






结合网上的资料与李宏毅老师的课堂教学,总结一下optimization的方法。如果以对训练结果不满意,可以尝试用下述的方法,可以优先考虑方法1-4、方法6
方法1:正则化(Regularization)
正则化是防止神经网络overfitting的一种方法,由于模型的参数太多,所以就容易过拟合(可以想象一下决策树需要剪枝),其原理是在损失函数中增加一个惩罚项来限制过大的权重。通常有3种方法:L1正则化,L2正则化,dropout
L1正则化,江湖中也人称Lasso,表示各个参数绝对值之和:它之所以可以防止过拟合,是因为它将各个参数的绝对值相加放在损失函数后面,参数值大小和模型复杂度是成正比的。因此复杂的模型,其L1范数就大,最终导致损失函数就大,说明这个模型就不够好。L2正则化,江湖人称Ridge,也称“岭回归”,表示各个参数的平方的和的开方值。dropout:dropout 为该网络每一层的神经元设定一个失活(drop)概率,在神经网络训练过程中,我们会丢弃一些神经元节点,在网络图上则表示为该神经元节点的进出连线被删除。最后我们会得到一个神经元更少、模型相对简单的神经网络。 因为 dropout 可以随时随机的丢弃任何一个神经元,神经网络的训练结果不会依赖于任何一个输入特征,每一个神经元都以这种方式进行传播
在pytorch中只有L2正则化和dropout方法,若想实现L1正则,需要自己手动完成。pytorch中L2正则是通过优化器中参数(weight_decay)实现的,示例代码# L2正则化 optim_wdecay = torch.optim.SGD(model.parameters(), lr=lr_init, weight_decay=1e-2) # dropout nn.Linear(1, neural_num), nn.ReLU(inplace=True), nn.Dropout(p=0.5), # p是被舍弃的概率,也叫失活概率 dropout通常放在每个网路层的最前面 nn.Linear(neural_num, neural_num), nn.ReLU(inplace=True), nn.Dropout(p=0.5), nn.Linear(neural_num, neural_num), nn.ReLU(inplace=True),
方法2:batch normlization
将数据变化在同一个scale中,具有相同的数值范围,这样不至于error surface有的地方平坦,有的地方陡峭,更新参数时可能会出问题。我们把不同笔资料即不同 feature vector,同一个 dimension 裡面的数值,把它取出来,然后去计算某一个
dimension 的 mean和std。
又因为我们无法将全部的feature都读进来,然后保存每一个的mean和std,没有这么大的内存啊,所以我们就一次只对一个batch做归一化。

方法3:learning rate
(1) adaptive learning rate
自适应学习率,主要介绍四种方法:momentum、Adagrad、RMSProp、Adam
-
Momentum:
1、Momentum:这是一个有可能对抗 Saddle Point,或 Local Minima 的技术,Momentum的运作是这个样子的:在物理的世界裡,一个球如果从高处滚下来,就算滚到 Saddle Point,如果有惯性,它还是会继续往右走,甚至它走到一个 Local Minima,如果今天它的动量够大的话,它还是会继续往右走,甚至翻过这个小坡。
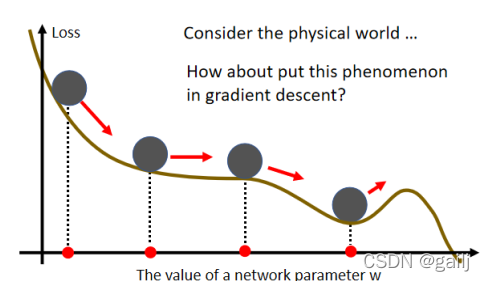
因此,我们每一次更新梯度,都采用Gradient 的负反方向加上前一次移动的方向,将两者加起来的结果,去调整去我们的参数。因为每一次都是与前一次的方向相加,因此也可以认为我们 Update的方向,不是只考虑现在的 Gradient,而是考虑过去所有 Gradient 的总和。

该方法调用nn.optim.SGD(momentum = XXX)说白了,该方法就是在原先更新参数的公式上加上一个向量 -
Adagrad:
2、Adagrad:在坡度比较大的时候,learning rate就减小,坡度比较小的时候,learning rate就大。很好的考虑了稀疏性(适合NLP问题)

它是通过将学习率η除以一个数σ,这个被除的数σ会根据之前的梯度来自动变化(gradient的平方和取平均再开根号)。如果这个地方斜率大,比较陡峭,那么σ就大,整体学习率η就低,就不容易错过很多信息(陡峭的地方肯定希望慢点更新)。 -
RMSProp:
3、RMSProp:每一个gradient的重要性不同(例如肯定希望离自己近的gradient重要)

