







Murali R. Krishnan
Microsoft Corporation
February 1999
Summary: Discusses common heap performance problems and how to protect against them. (9 printed pages)
Introduction
Are you a happy-go-lucky user of dynamically allocated C/C++ objects? Do you use Automation extensively for communicating back and forth between modules? Is it possible that your program is slow because of heap allocation? You are not alone. Almost all projects run into heap issues sooner or later. The common tendency is to say, "It's the heap that's slow and my code is really good." Well, that is partially right. It pays to understand more about heap, its usage, and what can happen.
What Is a Heap?
(If you already know what a heap is, you can jump ahead to the section "What Are Common Heap Performance Problems?")
A heap is used for allocating and freeing objects dynamically for use by the program. Heap operations are called for when:
- The number and size of objects needed by the program are not known ahead of time.
- An object is too large to fit into a stack allocator.
A heap uses parts of memory outside of what is allocated for the code and stack during run time. The following graph shows the different layers of heap allocators.
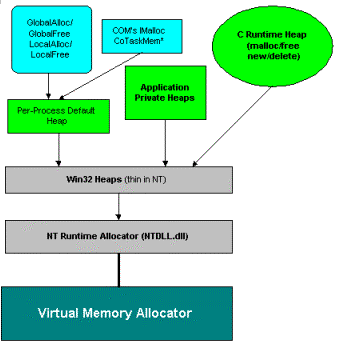
GlobalAlloc/GlobalFree: Heap calls that talk directly to the per-process default heap.
LocalAlloc/LocalFree: Heap calls that talk directly to the per-process default heap.
COM's IMalloc allocator (or CoTaskMemAlloc / CoTaskMemFree): Functions use the default per-process heap. Automation uses the Component Object Model (COM)'s allocator, and the requests use the per-process heap.
C/C++ Run-time (CRT) allocator: Provides malloc() and free() as well as new and delete operators. Languages like Microsoft Visual Basic® and Java also offer new operators and use garbage collection instead of heaps. CRT creates its own private heap, which resides on top of the Windows heap.
The Windows heap is a thin layer surrounding the Windows run-time allocator. All APIs forward their requests to the NTDLL.
The Windows run-time allocator provides the core heap allocator within Windows. It consists of a front-end allocator with 128 free lists for sizes ranging from 8 to 1,024 bytes. The back-end allocator uses virtual memory to reserve and commit pages.
At the bottom of the chart is the Virtual Memory Allocator, which reserves and commits pages used by the OS. All allocators use the virtual memory facility for accessing the data.
Shouldn't it be simple to allocate and free blocks? Why would this take a long time?
Notes on Heap Implementation
Traditionally, the operating system and run-time libraries come with an implementation of the heap. At the beginning of a process, the OS creates a default heap called Process heap. The Process heap is used for allocating blocks if no other heap is used. Language run times also can create separate heaps within a process. (For example, C run time creates a heap of its own.) Besides these dedicated heaps, the application program or one of the many loaded dynamic-link libraries (DLLs) may create and use separate heaps. Windows offers a rich set API for creating and using private heaps.
When applications or DLLs create private heaps, these live in the process space and are accessible process-wide. Any allocation of data made from a given heap should be freed for the same heap. (Allocation from one heap and free to another makes no sense.)
The heap sits on top of the operating system's Virtual Memory Manager in all virtual memory systems. The language run-time heaps reside on top of the virtual memory, as well. In some cases, these are layered on OS heaps, but the language run-time heap performs its own memory management by allocating large blocks. Bypassing the OS heap to use the virtual memory functions may enable a heap to do a better job of allocating and using blocks.
Typical heap implementations consist of front-end and back-end allocators. The front-end allocator maintains a free list of fixed-sized blocks. On an allocation call, the heap attempts to find a free block from the front-end list. If this fails, the heap is forced to allocate a large block from the back end (reserving and committing virtual memory) to satisfy the request. Common implementations have per-block allocation overhead, which costs execution cycles and also reduces available storage.
The Knowledge Base article Q10758, "Managing Memory with calloc() and malloc()" (search on article ID number), contains more background on these topics. Also, a detailed discussion on the heap implementations and designs can be found in "Dynamic Storage Allocation: A Survey and Critical Review" by Paul R. Wilson, Mark S. Johnstone, Michael Neely, and David Boles. In International Workshop on Memory Management, Kinross, Scotland, UK, September 1995 (http://www.cs.utexas.edu/users/oops/papers.html).
