







前言
突然有需求需要用apoc 导入 低版本的图谱数据,网上资料又比较少,所以就看官网资料并处理了apoc 导入的一些问题。
相关地址
docker 安装
执行如下命令启动镜像
docker run -d --name neo4j \
-p 7474:7474 -p 7687:7687 \
-v /home/neo4j/data:/var/lib/neo4j/data \
-v /home/neo4j/plugins:/var/lib/neo4j/plugins \
-v /home/neo4j/logs:/var/lib/neo4j/logs \
-v /home/neo4j/conf:/var/lib/neo4j/conf \
-v /home/neo4j/import:/var/lib/neo4j/import \
-e NEO4J_apoc_export_file_enabled=true \
-e NEO4J_apoc_import_file_enabled=true \
-e NEO4J_apoc_import_file_use__neo4j__config=true \
-e NEO4J_AUTH=neo4j/12345678 \
neo4j:5.19.0apoc安装
如果没有数据,可以执行下面的语句插入数据,后面导入导出用
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),
(LillyW)-[:DIRECTED]->(TheMatrix),
(LanaW)-[:DIRECTED]->(TheMatrix),
(JoelS)-[:PRODUCED]->(TheMatrix);从apoc 插件地址 下载 apoc-core-5.19.0 的jar,放到 /home/neo4j/plugins 下
然后编辑 /home/neo4j/conf/neo4j.conf ,添加如下配置
#没装成功的时候需要自己配置插件目录,成功了就不需要
#server.directories.plugins=/var/lib/neo4j/plugins
#下面两个官方是建议需要什么开放什么,我是直接全开放了
dbms.security.procedures.allowlist=apoc.*
dbms.security.procedures.unrestricted=apoc.*
#网上有出现上下面的配置,但是我不配置也没影响
#server.jvm.additional=Dapoc.export.file.enabled=true
#server.jvm.additional=Dapoc.import.file.enabled=true
server.directories.import=/var/lib/neo4j/import此处有个问题:由于我一开始配置的 neo4j 是别人装的,我将apoc插件放到挂载的 plugins 下,apoc没装成功,也没有错误,把我整蒙了,后面是在 stackoverflow 看到有人给了 server.directories.plugins 配置,试着配一下才成功的,主要是没装成功也看不到错误,排查起来比较费劲。,需要注意下。自己按上面的步骤应该安装是不需要配置的。
apoc导出
然后执行如下指令导出数据
CALL apoc.export.csv.all("movies.csv", {}) 如果出现如下界面,表示插件安装成功,数据导出成功,文件会导出到 /home/neo4j/import 下

如果出现下面的错误,就是要考虑配置 server.directories.plugins 了
