e, haveData);
// tryAppend 给tail追加节点
Node pred = tryAppend(s, haveData);
// 不能添加到这个节点 ,重新循环
if (pred == null)
continue retry;
// lost race vs opposite mode
// ASYNC 添加成功返回了
// SYNC TIMED 需要阻塞线程
if (how != ASYNC)
return awaitMatch(s, pred, e, (how == TIMED), nanos);
}
// now 是立即返回
return e; // not waiting
}
}
3、ConcurrentLinkedQueue
实现线程安全的队列有两种方式:一种基于阻塞的实现,用锁实现;另一种是基于非阻塞的实现,使用循环CAS实现。ConcurrentLinkedQueue就是基于非阻塞的方式实现的
public class ConcurrentLinkedQueue<E> extends AbstractQueue<E>
implements Queue<E>, java.io.Serializable {
//队头
private transient volatile Node<E> head;
//队尾
private transient volatile Node<E> tail;
private static class Node<E> {
//节点中的值
volatile E item;
//节点的后继
volatile Node<E> next;
//使用CAS来构造节点
Node(E item) {
UNSAFE.putObject(this, itemOffset, item);
}
//使用CAS更新节点的值
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
//使用CAS节点val更新为cmp节点
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
}
}
入队方法
public boolean offer(E e) {
//判断入队节点是否为空
checkNotNull(e);
//构造入队节点
final Node<E> newNode = new Node<E>(e);
//死循环,入队不成功继续入队
//p初始为tail
for (Node<E> t = tail, p = t;;) {
//q为p的后继,若p为队尾,则q为空,若p不是队尾,则有其他线程更改了队列
Node<E> q = p.next;
if (q == null) {
//p是队尾 将入队节点变成队尾的后继
if (p.casNext(null, newNode)) {
//判断tail节点是否为尾节点
if (p != t)
//如果不是,将入队节点修改为队尾
casTail(t, newNode);
return true;
}
// Lost CAS race to another thread; re-read next
}
//说明这个节点已经被移除了
else if (p == q)
//如果队尾未发生改变,t还是队尾,则将p指向t,继续插入新节点
//如果队尾发生改变,则将p指向队头重新开始插入新节点
p = (t != (t = tail)) ? t : head;
else
//说明p有后继,p的后继才是队尾,则需要将p指向队尾
p = (p != t && t != (t = tail)) ? t : q;
}
}
1、构造新节点
2、开始循环,p表示队尾,默认p初始为tail,
3、如果p后继为空,说明p就是tail,则插入新节点返回
4、如果p节点被删除,则需要重新赋值p,如果tail未变,则将p赋值为t,如果tail改变,则将p赋值为队头,继续插入
5、如果p有后继,说明p不是tail,则需要将p指向tail。
4、DelayQueue
DelayQueue内的元素E实现了Delayed接口,重写了getDelay和CompareTo方法。内部元素通过PriorityQueue按时间进行排序,获取元素时,调用getDelay方法比较时间,时间到了则获取,时间没到则利用Condition等待一定时间。
public class DelayQueue<E extends Delayed> extends AbstractQueue<E>
implements BlockingQueue<E> {
private final transient ReentrantLock lock = new ReentrantLock();
private final PriorityQueue<E> q = new PriorityQueue<E>();
private Thread leader = null;
private final Condition available = lock.newCondition();
public DelayQueue() {}
public interface Delayed extends Comparable<Delayed> {
/**
* Returns the remaining delay associated with this object, in the
* given time unit.
*
* @param unit the time unit
* @return the remaining delay; zero or negative values indicate
* that the delay has already elapsed
*/
long getDelay(TimeUnit unit);
}
take( )方法
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null)
available.await();
else {
//获取等待时间
long delay = first.getDelay(NANOSECONDS);
//时间到了则取出
if (delay <= 0)
return q.poll();
first = null; // don't retain ref while waiting
//时间没到,但是有线程等待了,当前线程直接进入等待状态
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}
leader元素的使用
用leader来减少不必要的等待时间,这里我们想象着我们有个多个消费者线程用take方法去取,内部先加锁,然后每个线程都去peek第一个节点.