The implementation (Windows NT version 4.0 and later) uses 127 free lists of 8-byte aligned blocks ranging from 8 to 1,024 bytes and a grab-bag list. The grab-bag list (free list[0]) holds blocks greater than 1,024 bytes in size. The free list contains objects linked together in a doubly linked list. By default, the Process heap performs coalescing operations. (Coalescing is the act of combining adjacent free blocks to build a larger block.) Coalescing costs additional cycles but reduces internal fragmentation of heap blocks.
A single global lock protects the heap against multithreaded usage. (See the first commandment in Server Performance and Scalability Killers by George Reilly.) This lock is essential to protecting the heap data structures from random access across multiple threads. This lock can have an adverse impact on performance when heap operations are too frequent.
What Are Common Heap Performance Problems?
Here are the most common obstacles you will encounter when working with the heap:
- Slowdown as a result of allocation operations. It simply takes a long time to allocate. The most likely cause of the slowdown is that the free lists do not have the blocks, and hence the run-time allocator code spends cycles hunting for a larger free block or allocating a fresh block from the back-end allocator.
- Slowdown as a result of free operations. Free operations consume more cycles, mainly if coalescing is enabled. During coalescing, each free operation should "find" its neighbors, pull them out to construct a larger block, and reinsert the larger block into the free list. During that find, memory may be touched in a random order, causing cache misses and performance slowdown.
- Slowdown as a result of heap contention. Contention occurs when two or more threads try to access data at the same time and one must wait for the other to complete before it can proceed. Contention always causes trouble; it's by far the biggest problem that one encounters on multiprocessor systems. An application or DLL with heavy use of memory blocks will slow down when run with multiple threads (and on multiprocessor systems). The use of single lock—the common solution—means that all operations using the heap are serialized. The serialization causes threads to switch context while waiting for the lock. Imagine the slowdown caused by stop-and-go at a flashing red stoplight.
Contention usually leads to context switch of the threads and processes. Context switches are very costly, but even more costly is the loss of data from the processor cache and the rebuilding of that data when the thread is brought to life afterwards.
- Slowdown as a result of heap corruption. Corruption occurs when the application does not use the heap blocks properly. Common scenarios include double free or use of a block after a free, and the obvious problems of overwriting beyond block boundaries.
- Slowdown as a result of frequent allocs and reallocs. This is a very common phenomenon when you use scripting languages. The strings are repeatedly allocated, grown with reallocation, and freed up. Don't do this. Try to allocate large strings, if possible, and use the buffer. An alternative is to minimize concatenation operations.
Contention is the problem that introduces slowdown in the allocation as well as free operations. Ideally we would like to have a heap with no contention and fast alloc/free. Alas, such a general-purpose heap does not exist yet, though it might sometime in the future.
In all the server systems (such as IIS, MSProxy, DatabaseStacks, Network servers, Exchange, and others), the heap lock is a BIG bottleneck. The larger the number of processors, the worse the contention.
Protecting Yourself from the Heap
Now that you understand the problems with heap, don't you want the magic wand that can eliminate these problems? I wish there were one. But there is no magic to make the heap go faster—so don't expect to make things faster in the last week before shipping the product. Plan your heap strategy earlier, and you will be far better off. Altering the way you use the heap, and reducing the number of heap operations, is a solid strategy for improving performance.
How do you reduce the use of heap operations? You can reduce the number of heap operations by exploiting locality inside data structures. Consider the following example:
struct ObjectA {
// data for objectA
}
struct ObjectB {
// data for objectB
}
// Use of ObjectA and ObjectB together.
//
// Use pointers
//
struct ObjectB {
struct ObjectA * pObjA;
// data for objectB
}
//
// Use embedding
//
struct ObjectB {
struct ObjectA pObjA;
// data for objectB
}
//
// Aggregation – use ObjectA and ObjectB inside another object
//
struct ObjectX {
struct ObjectA objA;
struct ObjectB objB;
}
- Avoid using pointers for associating two data structures. If you use pointers to associate two data structures, the objects A and B from the preceding example will be allocated and freed separately. This is an additional cost—and is the practice we want to avoid.