在RMSProp裡面,它决定你可以自己调整,现在的这个gradient,你觉得它有多重要。如果我今天α设很小趋近於0,就代表我觉得gᵢ¹相较於之前所算出来的gradient而言,比较重要我α设很大趋近於1,那就代表我觉得现在算出来的gᵢ¹比较不重要,之前算出来的gradient比较重要。 -
Adam:
4、Adam:是今天最常用的优化方法,Adam = RSMPorp + Momentum
可能有人会觉得很困惑,这一个momentum是考虑过去所有的gradient,这个σ也是考虑过去所有的gradient,一个放在分子一个放在分母,都考虑过去所有的gradient,不就是正好抵销了吗?
但是其实这个Momentum跟这个σ,它们在使用过去所有gradient的方式是不一样的,Momentum是直接把所有的gradient通通都加起来,所以它有考虑方向,它有考虑gradient的正负号,它有考虑gradient是往左走还是往右走
(2) learning rate schedule
首先一定要分清楚adaptive learning rate 和 learning rate schedule的区别。前者是作用在优化器上的,并不是直接改变学习率η,而是通过对当前训练的感知,对η加上减去除以一个数而已,η本身可以是一个常数。后者是直接对η下手,改变η,这时候η就不是一个常数了。
这里介绍两种最常见的的学习率调度方法:learning rate decay 和 warm up
-
learning rate decay:

随着时间的变化,学习率逐渐变小。因為一开始我们距离终点很远,随著参数不断update,我们距离终点越来越近,所以我们把learning rate减小,让我们参数的更新踩了一个刹车,让我们参数的更新能够慢慢地慢下来,这时候就需要微调了,就是猛地往前冲了。 -
warm up:
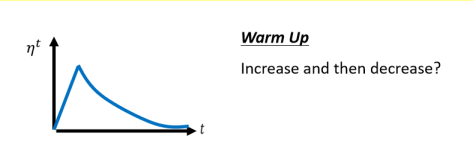
Warm Up这个方法,听起来有点匪夷所思,这Warm Up的方法是让learning rate,要先变大后变小,你会问说 变大要变到多大呢,变大速度要多快呢 , 小速度要多快呢,这个也是hyperparameter。
这边有一个可能的解释是说,你想想看当我们在用Adam RMSProp,或Adagrad的时候,我们会需要计算σ,它是一个统计的结果,σ告诉我们,某一个方向它到底有多陡,或者是多平滑,那这个统计的结果,要看得够多笔数据以后,这个统计才精确,所以一开始我们的统计是不精确的,所以我们一开始不要让我们的参数,走离初始的地方太远,先让它在初始的地方呢,做一些像是探索这样,所以一开始learning rate比较小,等σ统计得比较精準以后,在让learning rate慢慢地爬升。#TODO 这里补上pytorch代码,等用过了再写
方法4:early stopping
根据训练过程中的表现,设置程序提前中止,可以防止训练集过拟合。
早停法是一种被广泛使用的方法,在很多案例上都比正则化的方法要好。其基本含义是在训练中计算模型在验证集上的表现,当模型在验证集上的表现开始下降的时候,停止训练,这样就能避免继续训练导致过拟合的问题。其主要步骤如下:
- 将原始的训练数据集划分成训练集和验证集
- 只在训练集上进行训练,并每隔一定周期计算模型在验证集上的误差(mini batch训练中的一个周期)
- 当模型在验证集上的误差比上一次训练结果差的时候停止训练
- 使用上一次迭代结果中的参数作为模型的最终参数
然而,模型在验证集上的误差不会一直平滑单调的,模型在验证集上的表现可能咱短暂的变差之后有可能继续变好。因此要制定合理的停止标准。这里可参考三种停止标准
当然,这里也不一定要自己写early stopping, 读者们可以直接去github里把其中的 pytorchtools.py 下载(或复制)下来并放置在项目中,这样就可以正常执行 from pytorchtools import EarlyStopping 并使用early stopping,具体使用方法参考:https://blog.csdn.net/qq_37430422/article/details/103638681
方法5:参数初始化:参考

有多种参数初始化的方法,适用于不同的激活函数、神经网络等,一个良好的初始化策略会使得训练更容易。
例如 xavier初始化 (归一化初始化) :当激活函数是sigmoid时,使用标准初始化往往性能比较差,收敛较慢且容易陷入局部最优。“xavier”初始化是一种有效的神经网络舒适化方法,配合tanh等函数能够获得比较好的效果。定义参数所在层的输入维度为n,输出维度为m,则参数均匀分布在:

主要思想:尽可能保证前向传播和反向传播时每一层的方差尽量相等
推导前提:激活函数是线性的 ReLU 和 PReLU不满足这一条件
例如 MSRA初始化(又称He初始化) :来自于MSRA研究员何恺明2015年论文,传统的固定方差的高斯分布初始化,在网络变深时使得模型很难收敛。改善的方法有用预训练的模型去初始化网络的部分层;xavier也是不错的初始化方法,但是它需要满足激活函数线性的条件。在MSRA初始化中,考虑了ReLU和PReLU。
MSRA初始化的权重分布是一个均值为0,均值为n分之2的高斯分布,初始化满足下式:
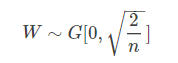
此外,还有均匀分布初始化、高斯分布初始化、稀疏矩阵初始化、Pre-train(例如在bert的基础上精调) 等等
方法6:其他
此外还有一些其他的可以促进优化的方法,这里就不详细说了,大约有以下这些:
- 数据预处理(例如对数据归一化、数据降维度等)
- 集成方法(将多个深度学习的模型综合起来预测,和Adaboost原理一样)
- data argument :数据增强,例如将图片缩放、旋转、翻转、裁剪等操作

















 3130
3130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