There is no procedure with the name `apoc.export.csv.all` registered for this database instance. Please ensure you've spelled the procedure name correctly and that the procedure is properly deployed.
apoc导入
打开导出的csv 文件,数据格式如下图所示
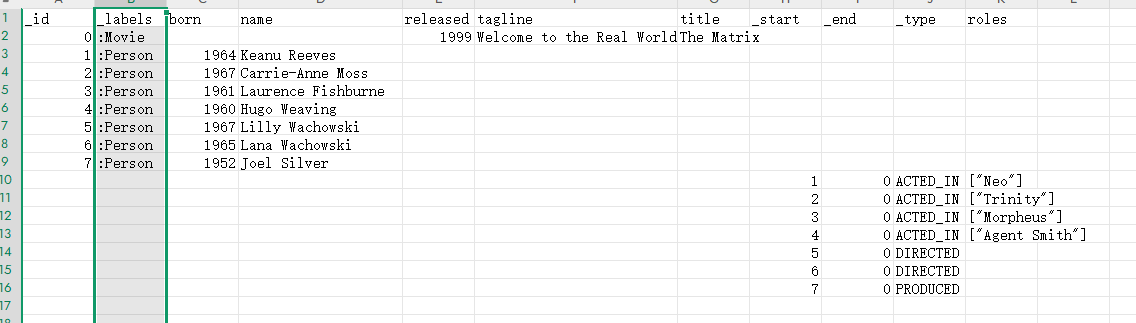
但是我当时用别人配置服务的数据导出的时候,csv内容如下所示,包括别人从3.x的版本导出的数据也是这样的数据,多出了重复的列名_type,_start_,_end
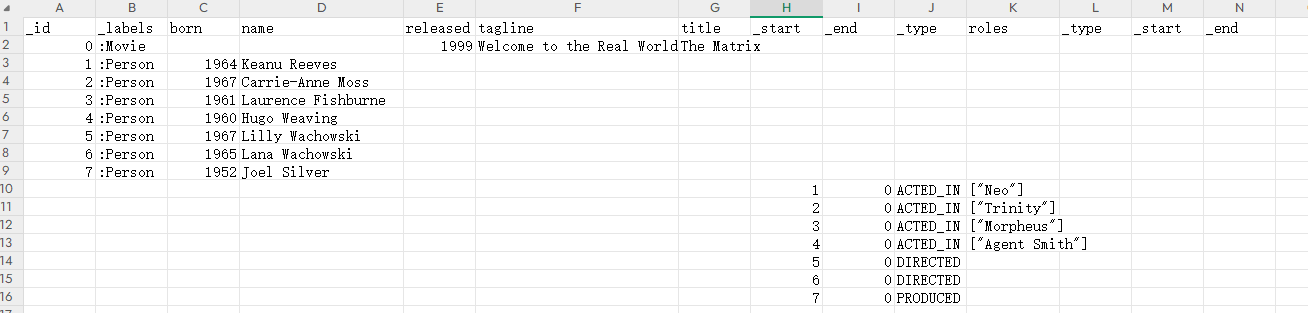 如果像上面一样有重复的标签,就需要自己删除重复的_type,_start_,_end标签,否则就会出现如下错误
如果像上面一样有重复的标签,就需要自己删除重复的_type,_start_,_end标签,否则就会出现如下错误
Failed to invoke procedure `apoc.import.csv`: Caused by: java.lang.IllegalStateException: Duplicate key _type (attempted merging values apoc.load.Mapping@45da0937 and apoc.load.Mapping@d89fe8
然后按如下要求修改movies.csv的内容:
1.将 _id 改成 oldId:ID
2.将 _labels 改为 :LABEL
3.将 _start 改为 oldId:START_ID
4.将 _end 改为 oldId:END_ID
5.将 _type 改为 :TYPE
6.将 _labels 那一列下面的值改成 Movie,Person 用逗号分隔多个标签,去掉所有冒号
我在基于上述需求改的时候,不小心把 :LABEL 敲成 :LABELS ,于是出现了如下的错误,看的我一脸懵逼
Failed to invoke procedure `apoc.import.csv`: Caused by: org.neo4j.internal.kernel.api.exceptions.schema.IllegalTokenNameException: '' is not a valid token name. Token names cannot be empty or contain any null-bytes.
之后如果基于上面的文件进行直接导入,会出现如下的错误,也很莫名其妙
Failed to invoke procedure `apoc.import.csv`: Caused by: java.lang.ClassCastException: class java.lang.String cannot be cast to class java.util.List (java.lang.String and java.util.List are in module java.base of loader 'bootstrap'
这是因为关系和节点都在同一个 csv 里面,需要拆成两个 csv,一个只有关系,一个只有节点,如下面的图片所示。
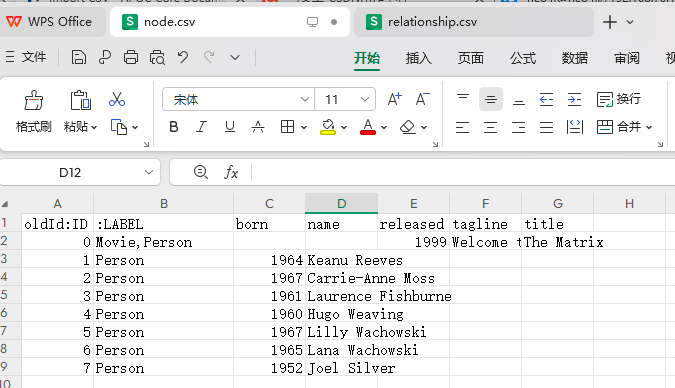
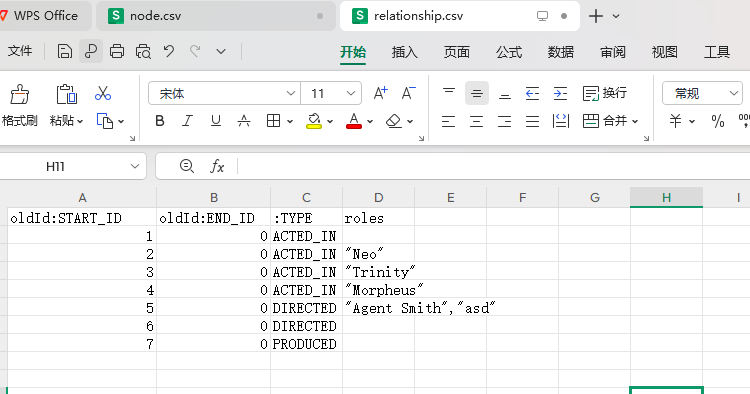
然后这两个文件都需要放到 /home/neo4j/import 里面
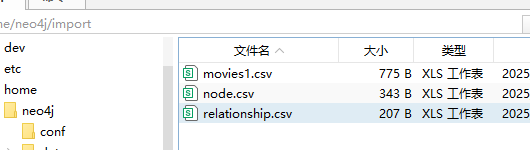