- Embed pointed child objects into the parent object. Anytime we have a pointer in an object, it means we have a dynamic element (80 percent) and a new location to be dereferenced. Embedding increases locality and reduces the need for further allocation/free. This will improve the performance of your application.
- Combine smaller objects to form bigger objects (aggregation). Aggregation reduces the number of blocks allocated and freed up. If you have multiple developers working on various parts of a design, you may end up with many small objects that can be combined. The challenge of this integration is to find the right aggregation boundaries.
- Inline a buffer that can satisfy 80 percent of your needs (aka the 80-20 rule). In several situations, memory buffers are required for storing string/binary data and the total number of bytes is not known ahead of time. Take measurements and inline a buffer of a size that can satisfy 80 percent of your needs. For the remaining 20 percent, you can allocate a new buffer and have a pointer for that buffer. This way, you reduce the allocation and free calls as well as increase spatial locality of data, which ultimately will improve the performance of your code.
- Allocate objects in chunks (chunking). Chunking is a way of allocating objects in groups of more than one object at a time. If you have to keep track of a list of items, for example a list of {name, value} pairs, you have two options: Option 1 is to allocate one node per name-value pair. Option 2 is to allocate a structure that can hold, say, five name-value pairs. And if, for example, storing four pairs is a common scenario, you would reduce the number of nodes and the amount of extra space needed for additional linked-list pointers.
Chunking is processor cache-friendly, especially for the L1-cache, because of the increased locality it offers—not to mention that some of the data blocks are located in the same virtual page for chunked allocations.
- Use _amblksiz appropriately. The C run time (CRT) has its custom front-end allocator that allocates blocks in sizes of _amblksiz from the back end (Windows heap). Setting _amblksiz to a higher value can potentially reduce the number of calls made to the back end. This is applicable only to programs using the CRT extensively.
The savings you will gain by using the preceding techniques will vary with object types, sizes, and workload. But you will always gain in performance and scalability. On the downside, the code will be a bit specialized, but it can be manageable if well-thought-out.
More Performance Boosters
The following are a few more techniques for enhancing speed:
- Use the Windows heap
Thanks to the efforts and hard work of several folks, a few significant improvements went into Microsoft Windows 2000:
- Improved locking inside the heap code. The heap code uses one lock per heap. This global lock is used for protecting the heap data structure for multithreaded usage. Unfortunately, in high-traffic scenarios, a heap can still get bogged down in this global lock, leading to high contention and poor performance. On Windows 2000, the critical region of code inside locks is reduced to minimize the probability of contention, thus improving scalability.
- Use of Lookaside lists. The heap data structure uses a fast cache for all free items of blocks sized between 8 and 1,024 bytes (in 8-byte increments). The fast cache was originally protected within the global lock. Now lookaside lists are used to access the fast cache free list. These lists do not require locking, and instead use 64-bit interlocked operations, thus improving performance.
- Internal data structure algorithms are improved as well.
These improvements eliminate the need for allocation caches, but do not preclude other optimizations. Evaluate your code with the Windows heap; it should be optimal for blocks of less than 1,024 bytes (1 KB) (blocks from front-end allocator). GlobalAlloc() and LocalAlloc() build on the same heap and are common mechanisms to access the per-process heaps. Use Heap* APIs to access the per-process heap, or to create your own heaps for allocation operations if high localized performance is desired. You can also use VirtualAlloc() / VirtualFree() operations directly if needed for large block operations.
The described improvements made their way into Windows 2000 beta 2 and Windows NT 4.0 SP4. After the changes, the rate of heap lock contention fell significantly. This benefits all direct users of Windows heaps. The CRT heap is built on top of the Windows heap, but uses its own small-block heap and hence does not benefit from Windows changes. (Visual C++ version 6.0 also has an improved heap allocator.)
- Use allocation caches
An allocation cache allows you to cache allocated blocks for future reuse. This can reduce the number of alloc/free calls to the process heap (or global heap), as well as allow maximum reuse of the blocks once allocated. In addition, allocation caches permit you to gather statistics to gain a better understanding of object usage at the higher level.
