







使用Spring访问 Apache Kafka(二)----producer发送消息
一、使用KafkaTemplate
KafkaTemplate 包装了一个producer并提供了方便的方法发送消息到kafka topic,以下是KafkaTemplate提供的发送相关的方法:
CompletableFuture<SendResult<K, V>> sendDefault(V data);
CompletableFuture<SendResult<K, V>> sendDefault(K key, V data);
CompletableFuture<SendResult<K, V>> sendDefault(Integer partition, K key, V data);
CompletableFuture<SendResult<K, V>> sendDefault(Integer partition, Long timestamp, K key, V data);
CompletableFuture<SendResult<K, V>> send(String topic, V data);
CompletableFuture<SendResult<K, V>> send(String topic, K key, V data);
CompletableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, V data);
CompletableFuture<SendResult<K, V>> send(String topic, Integer partition, Long timestamp, K key, V data);
CompletableFuture<SendResult<K, V>> send(ProducerRecord<K, V> record);
CompletableFuture<SendResult<K, V>> send(Message<?> message);
Map<MetricName, ? extends Metric> metrics();
List<PartitionInfo> partitionsFor(String topic);
<T> T execute(ProducerCallback<K, V, T> callback);
// Flush the producer.
void flush();
interface ProducerCallback<K, V, T> {
T doInKafka(Producer<K, V> producer);
}
sendDefault方法要求一个默认的topic提供给KafkaTemplate。
上面有方法是带有timestamp参数的,这个方法会把时间戳存储在消息记录里。在broker中,用户提供的timestamp是否被使用取决于kafka topic配置的message.timestamp.type参数,如果参数值为CreateTime,用户提供的timestamp会被使用,如果参数值为LogAppendTime,broker会将服务器本地时间填入。配置message.timestamp.type可以在创建topic时指定,如下:
kafka-topics.sh --zookeeper 127.0.0.1:2181/kafka \
--create \
--topic test.4 \
--partitions 1 --replication-factor 1 \
--config message.timestamp.type=CreateTime
metrics 和 partitionsFor 两个方法会直接调用Producer对应的方法。metrics 返回kafka的度量指标,partitionsFor 返回某个topic的分区和副本信息。execute方法可以接收一个lambda表达式,如下:
template.execute((e) -> e.send(new ProducerRecord<>("topicx","execute")));
如果你不打算使用Spring-kafka默认的producer参数,可以这样初始化和使用KafkaTemplate
@Bean
public ProducerFactory<Integer, String> kafkaProducerFactory() {
Map<String, Object> producerProperties = new HashMap<>();
producerProperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092,localhost:9093");
producerProperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
producerProperties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
producerProperties.put(ProducerConfig.LINGER_MS_CONFIG, 5000);
producerProperties.put(ProducerConfig.BATCH_SIZE_CONFIG,20480);
DefaultKafkaProducerFactory<Integer, String> factory = new DefaultKafkaProducerFactory<>(producerProperties);
return factory;
}
@Bean
public KafkaTemplate<Integer, String> kafkaTemplate() {
return new KafkaTemplate<Integer, String>(kafkaProducerFactory());
}
@Bean
public ApplicationRunner runner1(KafkaTemplate<Integer, String> template) {
return (args) -> {
System.out.println("-----------send test-----------");
template.send("test1", "{'name':'test24010306'}");
};
}
ProducerFactory这个bean设置了producer的各项属性,包括bootstrap.servers,key.serializer,value.serializer,batch.size,linger.ms,这里batch.size=20kB,是指批量发送的消息大小以20KB为单位,linger.ms=5000ms是指消息延迟5秒发送,当batch.size和linger.ms中的一个条件先达到时,producer发送数据到broker。