如果leader不为空说明已经有线程在取了,设置当前线程等待
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
如果为空说明没有其他线程去取这个节点,设置leader并等待delay延时到期,直到poll后结束循环
二、Map
(1) HashMap
HashMap是基于哈希表(散列表),实现Map接口的双列集合,数据结构是“链表散列”,也就是数组+链表 ,key唯一的value可以重复,允许存储null 键null 值,元素无序。
/** 构造方法 1 */
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/** 构造方法 2 */
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/** 构造方法 3 */
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
| 名称 | 用途 |
|---|---|
| initialCapacity | HashMap 初始容量 |
| loadFactor | 负载因子 |
| threshold | 当前 HashMap 所能容纳键值对数量的最大值,超过这个值,则需扩容 |
存储结构:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
//序列号,序列化的时候使用。
private static final long serialVersionUID = 362498820763181265L;
/**默认容量,1向左移位4个,00000001变成00010000,也就是2的4次方为16,使用移位是因为移位是计算机基础运算,效率比加减乘除快。**/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//最大容量,2的30次方。
static final int MAXIMUM_CAPACITY = 1 << 30;
//加载因子,用于扩容使用。
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//当某个桶节点数量大于8时,会转换为红黑树。
static final int TREEIFY_THRESHOLD = 8;
//当某个桶节点数量小于6时,会转换为链表,前提是它当前是红黑树结构。
static final int UNTREEIFY_THRESHOLD = 6;
//当整个hashMap中元素数量大于64时,也会进行转为红黑树结构。
static final int MIN_TREEIFY_CAPACITY = 64;
//存储元素的数组,transient关键字表示该属性不能被序列化
transient Node<K,V>[] table;
//将数据转换成set的另一种存储形式,这个变量主要用于迭代功能。
transient Set<Map.Entry<K,V>> entrySet;
//元素数量
transient int size;
//统计该map修改的次数
transient int modCount;
//临界值,也就是元素数量达到临界值时,会进行扩容。
int threshold;
//也是加载因子,只不过这个是变量。
final float loadFactor;
//红黑树
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent;
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev;
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
}
//单向链表
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
(2) LinkedHashMap
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>{
private static final long serialVersionUID = 3801124242820219131L;
// 用于指向双向链表的头部
transient LinkedHashMap.Entry<K,V> head;
//用于指向双向链表的尾部
transient LinkedHashMap.Entry<K,V> tail;
/**
* 用来指定LinkedHashMap的迭代顺序,
* true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾
* false则表示按照插入顺序来,默认为false
*/
final boolean accessOrder;
}
LinkedHashMap继承HashMap,HashMap中的数组是Node<K,V>[]类型的,在LinkedHashMap中定义了Entry<K,V>继承Node<K,V>[],但是在LinkedHashMap中并没有找到新建节点的方法。仔细研究之后发现,在HashMap类的put方法中,新建节点是使用的newNode方法。而在LinkedHashMap没有重写父类的put方法,而是重写了newNode方法来构建自己的节点对象。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
//HashMap中的newNode方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
Get方法
public V get(Object key) {
Node<K,V> e;
//调用HashMap的getNode的方法,详见HashMap源码解析
if ((e = getNode(hash(key), key)) == null)
return null;
//在取值后对参数accessOrder进行判断,如果为true,执行afterNodeAccess
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
Put方法
在LinkedHashMap类使用的仍然是父类HashMap的put方法,所以插入节点对象的流程基本一致。不同的是,LinkedHashMap将其中newNode方法以及之前设置下的钩子方法(空方法)afterNodeAccess和afterNodeInsertion进行了重写,从而实现了加入链表的目的。
//调用HashMap的put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
tab[i] = newNode(hash, key, value, null);
...
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
...
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
...
afterNodeAccess(e);
...
afterNodeInsertion(evict);
return null;
}
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
//秘密就在于 new的是自己的Entry类,然后调用了linkedNodeLast
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
//顾名思义就是把新加的节点放在链表的最后面
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
//将tail给临时变量last
LinkedHashMap.Entry<K,V> last = tail;
//把new的Entry给tail
tail = p;
//若没有last,说明p是第一个节点,head=p
if (last == null)
head = p;
//否则就做准备工作,你懂的 ( ̄▽ ̄)"
else {
p.before = last;
last.after = p;
}
}
//这里笔者也把TreeNode的重写也加了进来,因为putTreeVal里有调用了这个