Typically, a custom heap allocator is implemented on top of the process heap. The custom heap allocator behaves much like the system heap. The major difference is that it provides a cache on top of the process heap for the allocated objects. The caches are designed for a fixed set of sizes (for example, 32 bytes, 64 bytes, 128 bytes, and so on). This is a good strategy, but this sort of custom heap allocator misses the semantic information related to the objects that are allocated and freed.
In contrast to the custom heap allocators, "Alloc-caches" are implemented as a per-class allocation cache. They can retain a lot of semantic information, in addition to providing all the goodies of the custom heap allocator. Each allocation cache handler is associated with one object in the target binary. It can be initialized with a set of parameters indicating the concurrency level, size of the object, number of elements to keep in the free list, and so on. The allocation cache handler object maintains its own private pool of freed entities (not exceeding the specified threshold) and uses private lock for protection. Together, the allocation cache and private locks reduce the traffic to the main system heap, thus providing increased concurrency, maximum reuse, and higher scalability.
A scavenger is required periodically to check the activity of all the allocation cache handlers and reclaim unused resources. If and when no activity is found, the pool of allocated objects can be freed, thus improving performance.
Each alloc/free activity can be audited. The first level of information includes a total count of objects, allocations, and free calls made. You can derive the semantic relationship between various objects by looking at their statistics. The relationship can be used to reduce memory allocation using one of the many techniques just explained.
Allocation caches also act as a debugging aid in helping you track down the number of objects that are not properly cleaned up. You can even find exact callers in fault by looking at dynamic stack back traces and signatures in addition to the objects that were not cleaned up.
- MP heap
MP heap is a package for multiprocessor-friendly distributed allocation. Originally implemented by JVert, the heap abstraction here is built on top of the Windows heap package. MP heap creates multiple heaps and attempts to distribute allocation calls to different heaps with the goal of reducing the contention on any single lock.
This package is a good step—sort of an improved MP-friendly custom heap allocator. However, it offers no semantic information and lacks in statistics. A common way to use the MP heap is as an SDK library. You can benefit greatly if you create a reusable component with this SDK. If you build this SDK library into every DLL, however, you will increase your working set.
- Rethink algorithms and data structures
To scale on multiprocessor machines, algorithms, implementation, data structures, and hardware have to scale dynamically. Look at the data structures most commonly allocated and freed. Ask yourself, "Can I get the job done with a different data structure?" For example, if you have a list of read-only items that is loaded at application initialization time, this list does not need to be a linear-linked list. It can very well be a dynamically allocated array. A dynamically allocated array would reduce heap blocks in memory, reduce fragmentation, and therefore give you a performance boost.
Reducing the number of small objects needed reduces the load on the heap allocator. For example, we used five different objects in our server's critical processing path, each separately allocated and freed. Caching the objects together reduced heap calls from five to one and dramatically reduced the load on the heap, especially when we were processing more than 1,000 requests per second.
If you make extensive use of Automation structures, consider factoring out Automation BSTRs from your mainline code, or at least avoid repeated operations on BSTR. (BSTR concatenation leads to excessive reallocs and alloc/free operations.)
Summary
Heap implementations tend to stay general for all platforms, and hence have heavy overhead. Each individual's code has specific requirements, but design can accommodate the principles discussed in this article to reduce heap interaction.
- Evaluate the use of heap in your code.
- Streamline your code to use fewer heap calls: Analyze the critical paths and fix data structures.
- Make measurements to quantify the costs of heap calls before implementing custom wrappers.
- If you are unhappy about performance, ask the OS group to improve the heap. More requests of this sort mean more attention toward improving the heap.
- Ask the C run-time group to make the allocators thin wrappers on heaps provided by the OS. As a result, the cost of C run-time heap calls is reduced as the OS heap is improved.
- Heap improvements are continuously made in the operating system. Stay tuned and take advantage of the same.
Murali Krishnan is a lead software design engineer with the Internet Information Server (IIS) team. He has worked on IIS since version 1.0 and has successfully shipped versions 1.0 through 4.0. Murali formed and led the IIS performance team for three years (1995-1998), and has influenced IIS performance from day one. He holds an M.S. from the University of Wisconsin-Madison and a B.S. from Anna University, India, both in Computer Science. Outside work, he reads, plays volleyball, and cooks at home.















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