默认情况下,KafkaTemplate配置了一个LoggingProducerListener,这个Listener会记录错误,但当发送成功时不做任何事情。
注意send方法返回的是CompletableFuture,你可以注册一个回调函数来异步接收发送的结果:
@Bean
public ApplicationRunner runner1(KafkaTemplate<Integer, String> template) {
return (args) -> {
String topic = "test1";
String value = "{'name':'test24010309'}";
CompletableFuture<SendResult<Integer, String>> future = template.send(topic, value);
future.whenComplete((result, ex) -> {
if (ex == null) {
//handleSuccess(result);
}
else {
//handleFailure(result, ex);
}
});
};
}
你可以调用future的get()方法,这将阻塞发送线程以同步的方式获取发送结果:
@Bean
public ApplicationRunner runner2(KafkaTemplate<Integer, String> template) {
return (args) ->{
String topic = "test1";
String value = "{'name':'test24010310'}";
try {
ProducerRecord<Integer,String> record = new ProducerRecord<>(topic, value);
SendResult<Integer, String> result = template.send(record).get(10, TimeUnit.SECONDS);
//handleSuccess(result);
}
catch (ExecutionException e) {
//handleFailure(topic,value, e.getCause());
}
catch (TimeoutException | InterruptedException e) {
//handleFailure(topic,value, e);
}
};
}
其中get()方法的超时时间为10秒。handleSuccess()为消息发送成功的处理逻辑,handleFailure()为消息发送失败的处理逻辑。
二、使用RoutingKafkaTemplate
使用RoutingKafkaTemplate可以在运行时根据topic名字选择不同的producer,这个RoutingKafkaTemplate不支持事务,execute, flush 和 metrics操作。RoutingKafkaTemplate的构造方法需要一个map作为参数,map的key为java.util.regex.Pattern(这个正则表达式匹配的是topic的名字),map的value为ProducerFactory<Object, Object>,另外这个map需要是有序的(LinkedHashMap),因为它会被顺序遍历。以下例子展示了RoutingKafkaTemplate选择不同的producer发送不同消息,每个producer配置了不同的value.serializer:
@SpringBootApplication
public class RoutingKafkaTemplateApplication {
public static void main(String[] args) {
SpringApplication.run(RoutingKafkaTemplateApplication.class, args);
}
@Bean
public RoutingKafkaTemplate routingTemplate(GenericApplicationContext context,
ProducerFactory<Object, Object> pf) {
// 克隆producer factory,并且设置一个不同的value.serializer
Map<String, Object> configs = new HashMap<>(pf.getConfigurationProperties());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
DefaultKafkaProducerFactory<Object, Object> valueIntPF = new DefaultKafkaProducerFactory<>(configs);
Map<Pattern, ProducerFactory<Object, Object>> map = new LinkedHashMap<>();
map.put(Pattern.compile("two"), valueIntPF);//克隆的producer factory的value.serializer配置了IntegerSerializer
map.put(Pattern.compile(".+"), pf); // 默认 producer factory 的value.serializer配置了StringSerializer
return new RoutingKafkaTemplate(map);
}
@Bean
public ApplicationRunner runner(RoutingKafkaTemplate routingTemplate) {
return args -> {
routingTemplate.send("test1", "thing1");
routingTemplate.send("two", 555);
};
}
}
三、使用DefaultKafkaProducerFactory