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}
//afterNodeInsertion方法用于移除链表中的最旧的节点对象,也就是链表头部的对象。但是在JDK1.8版本中,
//可以看到removeEldestEntry一直返回false,所以该方法并不生效。如果存在特定的需求,比如链表中长度
//固定,并保持最新的N的节点数据,可以通过重写该方法来进行实现。
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
//afterNodeAccess方法实现的逻辑,是把入参的节点放置在链表的尾部。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
(3) TreeMap
TreeMap集合是基于红黑树(Red-Black tree)的 NavigableMap实现。该集合最重要的特点就是可排序,该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
// 比较器对象
private final Comparator<? super K> comparator;
// 根节点
private transient Entry<K,V> root;
// 集合大小
private transient int size = 0;
// 树结构被修改的次数
private transient int modCount = 0;
// 静态内部类用来表示节点类型
static final class Entry<K,V> implements Map.Entry<K,V> {
K key; // 键
V value; // 值
Entry<K,V> left; // 指向左子树的引用(指针)
Entry<K,V> right; // 指向右子树的引用(指针)
Entry<K,V> parent; // 指向父节点的引用(指针)
boolean color = BLACK; //
}
}
构造方法
public TreeMap() { // 1,无参构造方法
comparator = null; // 默认比较机制
}
public TreeMap(Comparator<? super K> comparator) { // 2,自定义比较器的构造方法
this.comparator = comparator;
}
public TreeMap(Map<? extends K, ? extends V> m) { // 3,构造已知Map对象为TreeMap
comparator = null; // 默认比较机制
putAll(m);
}
public TreeMap(SortedMap<K, ? extends V> m) { // 4,构造已知的SortedMap对象为TreeMap
comparator = m.comparator(); // 使用已知对象的构造器
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
TreeMap Put()方法
在TreeMap的put()的实现方法中主要分为两个步骤,第一:构建排序二叉树,第二:平衡二叉树。
对于排序二叉树的创建,其添加节点的过程如下:
1、以根节点为初始节点进行检索。
2、与当前节点进行比对,若新增节点值较大,则以当前节点的右子节点作为新的当前节点。否则以当前节点的左子节点作为新的当前节点。
3、循环递归2步骤知道检索出合适的叶子节点为止。
4、将新增节点与3步骤中找到的节点进行比对,如果新增节点较大,则添加为右子节点;否则添加为左子节点。
public V put(K key, V value) {
//用t表示二叉树的当前节点
Entry<K,V> t = root;
//t为null表示一个空树,即TreeMap中没有任何元素,直接插入
if (t == null) {
//比较key值,空树还需要比较、排序?
compare(key, key); // type (and possibly null) check
//将新的key-value键值对创建为一个Entry节点,并将该节点赋予给root
root = new Entry<>(key, value, null);
//容器的size = 1,表示TreeMap集合中存在一个元素
size = 1;
//修改次数 + 1
modCount++;
return null;
}
int cmp; //cmp表示key排序的返回结果
Entry<K,V> parent; //父节点
// split comparator and comparable paths
Comparator<? super K> cpr = comparator; //指定的排序算法
//如果cpr不为空,则采用既定的排序算法进行创建TreeMap集合
if (cpr != null) {
do {
parent = t; //parent指向上次循环后的t
//比较新增节点的key和当前节点key的大小
cmp = cpr.compare(key, t.key);
//cmp返回值小于0,表示新增节点的key小于当前节点的key,则以当前节点的左子节点作为新的当前节点
if (cmp < 0)
t = t.left;
//cmp返回值大于0,表示新增节点的key大于当前节点的key,则以当前节点的右子节点作为新的当前节点
else if (cmp > 0)
t = t.right;
//cmp返回值等于0,表示两个key值相等,则新值覆盖旧值,并返回新值
else
return t.setValue(value);
} while (t != null);
}
//如果cpr为空,则采用默认的排序算法进行创建TreeMap集合
else {
if (key == null) //key值为空抛出异常
throw new NullPointerException();
/* 下面处理过程和上面一样 */
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//将新增节点当做parent的子节点
Entry<K,V> e = new Entry<>(key, value, parent);
//如果新增节点的key小于parent的key,则当做左子节点
if (cmp < 0)
parent.left = e;
//如果新增节点的key大于parent的key,则当做右子节点
else
parent.right = e;
/*
* 上面已经完成了排序二叉树的的构建,将新增节点插入该树中的合适位置
* 下面fixAfterInsertion()方法就是对这棵树进行调整、平衡,具体过程参考上面的五种情况
*/
fixAfterInsertion(e);
//TreeMap元素数量 + 1
size++;
//TreeMap容器修改次数 + 1
modCount++;
return null;
}
上面代码中do{}代码块是实现排序二叉树的核心算法,通过该算法我们可以确认新增节点在该树的正确位置。找到正确位置后将插入即可,这样做了其实还没有完成,因为我知道TreeMap的底层实现是红黑树,红黑树是一棵平衡排序二叉树,普通的排序二叉树可能会出现失衡的情况,所以下一步就是要进行调整。fixAfterInsertion(e); 调整的过程务必会涉及到红黑树的左旋、右旋、着色三个基本操作。
(4) ConcurrentHashMap
(5) ConcurrentSkipListMap
可以看到ConcurrentSkipListMap的数据结构使用的是跳表,每一个HeadIndex、Index结点都会包含一个对Node的引用,同一垂直方向上的Index、HeadIndex结点都包含了最底层的Node结点的引用。并且层级越高,该层级的结点(HeadIndex和Index)数越少。Node结点之间使用单链表结构。
public class ConcurrentSkipListMap<K,V> extends AbstractMap<K,V>
implements ConcurrentNavigableMap<K,V>, Cloneable, Serializable {}
















 1307
1307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