之后执行命令下面的指令(此处 labels 和 type 都不要传值,这两个配置是指定本次导入的节点配置的 label 和关系配置的 type,我们需要用的label 和 type 都在 csv 里,不需要自己指定)
CALL apoc.import.csv(
[{fileName: 'file:/node.csv', labels: []}],
[{fileName: 'file:/relationship.csv', type: ''}],
{ arrayDelimiter: ','}
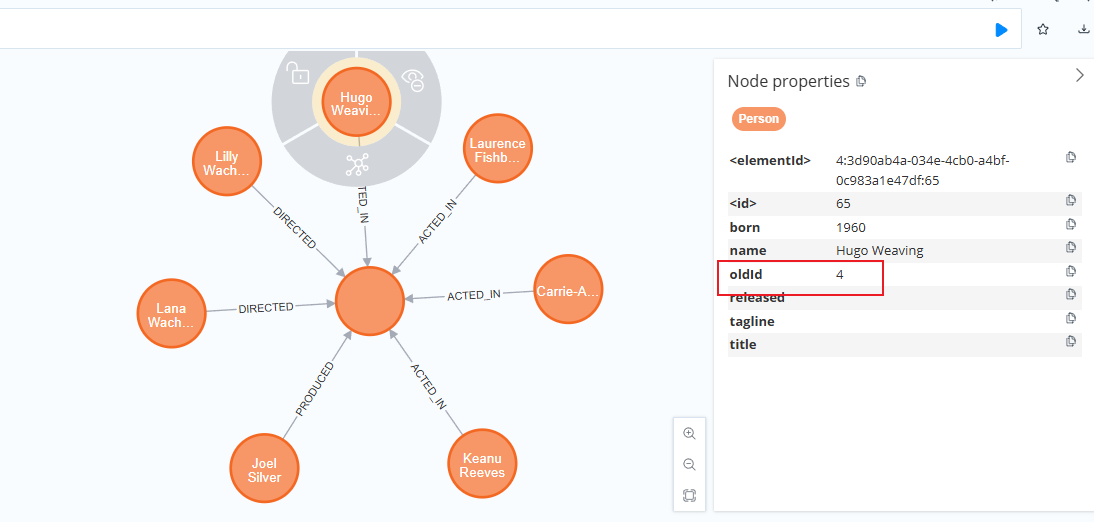
)如下结果表示成功

数据正常导入,原数据的 id 被作为 oldId 被插入到 neo4j 中
csv数据修改问题
1.我这个 demo 是因为数据量少,所以直接人工修改,不是很费劲,但是人工修改的时候需要注意编码问题,有些编辑工具如 excel 修改后再保存,会修改 csv 的编码,此时导入就会出现乱码,需要自己通过如 notepad 等其他工作,把编码改为UTF-8
2.当数据量特别多的时候,手动改就显得又卡,又难操作了,此时可以考虑参考下面的代码,然后基于自己的要求调整。(apoc 好像是使用opencsv 解析的,也可以考虑用opencsv)
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.7</version>
</dependency>try (Reader reader = Files.newBufferedReader(Paths.get("movies.csv"))) {
CSVPrinter csvPrinter = null;
boolean isFirst = true;
Iterable<CSVRecord> records = CSVFormat.DEFAULT.parse(reader);
int recordIndex = 0;
for (CSVRecord record : records) {
recordIndex++;
if (isFirst) {
isFirst = false;
List<String> heads = Lists.newArrayList();
int index = 0;
for (String s : record) {
index++;
heads.add(s);
}
csvPrinter = new CSVPrinter(
Files.newBufferedWriter(
new File("gen.csv").toPath(),
StandardOpenOption.CREATE, StandardOpenOption.WRITE
),
CSVFormat.DEFAULT.withHeader(
heads.toArray(
new String[heads.size()]
)
)
);
continue;
}
List<String> bodys = Lists.newArrayList();
int index = 0;
for (String s : record) {
if (index == 1) {
s = s.replaceAll(":", ";").replaceFirst(":", "");
}
index++;
bodys.add(s);
}
csvPrinter.printRecord(bodys.toArray(new String[bodys.size()]));
csvPrinter.flush();
}
}
















 4128
4128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