当我们使用KafkaTemplate,一个ProducerFactory会被用来创建producer。当不使用事务时,默认情况下DefaultKafkaProducerFactory会创建一个单例的producer被所有客户端线程使用,但是,当你调用KafkaTemplate的flush()时,使用同一个producer的其他线程会出现延迟的现象。现在DefaultKafkaProducerFactory 有一个新的属性producerPerThread,当设置为true,DefaultKafkaProducerFactory会为每个线程创建一个独立的producer,这样,前面提到的延迟现象就消失了。另外,当producerPerThread是true的时候,如果一个producer不再需要,用户代码必须调用DefaultKafkaProducerFactory的closeThreadBoundProducer(),这个方法会物理性关闭producer,并且把它从ThreadLocal移除。调用reset()和destroy() 不会清除这些producer。
当创建一个DefaultKafkaProducerFactory时,key.serializer和value.serializer可以通过配置参数(properties map)传入构造方法,也可以传Serializer实例到构造方法。再或者你可以提供Supplier到构造方法,它会被用来为每个producer获取单独的Serializer实例:
@Bean
public ProducerFactory<Integer, CustomValue> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs(), null, () -> new CustomValueSerializer());
}
@Bean
public KafkaTemplate<Integer, CustomValue> kafkaTemplate() {
return new KafkaTemplate<Integer, CustomValue>(producerFactory());
}
现在,你可以在ProducerFactory创建之后更新producer的配置。这个也许会有用,比如credentials 发生了变更,你要更新ssl key/trust store locations。这些变更不会影响已存在的producer实例,需要调用reset()来关闭已存在的producer,然后新的producer会以新的配置被创建。注意,开启事务的producer factory不能被改为非事务的,反之亦然。ProducerFactory中更新配置和移除配置的方法如下:
void updateConfigs(Map<String, Object> updates);
void removeConfig(String configKey);
如果你以对象的方式提供serializer(通过构造方法或者setter),ProducerFactory会调用configure()方法以configuration properties配置serializer。
四、使用ReplyingKafkaTemplate
ReplyingKafkaTemplate 是KafkaTemplate 的子类,实现了request/reply语义,它新增的两个方法如下:
RequestReplyFuture<K, V, R> sendAndReceive(ProducerRecord<K, V> record);
RequestReplyFuture<K, V, R> sendAndReceive(ProducerRecord<K, V> record,
Duration replyTimeout);
结果是CompletableFuture类型 ,这个类会被结果异步填充,结果还有一个sendFuture 属性,是调用KafkaTemplate.send()的结果。你可以用这个sendFuture 来确定发送操作的结果。
如果上面第一个方法被调用,replyTimeout 属性就为null,ReplyingKafkaTemplate的defaultReplyTimeout 属性会被使用,默认为5秒。
ReplyingKafkaTemplate有一个waitForAssignment方法非常有用,如果reply容器配置为auto.offset.reset=latest,它可以避免ReplyingKafkaTemplate在reply容器初始化之前发送请求和接收应答。
当使用手动分配分区时,waitForAssignment等待的时间必须大于reply容器的pollTimeout 属性,因为notification 要等到第一次poll 完成才发送。
以下代码展示了如何使用ReplyingKafkaTemplate,producer端:
@SpringBootApplication
public class KRequestingApplication {
public static void main(String[] args) {
SpringApplication.run(KRequestingApplication.class, args).close();
}
@Bean
public ApplicationRunner runner(ReplyingKafkaTemplate<String, String, String> template) {
return args -> {
if (!template.waitForAssignment(Duration.ofSeconds(10))) {
throw new IllegalStateException("Reply container did not initialize");
}
ProducerRecord<String, String> record = new ProducerRecord<>("kRequests", "foo");
RequestReplyFuture<String, String, String> replyFuture = template.sendAndReceive(record);
SendResult<String, String> sendResult = replyFuture.getSendFuture().get(10, TimeUnit.SECONDS);
System.out.println("Sent ok: " + sendResult.getRecordMetadata());
ConsumerRecord<String, String> consumerRecord = replyFuture.get(10, TimeUnit.SECONDS);
System.out.println("Return value: " + consumerRecord.value());
};
}
@Bean
public ReplyingKafkaTemplate<String, String, String> replyingTemplate(
ProducerFactory<String, String> pf,
ConcurrentMessageListenerContainer<String, String> repliesContainer) {
return new ReplyingKafkaTemplate<>(pf, repliesContainer);
}
@Bean
public ConcurrentMessageListenerContainer<String, String> repliesContainer(
ConcurrentKafkaListenerContainerFactory<String, String> containerFactory) {
ConcurrentMessageListenerContainer<String, String> repliesContainer =
containerFactory.createContainer("kReplies");
repliesContainer.getContainerProperties().setGroupId("repliesGroup");
repliesContainer.setAutoStartup(false);
return repliesContainer;
}
@Bean
public NewTopic kRequests() {
return TopicBuilder.name("kRequests")
.partitions(10)
.replicas(2)
.build();
}
@Bean
public NewTopic kReplies() {
return TopicBuilder.name("kReplies")
.partitions(10)
.replicas(2)
.build();
}
}
repliesContainer创建了一个reply容器,并且指定了kReplies作为reply topic
replying端:
@SpringBootApplication
public class KReplyingApplication {
public static void main(String[] args) {
SpringApplication.run(KReplyingApplication.class, args);
}
@KafkaListener(id="server", topics = "kRequests")
@SendTo
public String listen(String in) {
System.out.println("Server received: " + in);
return in.toUpperCase();
}
@Bean // 如果Jackson 在classpath,则不需要这个
public MessagingMessageConverter simpleMapperConverter() {
MessagingMessageConverter messagingMessageConverter = new MessagingMessageConverter();
messagingMessageConverter.setHeaderMapper(new SimpleKafkaHeaderMapper());
return messagingMessageConverter;
}
}
replying端监听kRequests topic,收到消息后转为大写,将消息再发回到kReplies topic,这时producer端会打印“Return value: FOO”。
ReplyingKafkaTemplate使用默认的header KafKaHeaders.REPLY_TOPIC来指明reply要发往的topic。ReplyingKafkaTemplate尝试从配置好的reply容器发现reply topic和partition,如果reply容器被配置为监听一个单独的topic或者一个单独的TopicPartitionOffset,这些信息会被用来设置reply header;如果reply容器没有像前面这样配置,用户必须设置reply headers,以下代码设置了reply topic:
record.headers().add(new RecordHeader(KafkaHeaders.REPLY_TOPIC, "kReplies".getBytes()));
使用单个reply TopicPartitionOffset进行配置时,只要每个template监听在不同的分区上,你就可以对多个template使用相同的reply topic。使用单个reply topic进行配置时,每个template实例必须使用不同的group.id。在这种情况下,所有template实例都收到每条reply,但只有发送请求的实例才能找到correlation ID。这可能对auto-scaling有帮助,但会带来额外的网络流量开销和丢掉每条不需要的reply的小开销,当你使用前面所述的配置,建议你把 template的 sharedReplyTopic设置为true,它可以改变不需要的reply的日志记录级别到DEBUG,而不是ERROR。
以下的例子是配置reply容器来使用相同的shared reply topic:
@Bean
public ConcurrentMessageListenerContainer<String, String> replyContainer(
ConcurrentKafkaListenerContainerFactory<String, String> containerFactory) {
ConcurrentMessageListenerContainer<String, String> container = containerFactory.createContainer("topic2");
container.getContainerProperties().setGroupId(UUID.randomUUID().toString()); // 唯一的UUID
Properties props = new Properties();
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest"); // 新的group不会消费到旧replies
container.getContainerProperties().setKafkaConsumerProperties(props);
return container;
}
如果你有多个客户端实例(template),并且你没有像前面叙述的方式来配置它们,每个template需要一个专用的reply topic。另一个方法是设置KafkaHeaders.REPLY_PARTITION,为每个template实例设置专用的分区。Header包含了一个four-byte的 int (big-endian)。replying服务器必须用这个头把reply路由到正确的分区(@KafkaListener在做这个)。在这种情况下,reply容器一定不能使用Kafka的group management功能,并且必须让reply容器监听在固定的分区(在ContainerProperties的构造方法中传入一个TopicPartitionOffset)。
DefaultKafkaHeaderMapper需要classpath中有Jackson。如果没有,消息转换器就没有header的mapper,所以需要创建一个MessagingMessageConverter,并且配置header mapper为SimpleKafkaHeaderMapper(如前面replying端代码)。
默认情况下3个headers被使用:
- KafkaHeaders.CORRELATION_ID–用来将reply关联到一个request
- KafkaHeaders.REPLY_TOPIC–用来告诉replying服务器回复到哪里
- KafkaHeaders.REPLY_PARTITION(可选)–用来告诉replying服务器回复到哪个分区
@KafkaListener使用这些header信息来路由reply。
另外,你可以修改headers的名字,template有相应的3个属性,correlationHeaderName、 replyTopicHeaderName 和 replyPartitionHeaderName。如果你的replying服务器不是spring应用,或者没有使用@KafkaListener,你就可以定制3个header的名字。
ReplyingKafkaTemplate有几个发送并接收方法使用了spring-messaging的 Message<?> 的参数。
RequestReplyMessageFuture<K, V> sendAndReceive(Message<?> message);
<P> RequestReplyTypedMessageFuture<K, V, P> sendAndReceive(Message<?> message, ParameterizedTypeReference<P> returnType);
以上方法使用了默认的replyTimeout,还有重载的方法可以接收一个超时值。
如果consumer的Deserializer或者template的MessageConverter可以通过配置或者reply消息中的类型元数据在没有额外信息的情况下可以转换payload,使用第一个方法。
如果需要为返回类型提供类型信息,使用第二个方法,来协助消息转换器。这也允许同一个template接收不同的类型,即使reply中没有类型元数据,例如replying服务器不是spring应用时。
以下是调用第二个方法的例子:
@Bean
ReplyingKafkaTemplate<String, String, String> template(
ProducerFactory<String, String> pf,
ConcurrentKafkaListenerContainerFactory<String, String> factory) {
ConcurrentMessageListenerContainer<String, String> replyContainer =
factory.createContainer("replies");
replyContainer.getContainerProperties().setGroupId("request.replies");
ReplyingKafkaTemplate<String, String, String> template =
new ReplyingKafkaTemplate<>(pf, replyContainer);
template.setMessageConverter(new ByteArrayJsonMessageConverter());
template.setDefaultTopic("requests");
return template;
}
RequestReplyTypedMessageFuture<String, String, Thing> future1 =
template.sendAndReceive(MessageBuilder.withPayload("getAThing").build(),
new ParameterizedTypeReference<Thing>() { });
log.info(future1.getSendFuture().get(10, TimeUnit.SECONDS).getRecordMetadata().toString());
Thing thing = future1.get(10, TimeUnit.SECONDS).getPayload();
log.info(thing.toString());
RequestReplyTypedMessageFuture<String, String, List<Thing>> future2 =
template.sendAndReceive(MessageBuilder.withPayload("getThings").build(),
new ParameterizedTypeReference<List<Thing>>() { });
log.info(future2.getSendFuture().get(10, TimeUnit.SECONDS).getRecordMetadata().toString());
List<Thing> things = future2.get(10, TimeUnit.SECONDS).getPayload();
things.forEach(thing1 -> log.info(thing1.toString()));
在replying服务器端,当@KafkaListener返回一个Message<?>类型的消息,框架会检测headers是否丢失,并且使用topic填充他们,这个topic可能来自@SendTo的定义或者接收到的KafkaHeaders.REPLY_TOPIC。框架还会返回KafkaHeaders.CORRELATION_ID和KafkaHeaders.REPLY_PARTITION。
@KafkaListener(id = "requestor", topics = "request")
@SendTo // 此处没有定义topic,会使用 REPLY_TOPIC header
public Message<?> messageReturn(String in) {
return MessageBuilder.withPayload(in.toUpperCase())
.setHeader(KafkaHeaders.KEY, 42)
.build();
}
五、使用AggregatingReplyingKafkaTemplate
ReplyingKafkaTemplate是严格应对用户单条request/reply的场景。面对多个接收者接收同一条数据并返回消息的场景,你可以使用AggregatingReplyingKafkaTemplate。这是客户端的Scatter-Gather Enterprise Integration Pattern的实现。
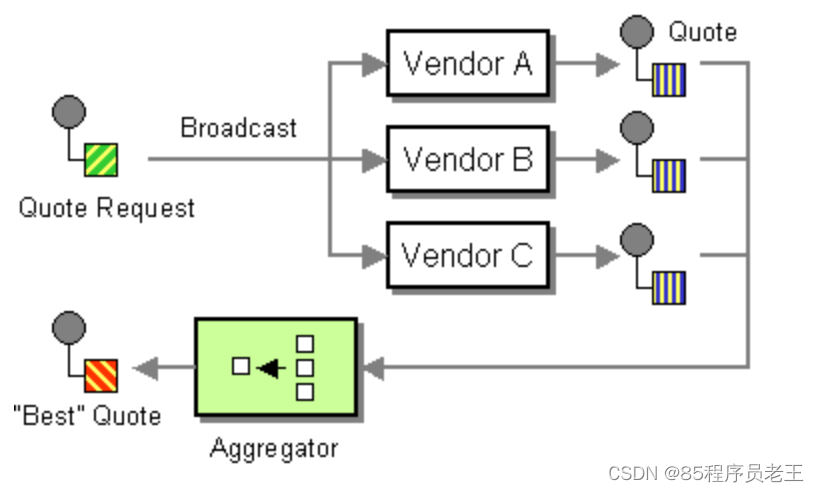
类似于ReplyingKafkaTemplate,AggregatingReplyingKafkaTemplate的构造方法接收producer factory和listener container;AggregatingReplyingKafkaTemplate还有第三个参数BiPredicate<List<ConsumerRecord<K, R>>, Boolean> releaseStrategy,这个BiPredicate在每次收到reply的时候都会被执行一次;当predicate返回为true的时候,ConsumerRecord的集合被用于完成sendAndReceive返回的Future。
还有一个叫做returnPartialOnTimeout的属性,默认值是false,当它被设置为true的时候一个partial result正常完成了future(只要收到了一条reply的消息),而不是以KafkaReplyTimeoutException完成future。
当returnPartialOnTimeout被谁知为true并且发生了超时,predicate会被执行。第一个参数是当前的记录列表,第二个参数是true。predicate可以修改记录列表。
AggregatingReplyingKafkaTemplate<Integer, String, String> template =
new AggregatingReplyingKafkaTemplate<>(producerFactory, container,
coll -> coll.size() == releaseSize);
...
RequestReplyFuture<Integer, String, Collection<ConsumerRecord<Integer, String>>> future =
template.sendAndReceive(record);
future.getSendFuture().get(10, TimeUnit.SECONDS); // send ok
ConsumerRecord<Integer, Collection<ConsumerRecord<Integer, String>>> consumerRecord =
future.get(30, TimeUnit.SECONDS);
注意,返回值是ConsumerRecord,它的value是ConsumerRecords的集合。外部的ConsumerRecord不是真的record,它是被template合成的做为一个请求的实际reply records的持有者。当一个正常的release发生(releaseStrategy返回true),topic被设置为aggregatedResults;如果returnPartialOnTimeout被设置为true,并且发生了超时,然后至少收到了一条reply,topic被设置为partialResultsAfterTimeout。template为这些topic名称提供了constant static变量:
/**
* Pseudo topic name for the "outer" {@link ConsumerRecords} that has the aggregated
* results in its value after a normal release by the release strategy.
*/
public static final String AGGREGATED_RESULTS_TOPIC = "aggregatedResults";
/**
* Pseudo topic name for the "outer" {@link ConsumerRecords} that has the aggregated
* results in its value after a timeout.
*/
public static final String PARTIAL_RESULTS_AFTER_TIMEOUT_TOPIC = "partialResultsAfterTimeout";
内层的集合中的ConsumerRecords包含了接收到了reply的真正topic的名字。
listener容器必须为reply配置成AckMode.MANUAL或者 AckMode.MANUAL_IMMEDIATE;consumer的enable.auto.commit属性设置为false,为了避免任何丢失消息的可能性,template只在没有未处理请求的时候提交偏移,例如,在最后一个未决请求被releaseStrategy释放的时候。在rebalance发生之后,有可能会有重复的reply,这些会被任何正在发生的请求忽略;当收到已发布的reply的重复消息时你可能看到错误日志。
如果你使用了ErrorHandlingDeserializer配合AggregatingReplyingKafkaTemplate,框架不会自动检测DeserializationException。相反,带有null值的记录会原封不动地返回,headers中会出现deserialization异常。建议程序调用工具方法ReplyingKafkaTemplate.checkDeserialization() 来确定是否有deserialization异常发生。replyErrorChecker也没有被template调用,你需要在reply的每个元素上做检查。














 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









